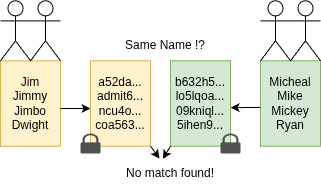
Hash-tag baby
Introduction
Naming a baby can be a difficult task. It can take - soon to be - parents quite some time to align
on a name they both like. Afterwards it can also be challenging to keep the name a secret until
birth.
If you are lucky, there might be ...