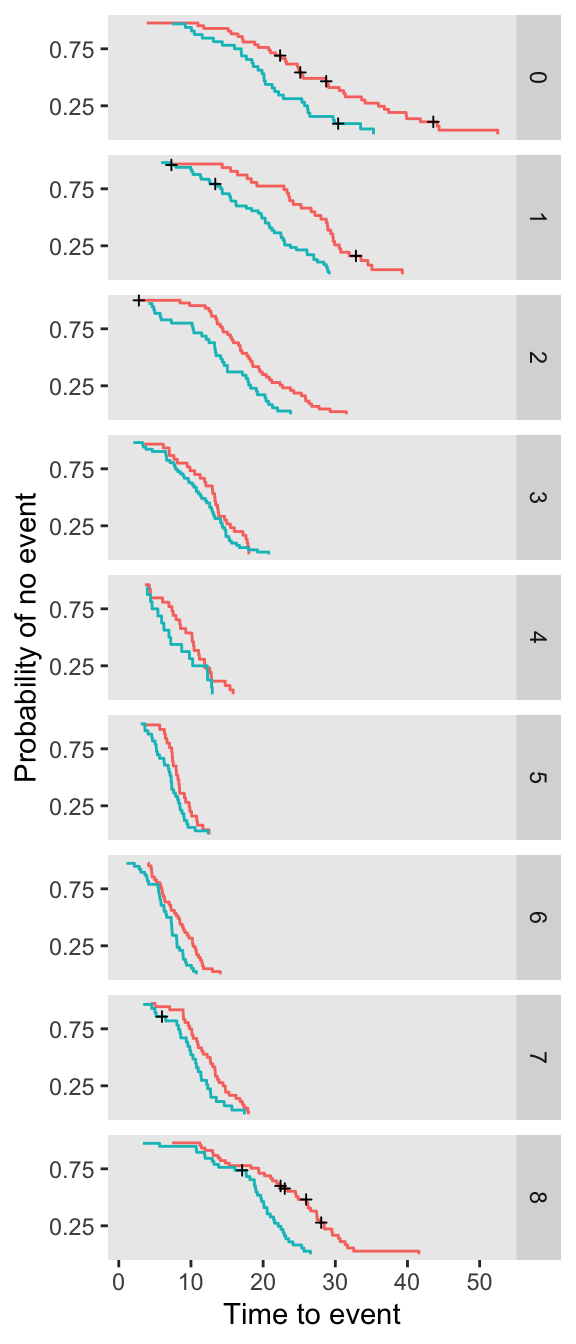
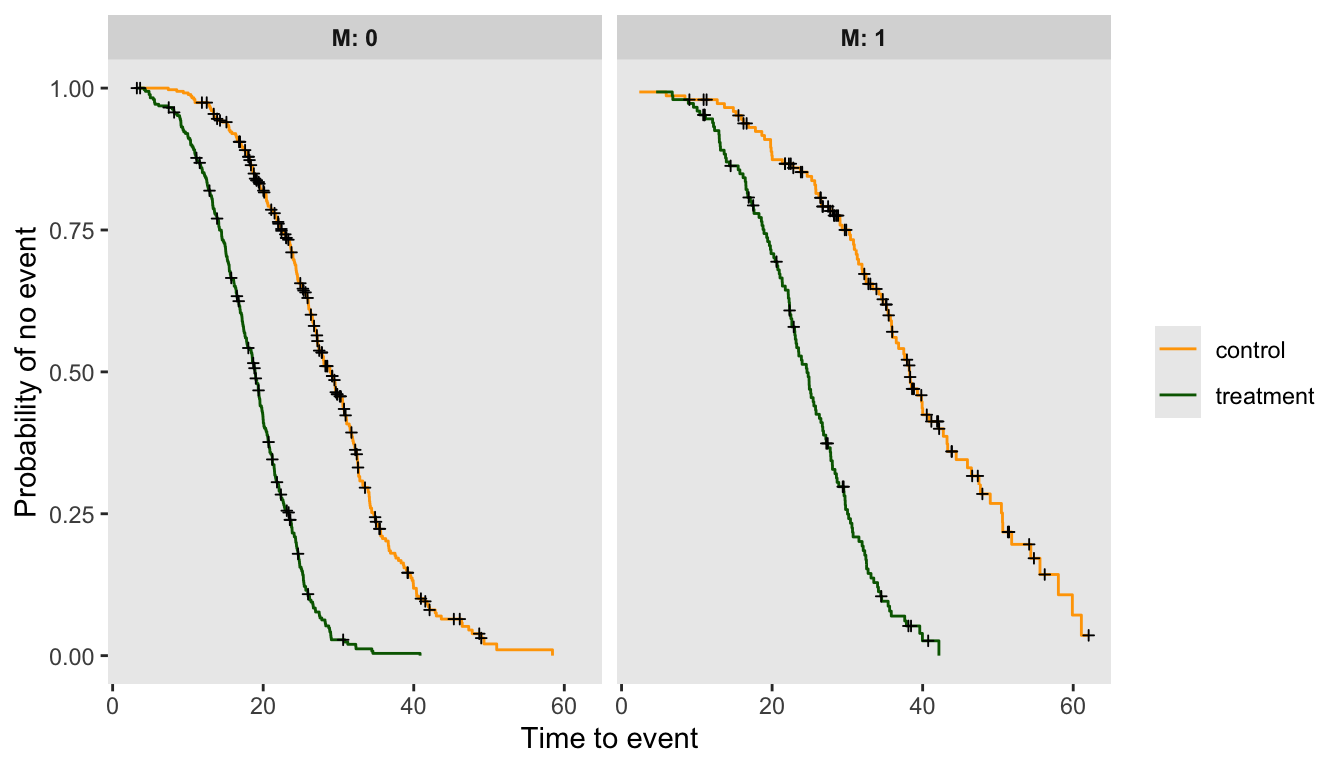
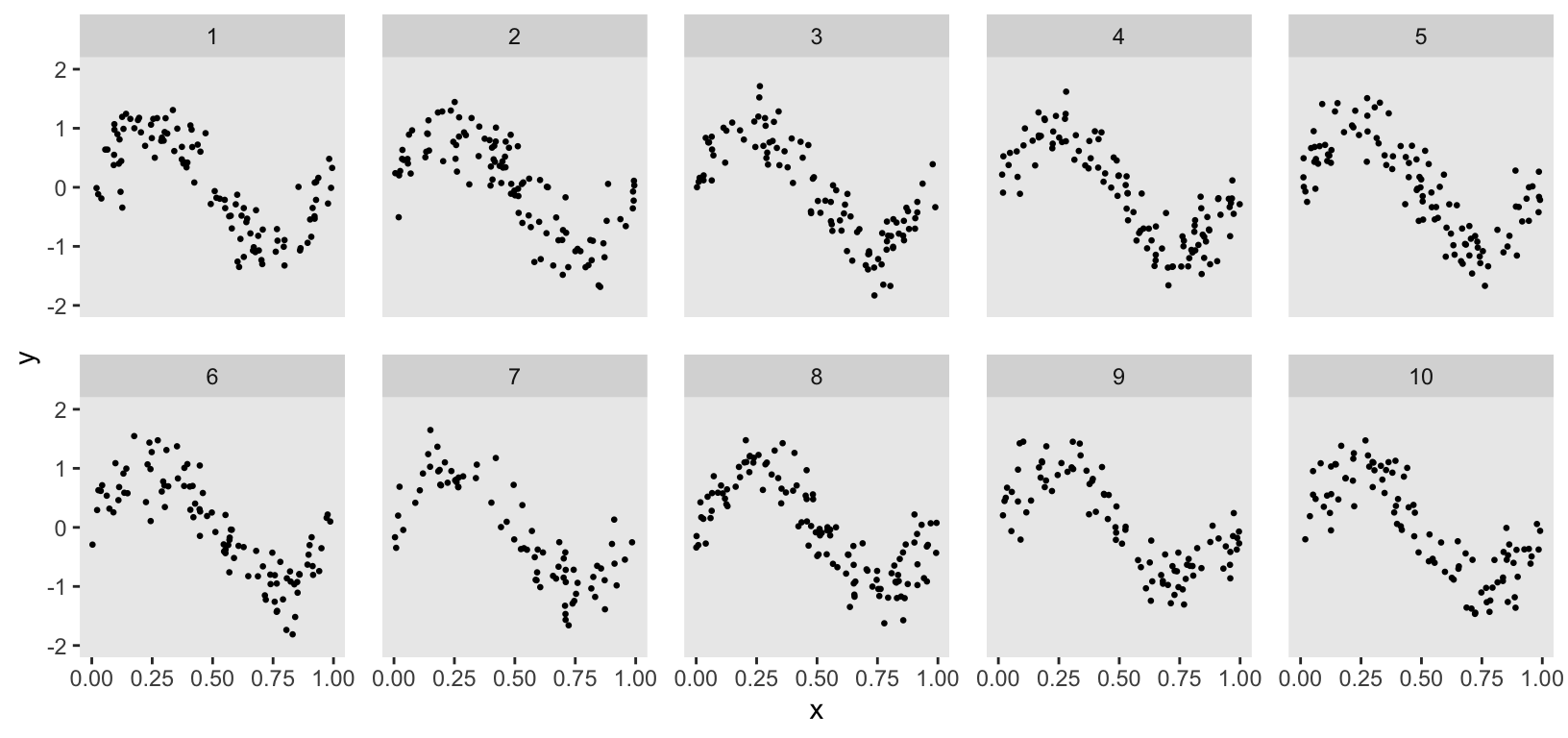
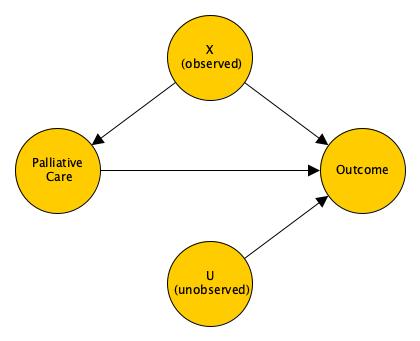
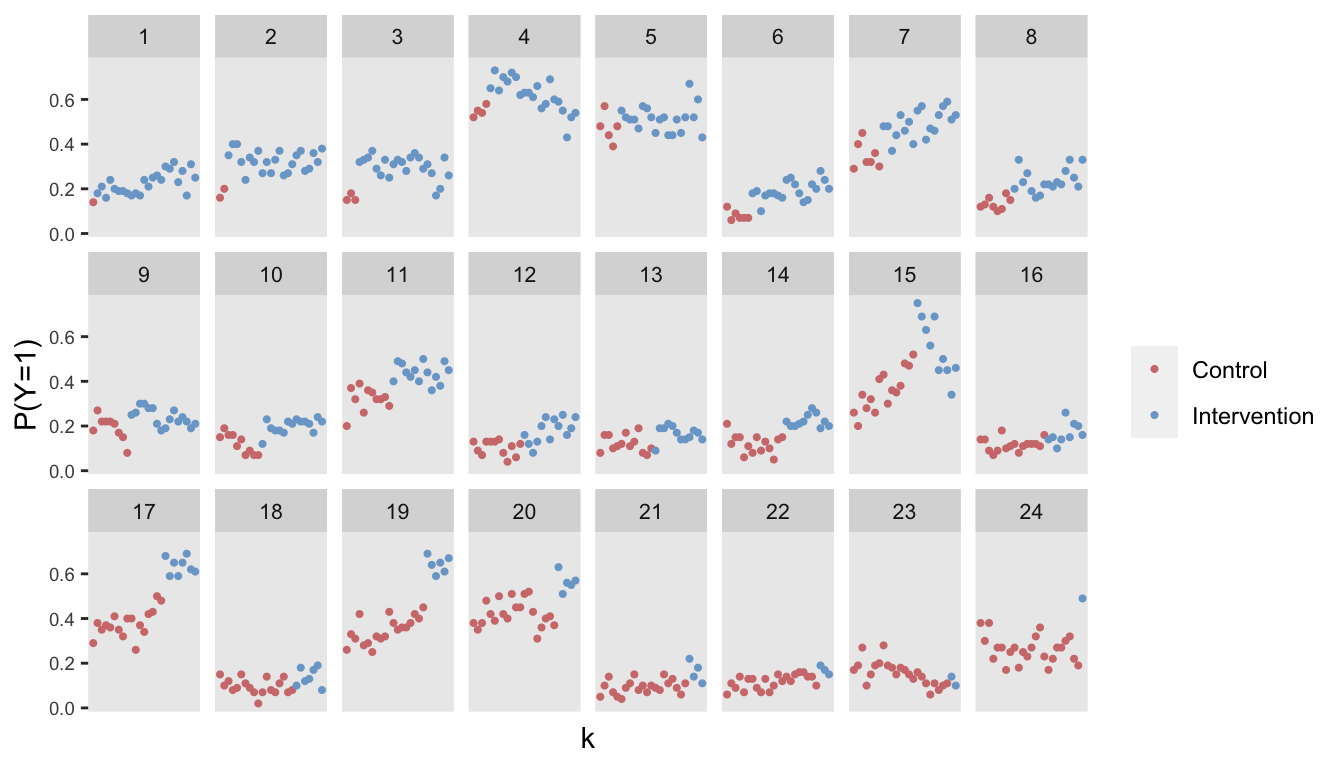
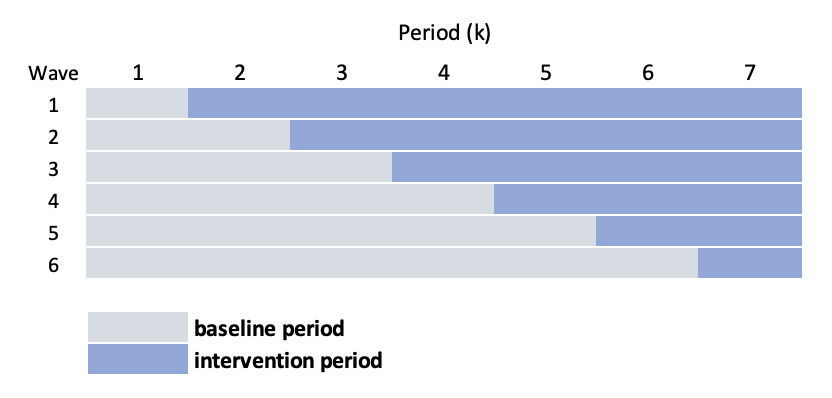
A Bayesian proportional hazards model with a penalized spline
In my previous post, I outlined a Bayesian approach to proportional hazards modeling. This post serves as an addendum, providing code to incorporate a spline to model a time-varying hazard ratio non linearly. In a second addendum to come I will pres...