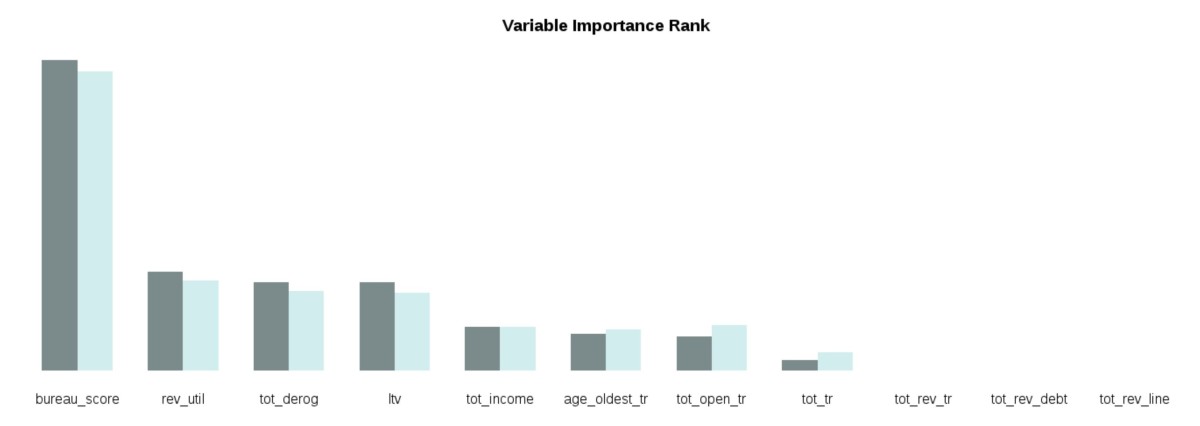
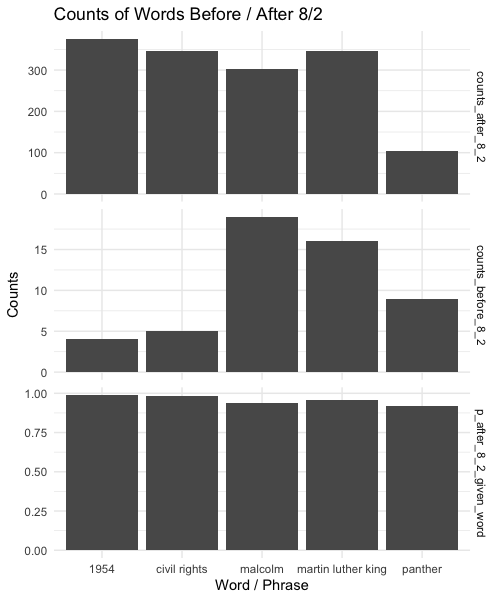
Automatic data types checking in predictive models
Given certain data, and we need to create models (xgboost, random forest, regression, etc). Each one of them has its constraints regarding data types.
Errors are not clear, here's a new function to speed up model creation.