
Why we are all naturally Bayesians not frequentists
Why we are all naturally Bayesians not frequentists
I don’t see why its a thing to say “I’m a Bayesian”. Being a Bayesian is normal for any rational person as we will prove in a couple of sentences. Being a frequentist is what is what is strange. It ... [Read more...]
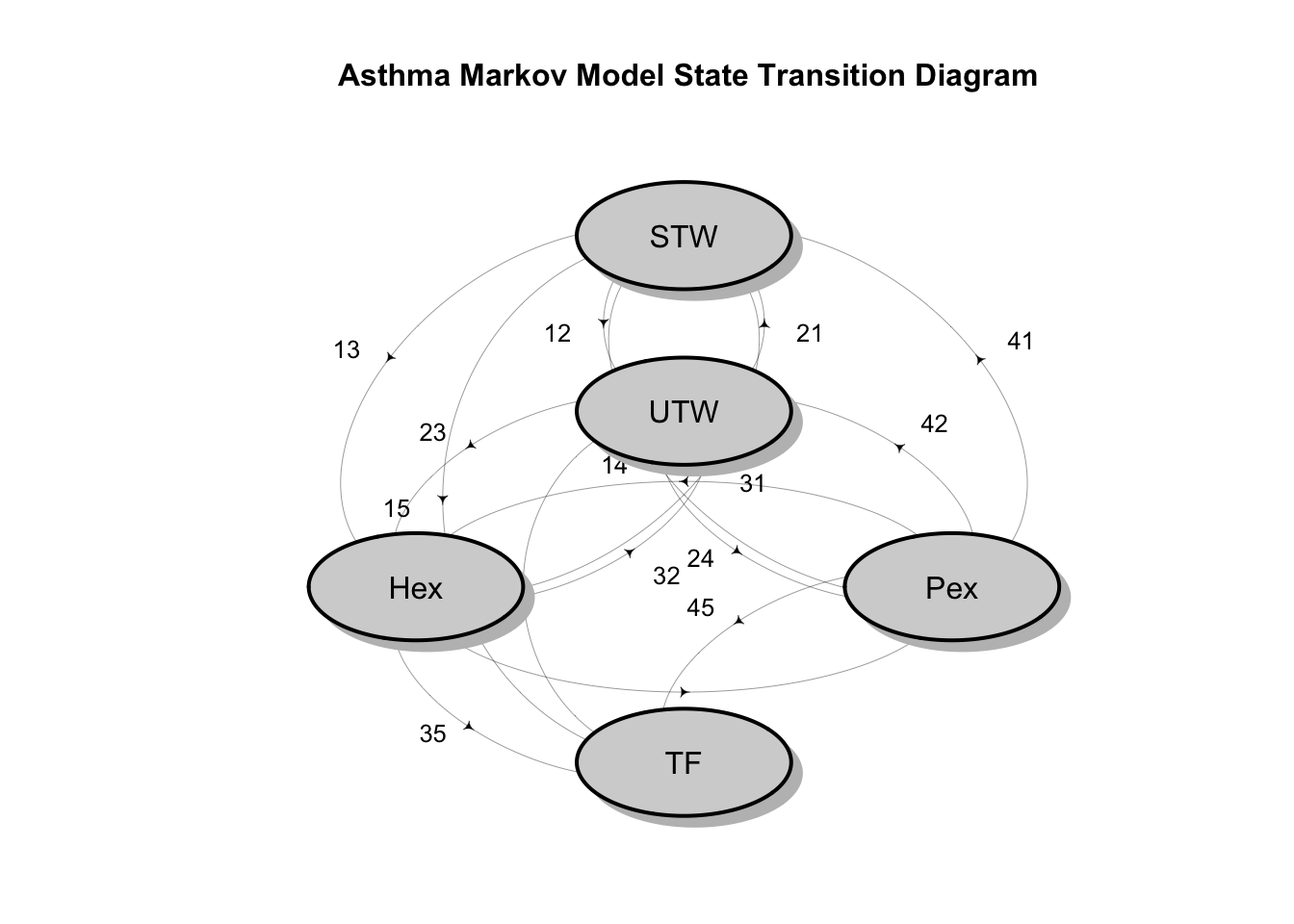
A Simple Bayesian Multi-state Survival Model for a Clinical Trial
This post shows how to use the elementary theory of discrete time Markov Chains to construct a multi-state model of patients progressing through various health states in a randomized clinical trial comparing different treatments for asthma manag...
Announcing New Stats Software Peer Review Editors: Emi Tanaka and Nima Hejazi
We are excited to welcome Emi Tanaka and Nima Hejazi to our team of Associate Editors for rOpenSci Stats Software Peer Review.
They join Laura DeCicco, Julia Gustavsen, Jouni Helske, Toby Hocking, Rebecca Killick, Anna Krystalli, Mauro Lepore, Noam Ro... [Read more...]
Setting Future Plans in R Functions — and Why You Probably Shouldn’t
The future package celebrates ten years on CRAN as of June 19,
2025. This is the second in a series of blog posts highlighting recent
improvements to the futureverse ecosystem.
TL;DR
You can now use
my_fcn
How to open files, folders, websites in R
Coming to you from France, a post about Mise en place for R projects. In a less francophone phrasing: to get to work on something you have to open that thing, be it a script or a project or a website. The easier that is, the faster you get to ... [Read more...]
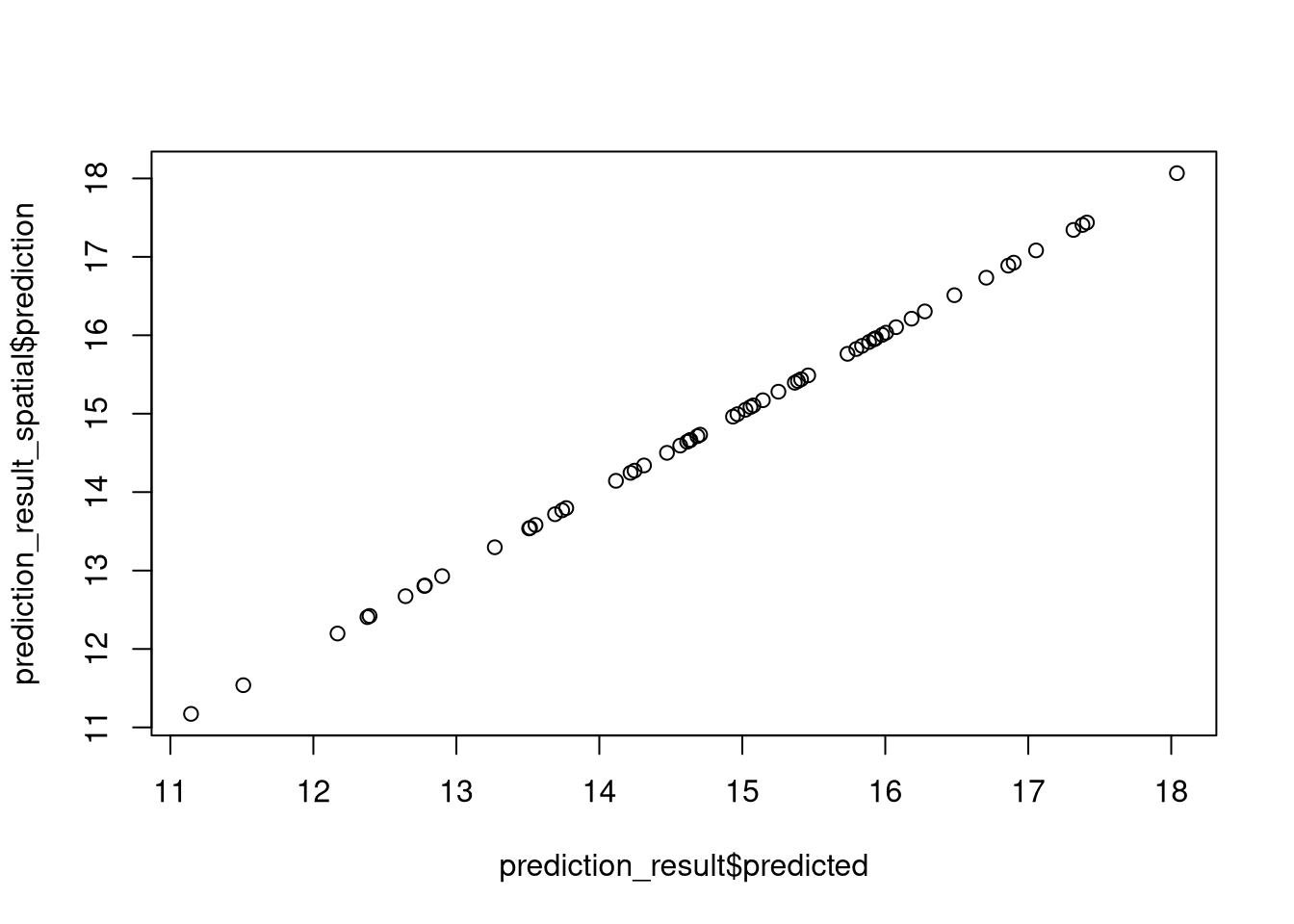
Specialized R packages for spatial machine learning: An introduction to RandomForestsGLS, spatialRF, and meteo
This is the fifth part of a blog post series on spatial machine learning with R.
You can find the list of other blog posts in this series in part one.
This document provides an overview of three R packages, RandomForestsGLS, spatialRF, a...
Shiny in Production 2025: Lightning Talk Lineup
We are pleased to announce the lightning talks for this year’s
Shiny in Production
conference! We’ve already announced the full length talks (25 minutes each) in
this blog. This blog however is all about
this year’s lightning talks session (5 minutes per talk).
Register
now
Lightning talks
Andreas Wolfsbauer ...

Sankey plots can work, but need polishing like any other graphic by @ellis2013nz
So a critical discussion of Sankey plots floated across my feed on Bluesky recently, and one reply included an ugly example and the comment “Anybody who thought that this illustration enhanced clarity lives in an alternative reality”. The actual chart ...

Chat with LLMs on your R environment
LLM provides many advantages to the users, especially for coding. Once user had to switch the windows from the coding environment to the browser to search for the solution. But now, thanks to the newly advancements, users can chat with the LLM and get the solution for their queries on ...
R’da ggplot2 paketi kullanarak Türkiye Haritası Çizdirmek
2018 yılında hazırlamış olduğum R’da ggplot2 ve maps Kutuphanelerini Kullanarak Harita Cizdirmek adlı yazımda, R’da ggplot2 ve maps paketlerini kullanarak harita çizdirmeyi anlatmıştım. Yıllar içinde oldukça fazla bu yazıyla ilgili mailler aldım, ancak aldığım son mailler ...
R version of ‘Backpropagating quasi-randomized neural networks’
Understanding the Link Between Uncertainty and Imports by glmnet
According to the graph below, suggested by Fernando Leibovici, the increase in uncertainty that began in late 2024 aligns with a rise in imports, indicating that US importers accelerated their purchases as a precaution against expected tariff increases or supply chain disruptions. When we model the variables with the glmnet engine, ...

How to draw a pie chart on a map in R with ggplot2 and scatter pie? An example for Turkey
Pie Chart… The unloved boy of visualization family. However, it is getting popularity especially when it is in conjuction with maps. For example, the following chart was publised by to illustrate the vote distribution across the country.
Segmented Total Bar Chart in R with “`ggsegmentedtotalbar“`
Kevin Flerlage, who is a data visualization specialist, suggested a great alternative to stacked bar plot on his blog. He called this new alternative “segmented total bar plot”. This R package ggsegmentedtotalbar implements this idea. The package is built on top of the ggplot2 package, which is a popular data ...
Multilingual Publishing: Frequently Asked Questions
Read it in: Español.Read it in: Français. As we’ve said before, we believe that publishing multilingual resources can lower the barrier to access to knowledge, help democratize access to quality resources and increase the possibilities of contri... [Read more...]
Future got better at finding global variables
The future package celebrates ten years on CRAN as of June 19,
2025. This is the first of a series of blog posts highlighting recent
improvements to the futureverse ecosystem.
The globals package is part of the futureverse and has had two
recent rel...
Ultra-processed food: an AI polling simulation
There’s a little drip drip drip of scare stories about ultra-processed food (UPF) a phrase that I’d never heard until this year. I’m starting to get worried. Is everyone else worried? Well it turns out the Food Standards Agency (FSA) has been ru...
THAMES for mixtures, a reply from the authors
[Here is a reply to my comments on THAMES sent by the first author of the paper, Martin Metodiev. The above replica of the cover of Rivers of London is obviously unrelated with the reply or the original blog, beyond presenting a fantasy map of the Thames!] Thank you for ...

It’s a linear world – approximately; and the "Rule of 72"
You are probably familiar with the "Rule of 72" in investing: if an investment compounds at annual interest rate i, then the number of years for money to double is approximately 72 / i. For example, if an investmen...

Copyright © 2025 | MH Corporate basic by MH Themes