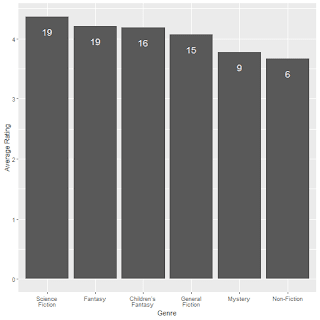
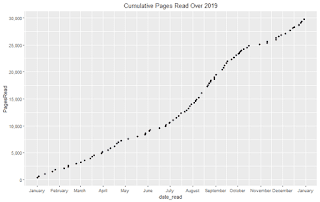
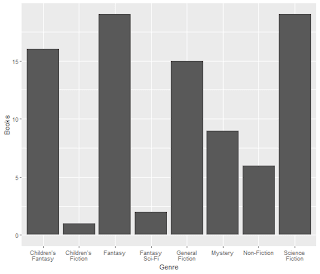
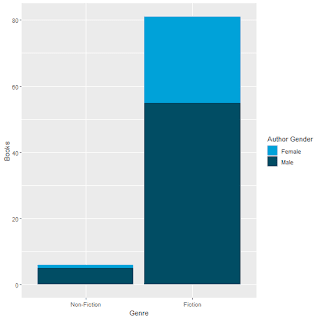
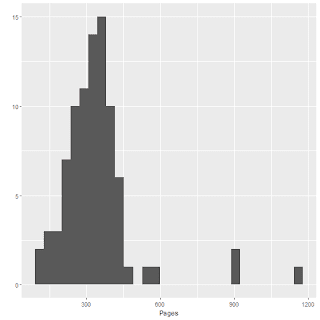
TV Shows on the “Big 3” Streaming Services
2020 has been a tough year, and I've been doing my best to keep busy (and distracted from all the insanity - both at the personal and worldwide levels). Earlier this year, I took a course in machine learning techniques and have been working on applying...