
Assess Variable Importance In GRNN
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Technically speaking, there is no need to evaluate the variable importance and to perform the variable selection in the training of a GRNN. It’s also been a consensus that the neural network is a black-box model and it is not an easy task to assess the variable importance in a neural network. However, from the practical prospect, it is helpful to understand the individual contribution of each predictor to the overall goodness-of-fit of a GRNN. For instance, the variable importance can help us make up a beautiful business story to decorate our model. In addition, dropping variables with trivial contributions also helps us come up with a more parsimonious model as well as improve the computational efficiency.
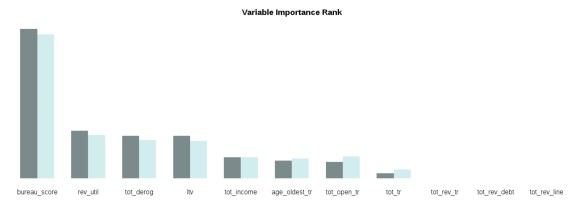
In the YAGeR project (https://github.com/statcompute/yager), two functions have been added with the purpose to assess the variable importance in a GRNN. While the grnn.x_imp() function (https://github.com/statcompute/yager/blob/master/code/grnn.x_imp.R) will provide the importance assessment of a single variable, the grnn.imp() function (https://github.com/statcompute/yager/blob/master/code/grnn.imp.R) can give us a full picture of the variable importance for all variables in the GRNN. The returned value “imp1” is calculated as the decrease in AUC with all values for the variable of interest equal to its mean and the “imp2” is calculated as the decrease in AUC with the variable of interest dropped completely. The variable with a higher value of the decrease in AUC is deemed more important.
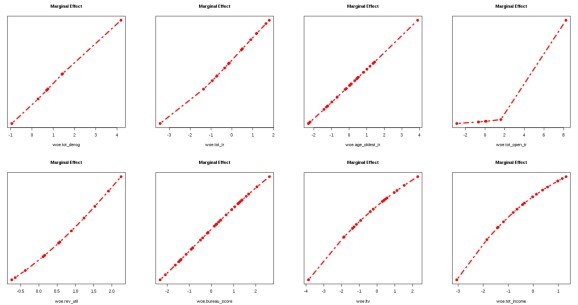
Below is an example demonstrating how to assess the variable importance in a GRNN. As shown in the output, there are three variables making no contribution to AUC statistic. It is also noted that dropping three unimportant variables in the GRNN can actually increase AUC in the hold-out sample. What’s more, marginal effects of variables remaining in the GRNN make more sense now with all showing nice monotonic relationships, in particular “tot_open_tr”.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.