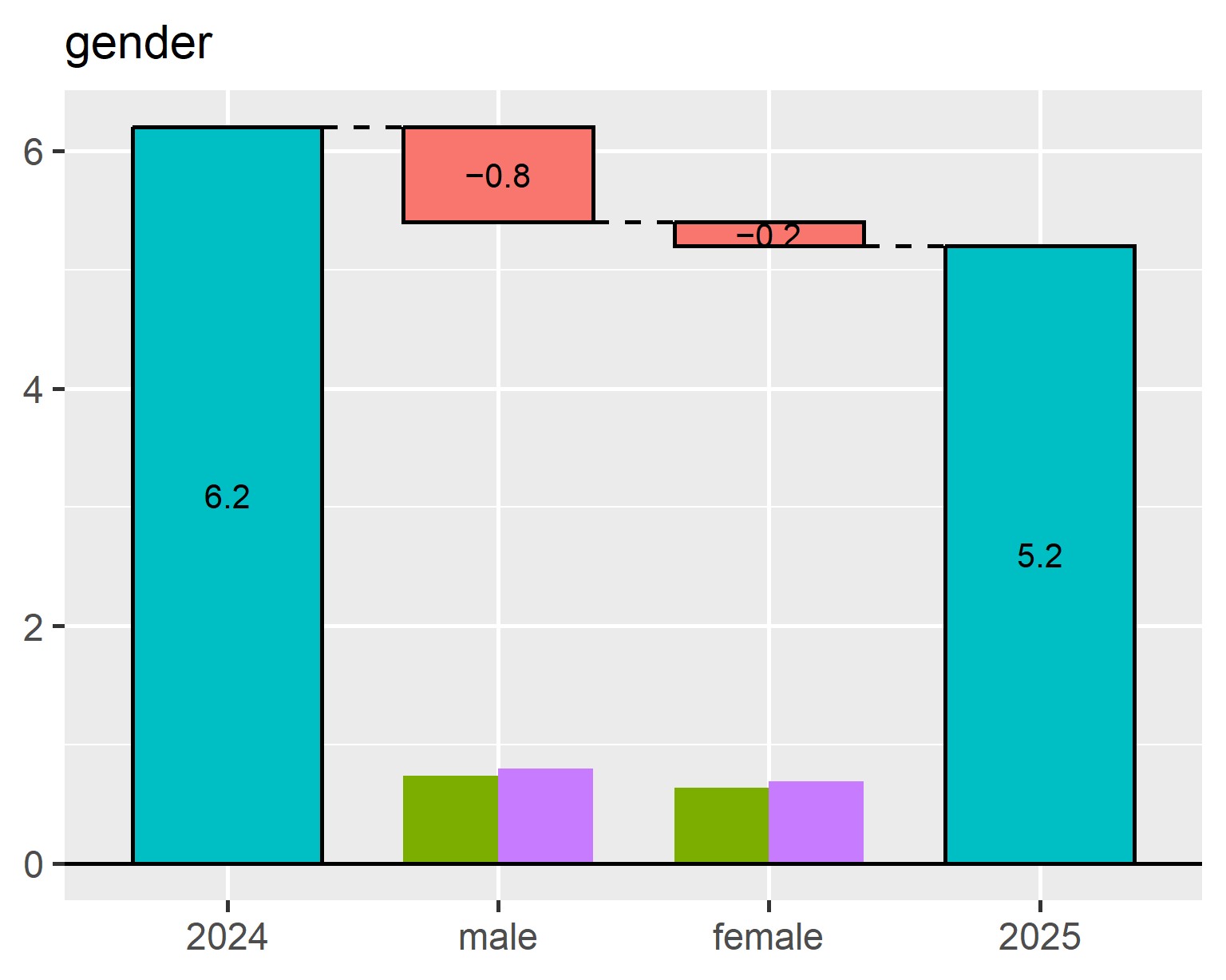
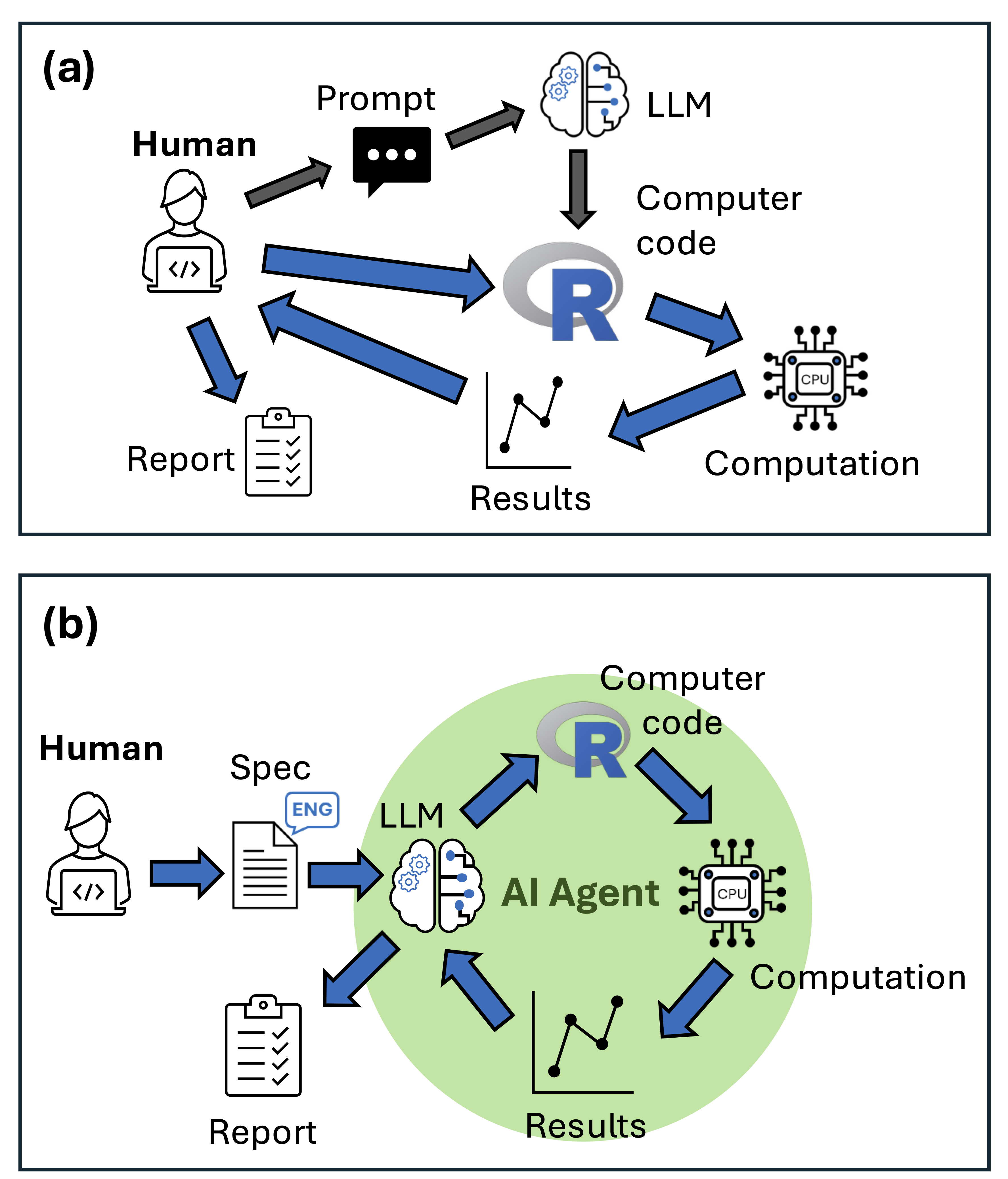
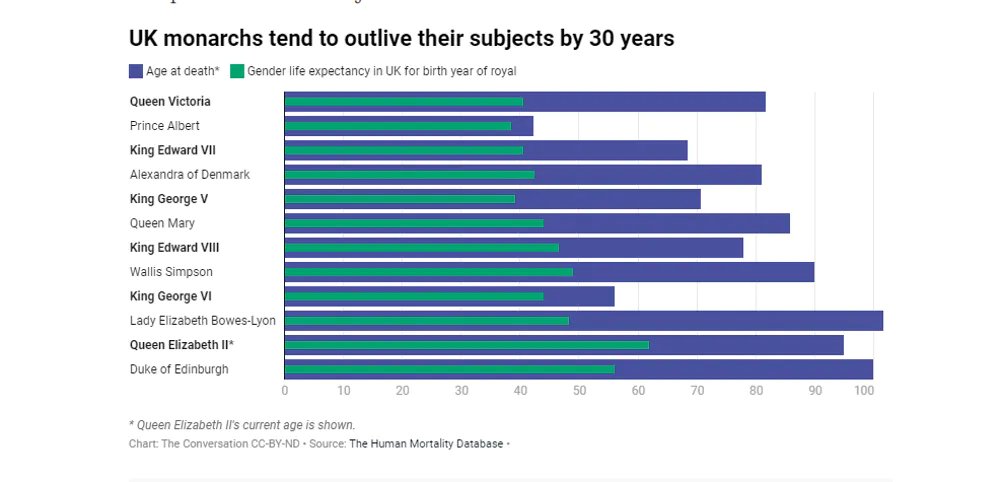
Test & Roll: Why Smaller A/B Tests Can Make More Money
Short practical advice on A/B testing:
Stop sizing tests only for statistical significance - In finite campaigns, your goal is profit, not perfect inference.
Treat testing as a trade-off - Every extra test exposure buys learning but ... [Read more...]