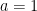Documentation for internal functions
tl;dr: To avoid triple quotes and R CMD CHECK --as-cran errors due to documentation examples for internal functions, enclose the example code in \dontrun{}. I recently encountered an issue when submitting an R package to CRAN that I couldn’t find … Continue reading →