
April 2026 Top 40 New CRAN Packages
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Three hundred seventy-six of the new packages submitted to CRAN in April were still there in mid-May. Here are my Top 40 picks in twenty-three categories: Actuarial Analysis, Archaeology, Biology, Causal Inference, Computational Methods, Ecology, Economics, Environmental Studies, Epidemiology, Finance, Functional Data Analysis, Health Technology Assessment, Machine Learning, Medical Statistics, Meta Analysis, Networks, Physics, Programming, Statistics, Time Series, Utilities, and Visualization.
Actuarial Analysis
mqriskR v0.1.0: Provides functions for actuarial risk modeling, including survival models, life annuities, multiple-decrement models, and mortality improvement projections. The package is designed to align with standard actuarial notation and supports teaching, exam preparation, and reproducible actuarial analysis. The methods are based on standard actuarial references, including Camilli, Duncan and London (2014), and Dickson, Hardy and Waters (2020). See the vignette.
Archaeology
palimpsestr v0.10.0: Implements a probabilistic framework for the analysis of archaeological palimpsests based on the Stratigraphic Entanglement Field which integrates spatial proximity, stratigraphic depth, chronological overlap, and cultural similarity to estimate latent depositional phases via diagonal Gaussian mixture Expectation-Maximisation. Includes simulation, diagnostics, phase-count selection, publication-quality plots, and Geographic Information System export via sf. Methods are described in Cocca (2026). See the vignette.

Biology
bsocialv2 v0.2.1: Provides an S4 class and methods for analyzing microbial social behavior in bacterial consortia. Includes growth parameter extraction, social behavior classification (cooperators/cheaters/neutrals), diversity effect analysis, consortium assembly path finding, and stability analysis via coefficient of variation. Methods are described in Purswani et al. (2017). See the vignette.

Causal Inference
CausalMixGPD v0.8.0: Implements tools for Bayesian analysis of heavy-tailed outcomes by combining Dirichlet process mixture models for the body of the distribution with optional generalized Pareto tails. The method allows for unconditional and covariate-modulated mixtures, implements MCMC estimation using nimble, and extends to mixtures of different arms’ outcomes with application to causal inference in the Rubin (1974) framework. There are three vignettes, including an Introduction and One-Arm Regression Modeling.

Computational Methods
nmfkc v0.7.3: Provides functions to perform non-negative matrix factorization with kernel covariates. Given an observation matrix and kernel covariates, it optimizes both a basis matrix and a parameter matrix. Also provides NMF with random effects, which estimates a mixed-effects model combining covariate-driven scores with unit-specific random effects together with wild bootstrap inference, and NMF-based structural equation modeling. See Satoh (2025) and Satoh (2026) for background. There are six vignettes, including Introduction and Topic Modeling.

symbolicr v1.0.0: Provides functions to find non-linear formulas that fit input data. Users can systematically explore and memorize the possible formulas and their cross-validation performance, in an incremental fashion. Three main interoperable search functions are available: 1) random.search() performs a random exploration, 2) genetic.search() employs a genetic optimization algorithm, 3) comb.search() combines the best results of the first two. For more details, see Tomasoni et al. (2026). There are three vignettes, including get-started and formula-analysis.
Ecology
CharAnalysis v2.0.3: Implements a program for reconstructing local fire histories from high-resolution, continuously sampled lake-sediment charcoal records. Functions decompose a charcoal record into low- and high-frequency components and use locally defined thresholds to separate fire signal from noise. See Higuera et al. (2009) and Higuera et al. (2010) for background and the vignette to get started.
 SQIpro v0.1.0: Provides a comprehensive, modular framework for computing the Soil Quality Index (SQI) using six established methods: Linear Scoring Doran and Parkin, (1994). Regression-based Masto et al. (2008), Principal Component Analysis Andrews et al. (2004), Fuzzy Logic, Entropy Weighting, TOPSIS Hwang and Yoon (1981). See the vignette.
SQIpro v0.1.0: Provides a comprehensive, modular framework for computing the Soil Quality Index (SQI) using six established methods: Linear Scoring Doran and Parkin, (1994). Regression-based Masto et al. (2008), Principal Component Analysis Andrews et al. (2004), Fuzzy Logic, Entropy Weighting, TOPSIS Hwang and Yoon (1981). See the vignette.

Economics
rescomp v1.0.0: Provides functions to generate, simulate, and visualize ODE models of consumer-resource interactions and competition modeling. There is an Introduction and a vignette reproducing classic results.

Environmental Studies
gleam v0.8.0: This official implementation of the Global Livestock Environmental Assessment Model of the Food and Agriculture Organization of the United Nations (GLEAM) provides a modular, transparent framework for simulating livestock production systems and quantifying their environmental impacts. See MacLeod et al. (2017) for background. There are four vignettes, including an Overview and Package Modules.

Epidemiology
lineagefreq v0.2.0: Provides functions to model pathogen lineage frequency dynamics from genomic surveillance count data. Includes a unified interface for multinomial logistic regression, hierarchical partial-pooling models, the Piantham approximation for relative reproduction number estimation, and features such as rolling-origin backtesting, standardized forecast scoring. See Abousamra, Figgins, and Bedford (2024) for background. There are four vignettes, including Getting Started and Analyzing real CDC surveillance data.

seroreconstruct v1.1.5: Implements a Bayesian framework for inferring influenza infection status from serial antibody measurements. Jointly estimates season-specific infection probabilities, antibody boosting and waning after infection, and baseline hemagglutination inhibition titer distributions. Supports multi-season analysis and subgroup comparisons via a group_by interface. See Tsang et al. (2022) for methodological details and the two vignettes Getting Started and Statistical Methodology.

Finance
finlabR v1.0.0: Provides tools for portfolio construction and risk analytics, including mean-variance optimization, conditional value at risk minimization, risk parity, regime clustering, correlation analysis, Monte Carlo simulation, and option pricing. Includes utilities for portfolio evaluation, clustering, and risk reporting. Methods are based in part on Markowitz (1952), Rockafellar and Uryasev (2000), Maillard et al. (2010), Black and Scholes (1973), and Cox et al. (1979). See the vignettes Portfolio Analytics and Simulation and End-to-End Workflow

talib v0.9-2: Implements an interface to the TA-Lib (Technical Analysis Library) C library, providing access to 150+ indicators (e.g. Average Directional Movement Index (ADX), Moving Average Convergence Divergence (MACD), Relative Strength Index (RSI), Stochastic Oscillator, Bollinger Bands), candlestick pattern recognition, and rolling-window utilities. Core computations are implemented in C for fast Open-High-Low-Close-Volume time-series feature engineering and rule-based signal generation. There are three vignettes, including Candlestick Pattern Recognition and Financial Charts.

Functional Data Analysis
refundBayes v0.6.0: Provides tools to perform Bayesian regression with functional data, including regression with scalar, survival, or functional outcomes. The package allows regression with scalar and functional predictors. Methods are described in Jiang et al. (2025) Tutorial on Bayesian Functional Regression Using Stan. There are six vignettes, including Bayesian Function-on-Function Regression and Bayesian Functional Principal Component Analysis (FPCA).

tidyfun v0.1.2: Builds on the tf package to provide functions to represent, visualize, describe and wrangle functional data in tidy data frames as well as data types for functional observations that work as columns in data frames, enabling manipulation with dplyr verbs and visualization with ggplot2 geoms designed for functional data. There are six vignettes, including tf Vectors and Operations and Visualization.

Genomics
AbSolution v1.0.1: Implements an interactive framework as a Shiny Application for the exploration and analysis of adaptive immune receptor repertoire sequencing data in a manner that facilitates reproducible research. It enables large-scale computation and integrated analysis of sequence-derived features, including physicochemical properties, amino acid descriptor sets, sequence motifs, compositional patterns, and somatic hypermutation metrics. See the GitHub Repository and the vignette for more details.

IOBR v2.2.2: Provides six modules for tumor microenvironment (TME) analysis based on multi-omics data. These modules cover data preprocessing, TME estimation, TME infiltrating patterns, cellular interactions, genome and TME interaction, and visualization for TME-relevant features, as well as modelling based on key features. In addition to providing a way to construct gene signatures from single-cell RNA-seq data, it also provides a way to construct a reference matrix for TME deconvolution from single-cell RNA-seq data. See Zeng et al. (2024) and Fang et al. (2025) for background and the vignette for a detailed tutorial.

Health Technology Assessment
htaBIM v0.1.0: Implements a structured, reproducible framework, a Shiny Application, for budget impact modelling in health technology assessment (HTA), following the ISPOR Task Force guidelines (Sullivan et al. (2014) and Mauskopf et al. (2007) that provides functions for epidemiology-driven population estimation, market share modelling with flexible uptake dynamics, per-patient cost calculation across multiple cost categories, multi-year budget projections, payer perspective analysis, deterministic sensitivity analysis, and probabilistic sensitivity analysis. Produces submission-quality outputs including ISPOR-aligned summary tables, scenario comparison tables, per-patient cost breakdowns, tornado diagrams, PSA histograms, and text and HTML reports compatible with NICE, CADTH, and EU-HTA dossier formats. See the vignettes Introduction and Interactive Shiny Dashboard.

Machine Learning
AntsNet v1.0.0: Implements the full suite of simulation, visualization, and analysis tools for exploring the mathematical isomorphisms between ant colony decision-making and three major paradigms of machine learning: random forests (Part I: variance reduction through decorrelation), boosting (Part II: bias reduction through adaptive recruitment), and neural networks (Part III: gradient-based generational learning). See Fokoué, Babbitt, and Levental (2026) Part I and Part II for background and README to get started.
bigKNN v0.3.0: Implements exact nearest-neighbour and radius-search routines that operate directly on bigmemory::big.matrix objects. Functions stream row blocks through BLAS kernels, support self-search and external-query search, expose prepared references for repeated queries, and can build exact k-nearest-neighbour, radius, mutual k-nearest-neighbour, and shared-nearest-neighbour graphs. There are seven vignettes, including Quick Start and Using bigKNN as Exact Ground Truth.
Medical Statistics
BayesianQDM v0.1.0: Provides comprehensive methods to calculate posterior probabilities, posterior predictive probabilities, and Go/NoGo/Gray decision probabilities for quantitative decision-making under a Bayesian paradigm in clinical trials. Supports both single and two-endpoint analyses for binary and continuous outcomes, with controlled, uncontrolled, and external designs. External designs incorporate historical data through power priors using exact conjugate representations to significantly reduce computational burden while preserving complete Bayesian rigor. See Kang, Yamaguchi, and Han (2026) for the methodological framework. There are five vignettes, including Overview and Two Continuous Endpoints.

raretrans v1.0.5: Provides functions to correct biased transition and fertility estimates in population projection matrices caused by small sample sizes, never observed biologically possible transmissions, or transitions estimated at 100% survival, stasis, or mortality that are biologically implausible. Implements a multinomial-Dirichlet Bayesian prior for transition probabilities and a Gamma-Poisson prior for reproduction, allowing analysts to incorporate prior biological knowledge and regularise estimates from rare or unobserved events. Methods are described in Tremblay et al. (2021). There are six vignettes, including both a Quick start and an Introduction.

Meta Analysis
confMeta v0.1.0: Provides tools for the combination of individual study results in meta-analyses using p-value functions. Implements various combination methods, including those by Fisher, Stouffer, Tippett, Edgington, along with weighted generalizations. Contains functionality for the visualization and calculation of confidence curves and drapery plots to summarize evidence across studies. See the vignette.

drmeta v0.1.0: Implements a variance-function random-effects framework in which between-study heterogeneity is modeled as a function of a study-level design robustness index, allowing heterogeneity to depend systematically on study quality or design strength rather than being treated as a single nuisance parameter. The framework nests classical fixed-effects and standard random-effects meta-analysis as special cases, making it a strict generalization of existing approaches. See the Getting Started Guide.

Networks
sparsecommunity v0.1.1: Implements spectral clustering algorithms for community detection in sparse networks under the stochastic block model and degree-corrected stochastic block model following the methods of Lei and Rinaldo (2015). Provides a regularized normalized Laplacian embedding, spherical k-median clustering, simulation utilities, and a misclustering rate evaluation metric along with the NCAA college football network of Girvan and Newman (2002) as a benchmark dataset, and the Bethe-Hessian community number estimator of Hwang (2023). See the vignette.

Physics
orbitr v0.3.0: Provides a lightweight, fully vectorized N-body physics engine built for the R ecosystem. Simulate and visualize complex orbital mechanics, celestial trajectories, and gravitational interactions using tidy data principles. Features multiple numerical integration methods, including the energy-conserving velocity Verlet algorithm Verlet (1967) to ensure highly stable orbital propagation. Gravitational N-body methods follow Aarseth (2003). There are twelve vignettes, including Quick Start Guide and The Physics.

Programming
mori v0.2.0: Enables users to share R objects across processes on the same machine via a single copy in POSIX shared memory (Linux, macOS) or a Win32 file mapping (Windows). Every process reads from the same physical pages through the R Alternative Representation (ALTREP) framework, giving lazy, zero-copy access. Shared objects serialize compactly as their shared memory name rather than their full contents. See README to get started.
progressify v0.1.0: The `progressify() function rewrites (transpiles) calls to sequential and parallel map-reduce functions such as base::lapply(), purrr::map(), foreach::foreach(), and plyr::llply() to signal progress updates. By combining this function with R’s native pipe operator, you have a straightforward way to report progress on iterative computations with minimal refactoring, e.g., lapply(x, fcn) |> progressify() and purrr::map(x, fcn) |> progressify(). It is compatible with the futurize package for parallelization, e.g. lapply(x, fcn) |> progressify() |> futurize() and purrr::map(x, fcn) |> futurize() |> progressify(). There are nine brief vignettes, including Progress updates for base-R apply functions and Progress updates for ‘purrr’ functions.
shard v0.1.1: Provides a parallel execution runtime for R that emphasizes deterministic memory behavior and efficient handling of large shared inputs, which enables zero-copy parallel reads via shared, memory-mapped segments, encourages explicit output buffers to avoid large result aggregation, and supervises worker processes to mitigate memory drift via controlled recycling. Diagnostics report peak memory usage, end-of-run memory return, and hidden copy/materialization events to support reproducible performance benchmarking. See the vignette to get started.
Statistics
balnet v0.0.3: Provides pathwise estimation of regularized logistic propensity score models using covariate balancing loss functions rather than maximum likelihood. Regularization paths are fit via the adelie elastic-net solver with a glmnet-like interface, yielding balancing weights that target covariate balance for the ATE and ATT. Under lasso penalization, lambda bounds the maximum covariate imbalance, so the regularization path traces a sequence of decreasing imbalance tolerances. See Sverdrup & Hastie (2026) for details and the vignette for an introduction.

ngme2 v0.9.8: Functions to fit and analyze linear latent non-Gaussian models for temporal, spatial, and space-time data, including autoregressive and Ornstein-Uhlenbeck processes, random walks, Matern fields based on stochastic partial differential equations, separable and non-separable space-time models, graph-based Matern models, bivariate type-G fields, and user-defined sparse operators. Latent fields and observation models can use Gaussian and non-Gaussian noise distributions. The modeling framework is described in Bolin et al. (2026). See the vignette for exceptionally well-done documentation.

nowcastr v0.2.0: Implements tools for performing nowcasting using the Chain-Ladder method, and supports both non-cumulative delay-based estimation and model-based completeness fitting (e.g., using logistic or Gompertz curves) to predict final counts from partially reported data. See the vignettes Getting Started and Evaluate Past Nowcasts Accuracy.

TwoStepSDFM v0.2.2: Provides functions to estimate a sparse Gaussian state-space model with mixed frequency data via sparse principal components analysis and the Kalman filter and smoother. For more details, see Franjic and Schweikert (2024). The vignette provides an introduction.
Time Series
MatchingPursuit v1.0.1: Provides tools for analyzing and decomposing time series data using the Matching Pursuit algorithm, a greedy signal decomposition technique that represents complex signals as a linear combination of simpler functions (called atoms) selected from a redundant dictionary. For more details, see Mallat and Zhang (1993), Pati et al. (1993), Elad (2010), and Różański (2024). See the vignette.

xiacf v0.5.0: Computes Chatterjee’s non-parametric correlation coefficient for time series data. It extends the original metric to time series analysis by providing the Xi-Autocorrelation Function and Xi-Cross-Correlation Function. Allows users to test for non-linear dependence using Iterative Amplitude Adjusted Fourier Transform surrogate data with strict Family-Wise Error Rate control via Max-statistic approaches. Methodologies are based on Chatterjee (2021) and surrogate data testing methods by Schreiber and Schmitz (1996). See README for examples.

Utilities
abba v0.2.0: Enables users to submit and monitor batch execution of R programs across distributed computing backends, including Kubernetes, SLURM, and Posit Workbench. Provides end-user job submission functions, cluster interface functions using kubectl and SLURM commands, and a plumber API template for secure identity segregation. Supports parallel and sequential batch execution, file-based caching to skip unchanged programs, and logrx integration for execution logging. There are seven vignettes, including Kubernetes Batch Jobs and SLURM Job Submission.
vectra v0.6.2: Implements a minimal columnar query engine with lazy execution on datasets larger than RAM. Provides dplyr-like verbs (filter(), select(), mutate(), group_by(), summarise(), joins, window functions) and common aggregations (n(), sum(), mean(), min(), max(), sd(), first(),last()) backed by a pure C11 pull-based execution engine and a custom on-disk format (.vtr). Reads and writes GeoTIFF (including tiled and BigTIFF layouts) and a tiled raster format (.vec) with overview pyramids and time cubes for larger-than-RAM raster data. There are eight vignettes, including Getting Started and String Operations and Fuzzy Matching.
Visualization
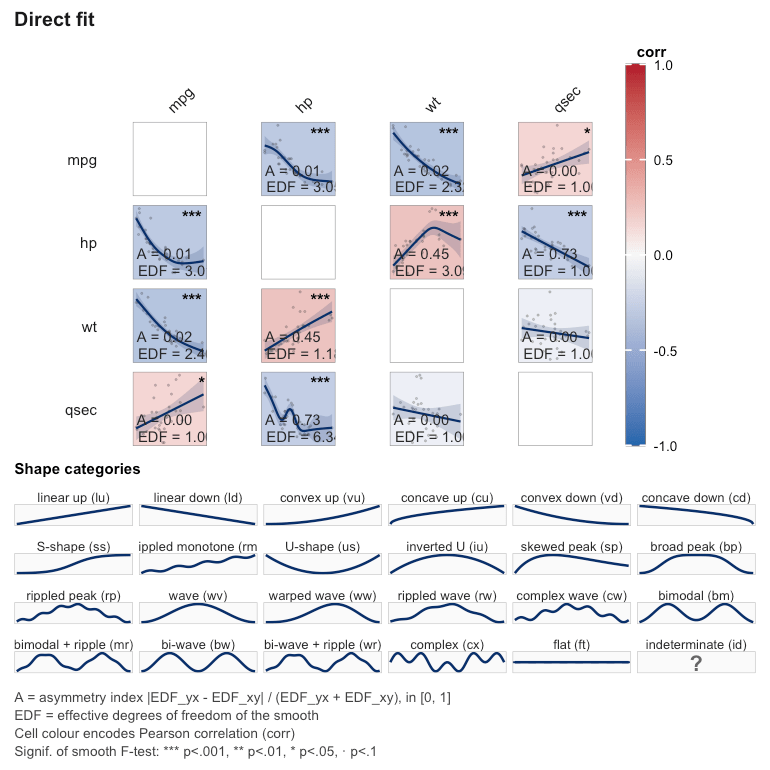
janusplot v0.1.0: Provides functions to render a pairwise, asymmetric smoothed-association matrix of continuous variables. Each cell shows the fitted spline from an mgcv generalized additive model, with the upper triangle displaying gam(x_j ~ s(x_i)) and the lower triangle gam(x_i ~ s(x_j)). Unlike Pearson’s correlation matrix, the visualization is intentionally asymmetric, revealing heteroscedasticity, leverage, and directional non-linearity that a single scalar correlation hides. An asymmetry index and a 24-category shape taxonomy quantify the directional difference and qualitative form of each fitted smooth. There are two vignettes, Asymmetric Smoothed-Association Matrices and Shape-recognition sensitivity study.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.