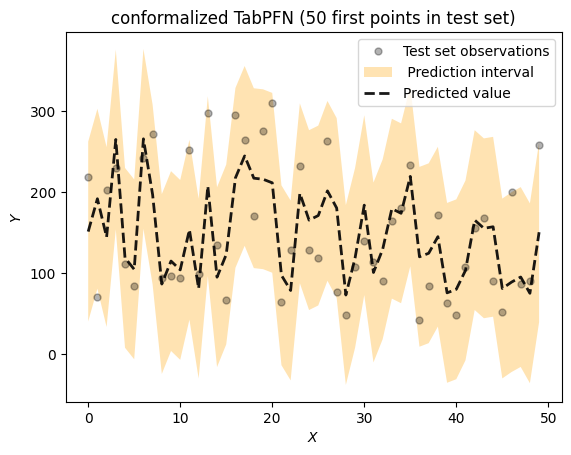
Banh Club Nổ Hũ – Quay Hũ Hấp Dẫn Với Jackpot Khủng
Banh Club nổ hũ là cụm từ thường được tìm kiếm khi người chơi quan tâm đến các game slot có jackpot lớn trên nền tảng Banh Club. Dòng game nổ hũ luôn thu hút ...











Copyright © 2026 | MH Corporate basic by MH Themes