
Estimating pi using the method of moments
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Happy Pi Day! I don’t encounter 
The starting point is the integral identity
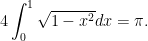
There are two ways to see why this identity is true. The first is that the integral is simply computing the area of a quarter-circle with unit radius. The second is by explicitly evaluating the integral:
![\begin{aligned} \int_0^1 \sqrt{1 - x^2}dx &= \left[ \frac{1}{2} \left( x \sqrt{1 - x^2} + \arcsin x \right) \right]_0^1 \\ &= \frac{1}{2} \left[ \frac{\pi}{2} - 0 \right] \\ &= \frac{\pi}{4}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cint_0%5E1+%5Csqrt%7B1+-+x%5E2%7Ddx+%26%3D+%5Cleft%5B+%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+x+%5Csqrt%7B1+-+x%5E2%7D+%2B+%5Carcsin+x+%5Cright%29+%5Cright%5D_0%5E1+%5C%5C++%26%3D+%5Cfrac%7B1%7D%7B2%7D+%5Cleft%5B+%5Cfrac%7B%5Cpi%7D%7B2%7D+-+0+%5Cright%5D+%5C%5C++%26%3D+%5Cfrac%7B%5Cpi%7D%7B4%7D.+%5Cend%7Baligned%7D&bg=ffffff&%23038;fg=333333&%23038;s=0&%23038;c=20201002)
If ![X \sim \text{Unif}[0,1]](https://s0.wp.com/latex.php?latex=X+%5Csim+%5Ctext%7BUnif%7D%5B0%2C1%5D&bg=ffffff&%23038;fg=333333&%23038;s=0&%23038;c=20201002)
![\begin{aligned} \mathbb{E} \left[ \sqrt{1 - X^2} \right] = \pi. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D+%5Cleft%5B+%5Csqrt%7B1+-+X%5E2%7D+%5Cright%5D+%3D+%5Cpi.+%5Cend%7Baligned%7D&bg=ffffff&%23038;fg=333333&%23038;s=0&%23038;c=20201002)
Hence, if we take i.i.d. draws 
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&%23038;fg=333333&%23038;s=0&%23038;c=20201002)

The code below shows how well this estimation procedure does for one run as the sample size goes from 1 to 200:
set.seed(1)
N <- 200
x <- runif(N)
samples <- 4 * sqrt(1 - x^2)
estimates <- cumsum(samples) / 1:N
plot(1:N, estimates, type = "l",
xlab = "Sample size", ylab = "Estimate of pi",
main = "Estimates of pi vs. sample size")
abline(h = pi, col ="red", lty = 2)

The next plot shows the relative error on the y-axis instead (the red dotted line represents 1% relative error):
rel_error <- abs(estimates - pi) / pi * 100 plot(1:N, rel_error, type = "l", xlab = "Sample size", ylab = "Relative error (%)", main = "Relative error vs. sample size") abline(h = 0) abline(h = 1, col = "red", lty = 2)

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.