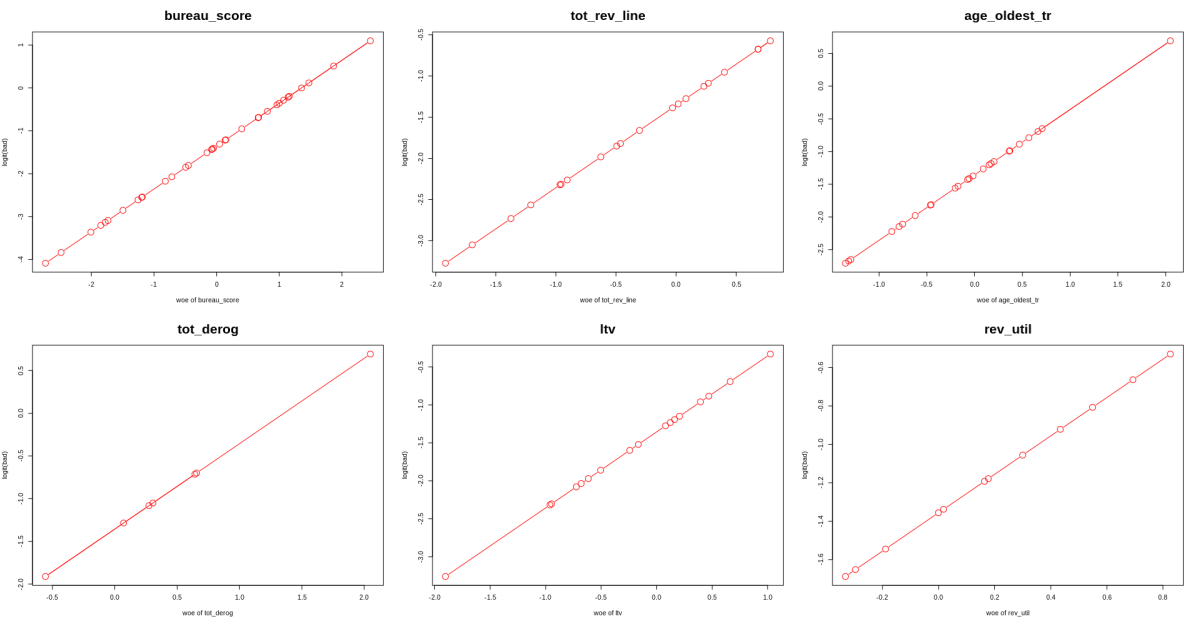
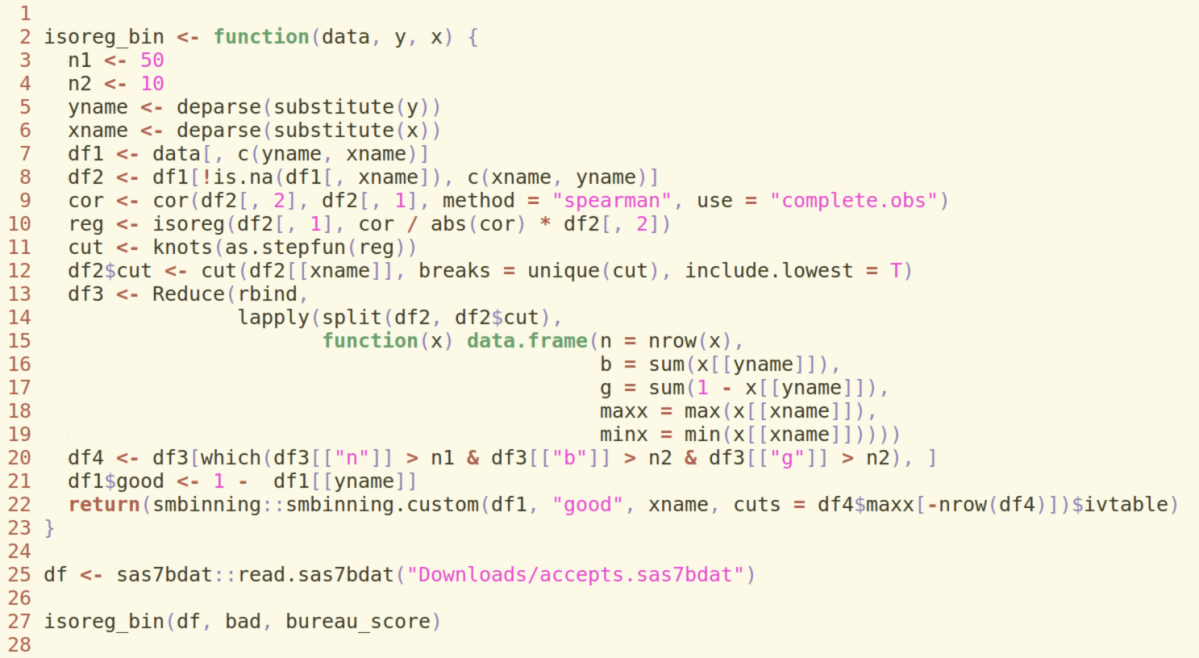
Why Use Weight of Evidence?
I had been asked why I spent so much effort on developing SAS macros and R functions to do monotonic binning for the WoE transformation, given the availability of other cutting-edge data mining algorithms that will automatically generate the prediction with whatever predictors fed in the model. Nonetheless, what really ...