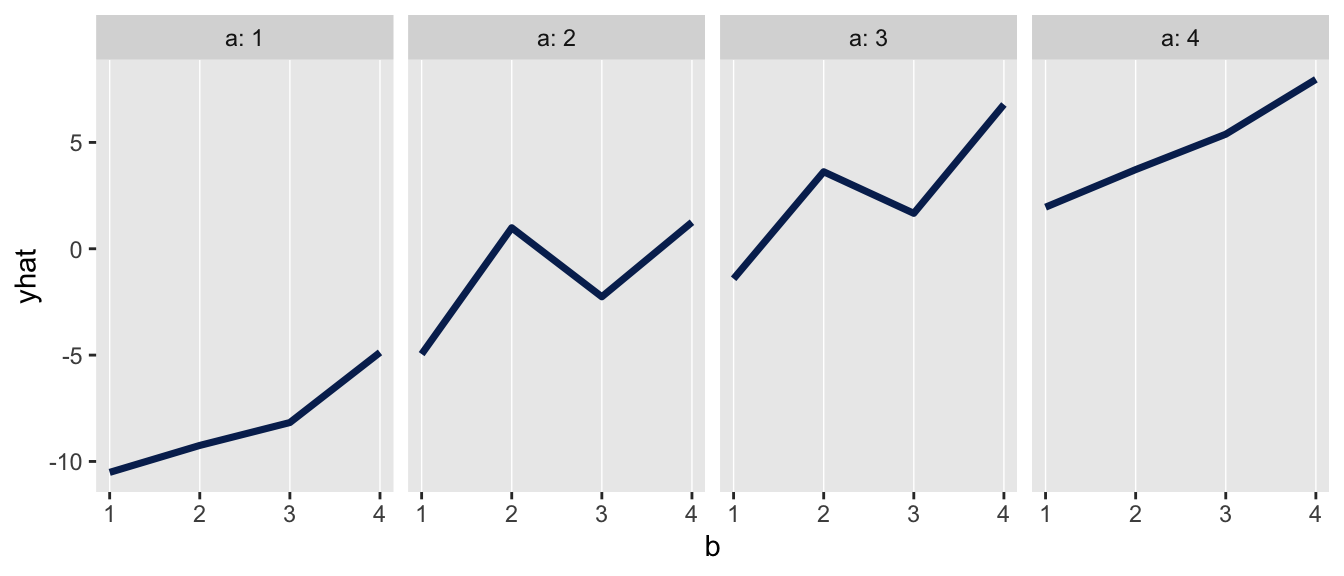
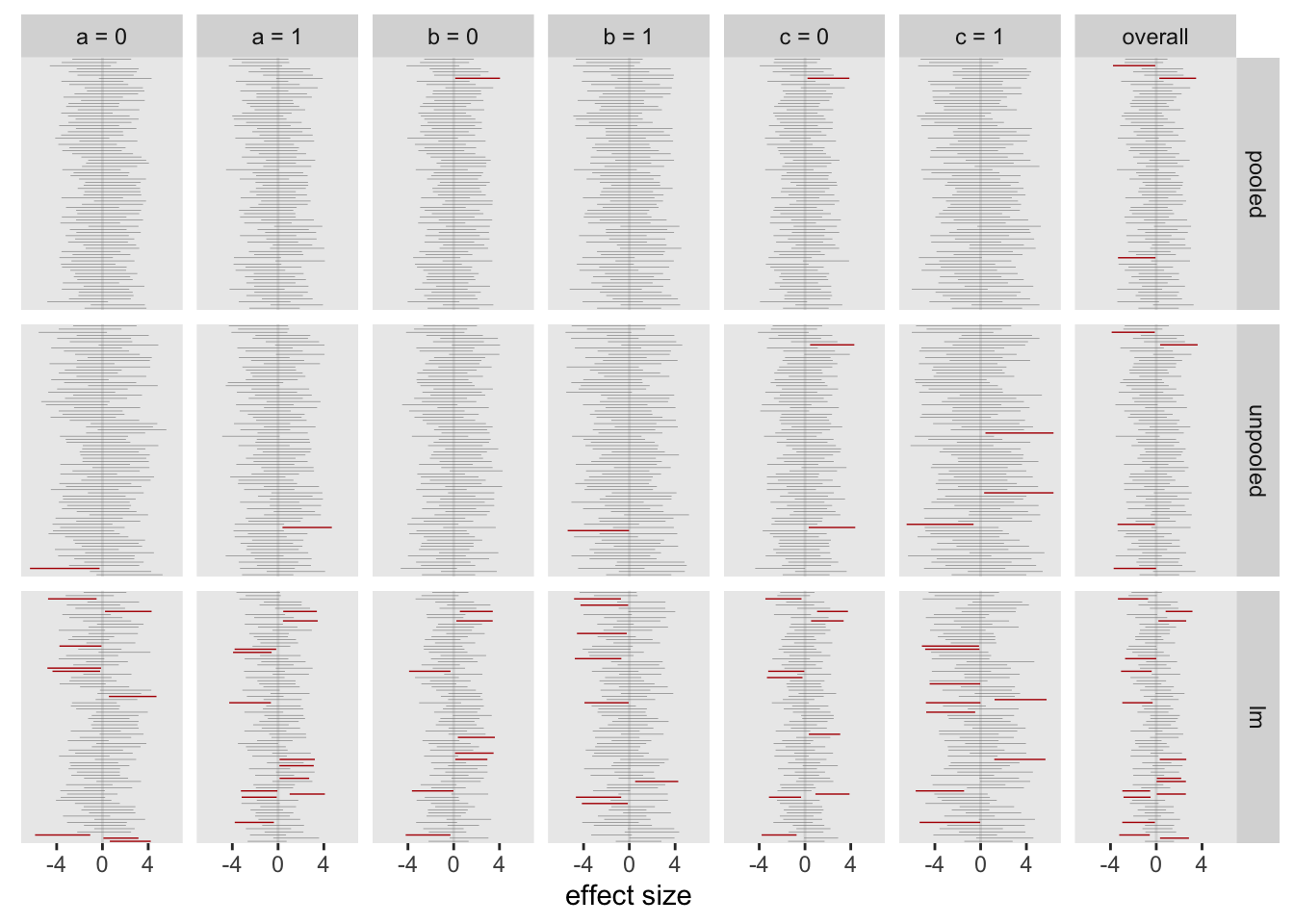
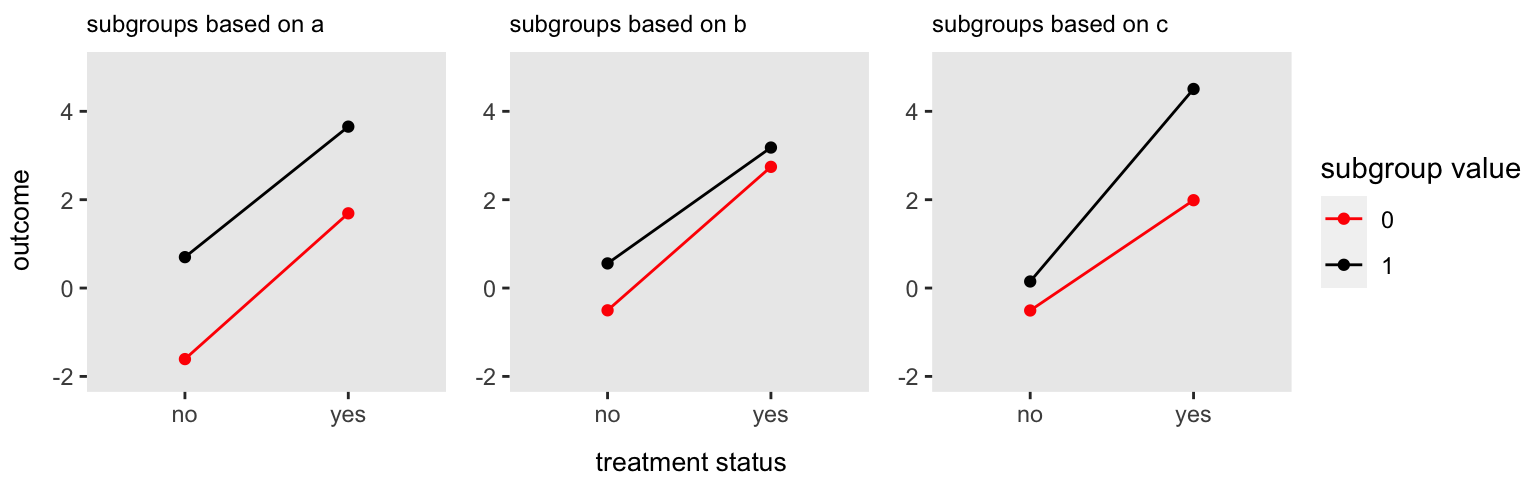
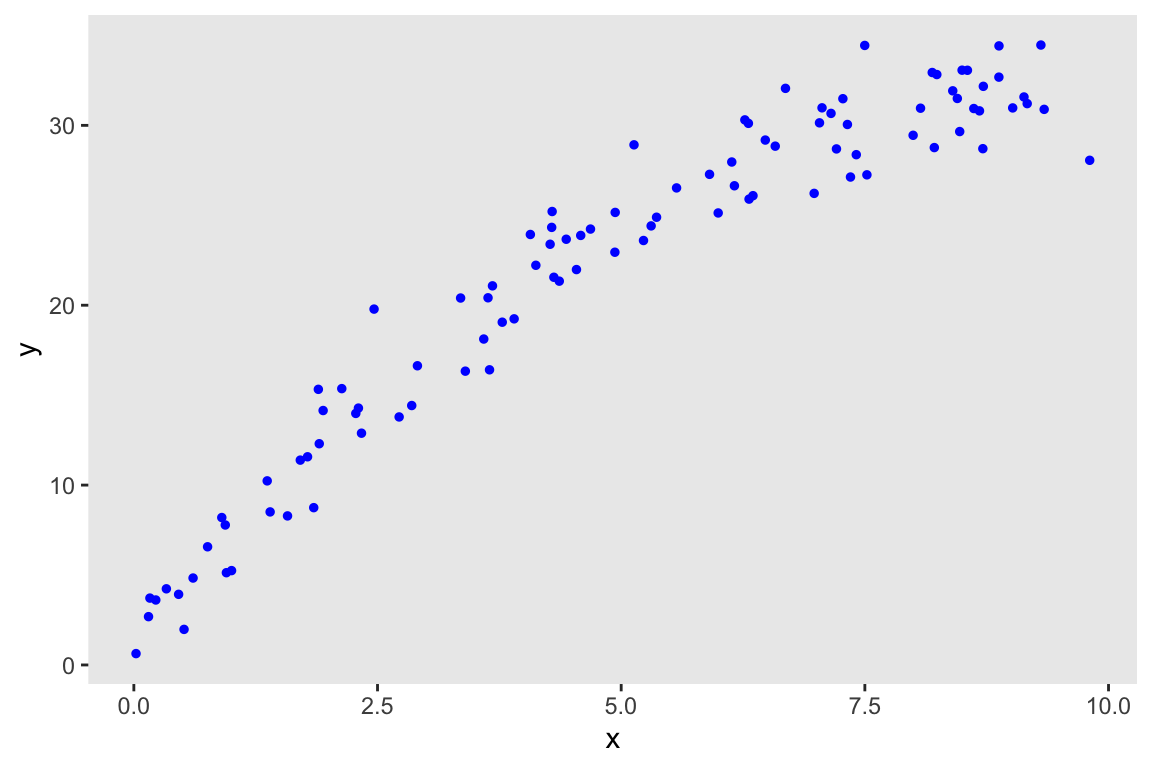
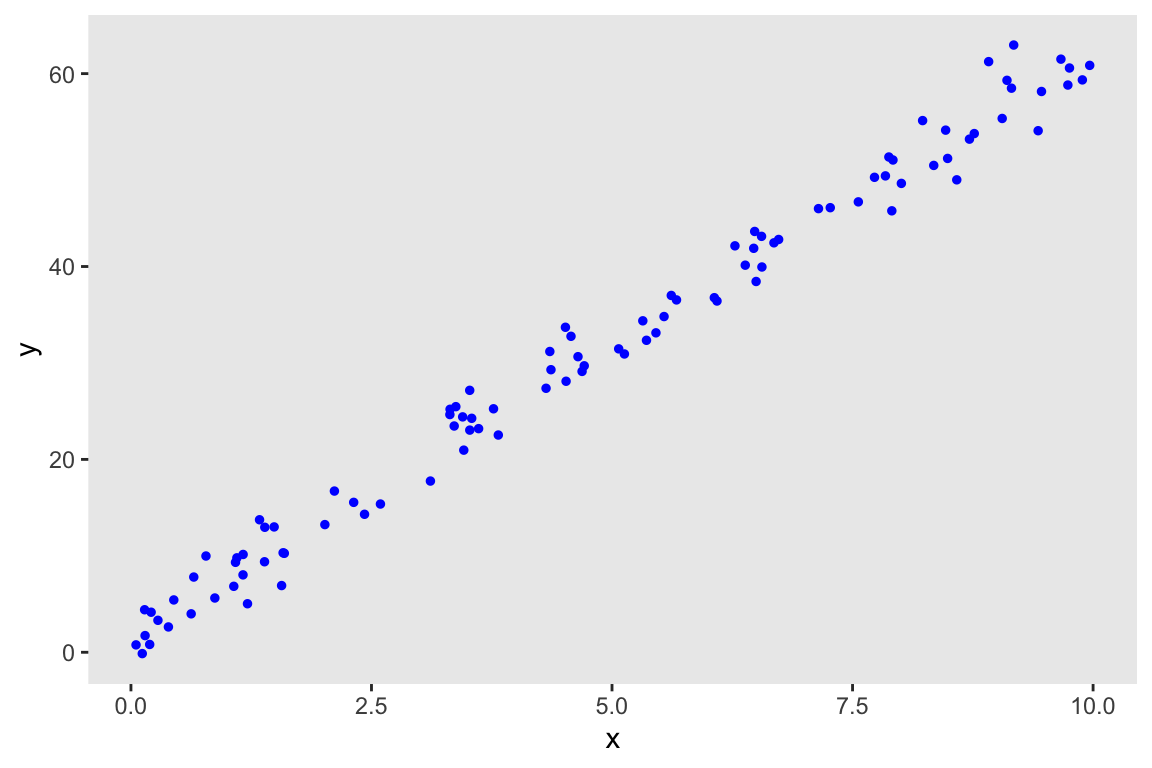
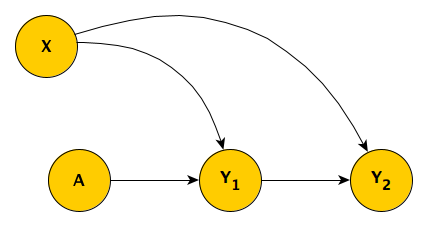
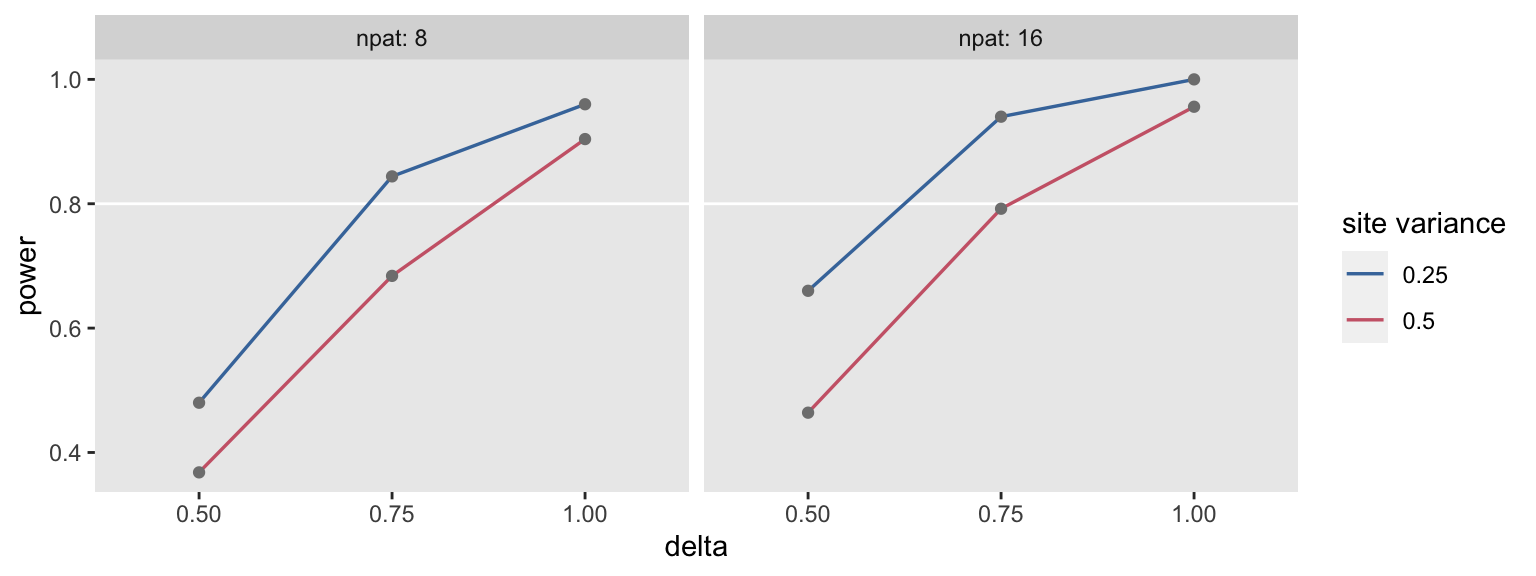
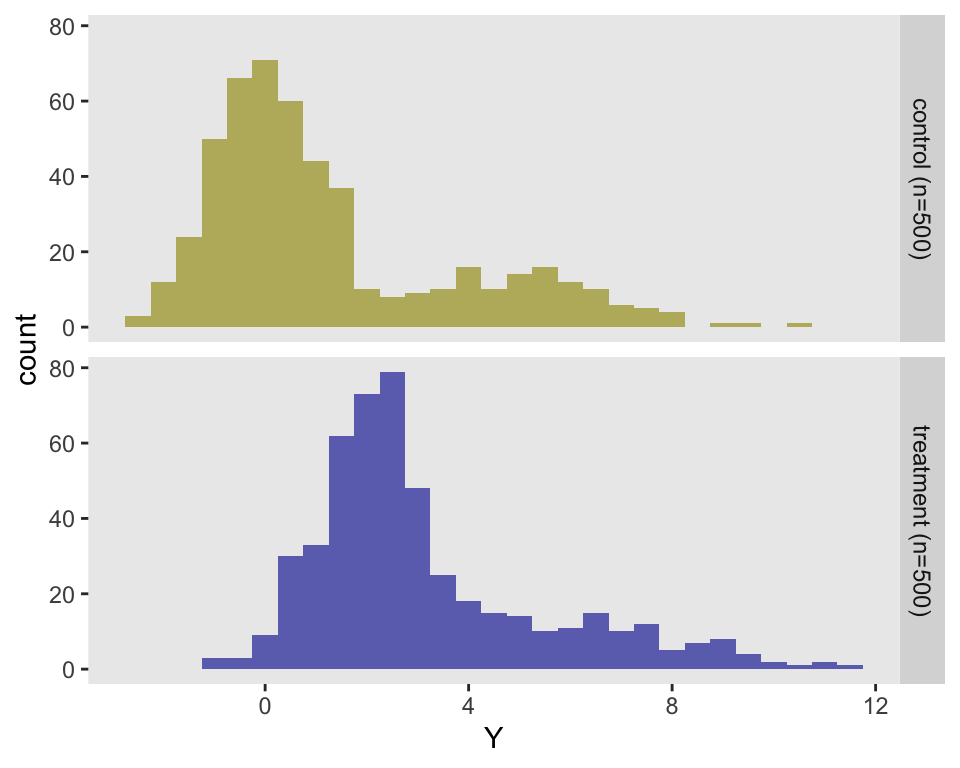
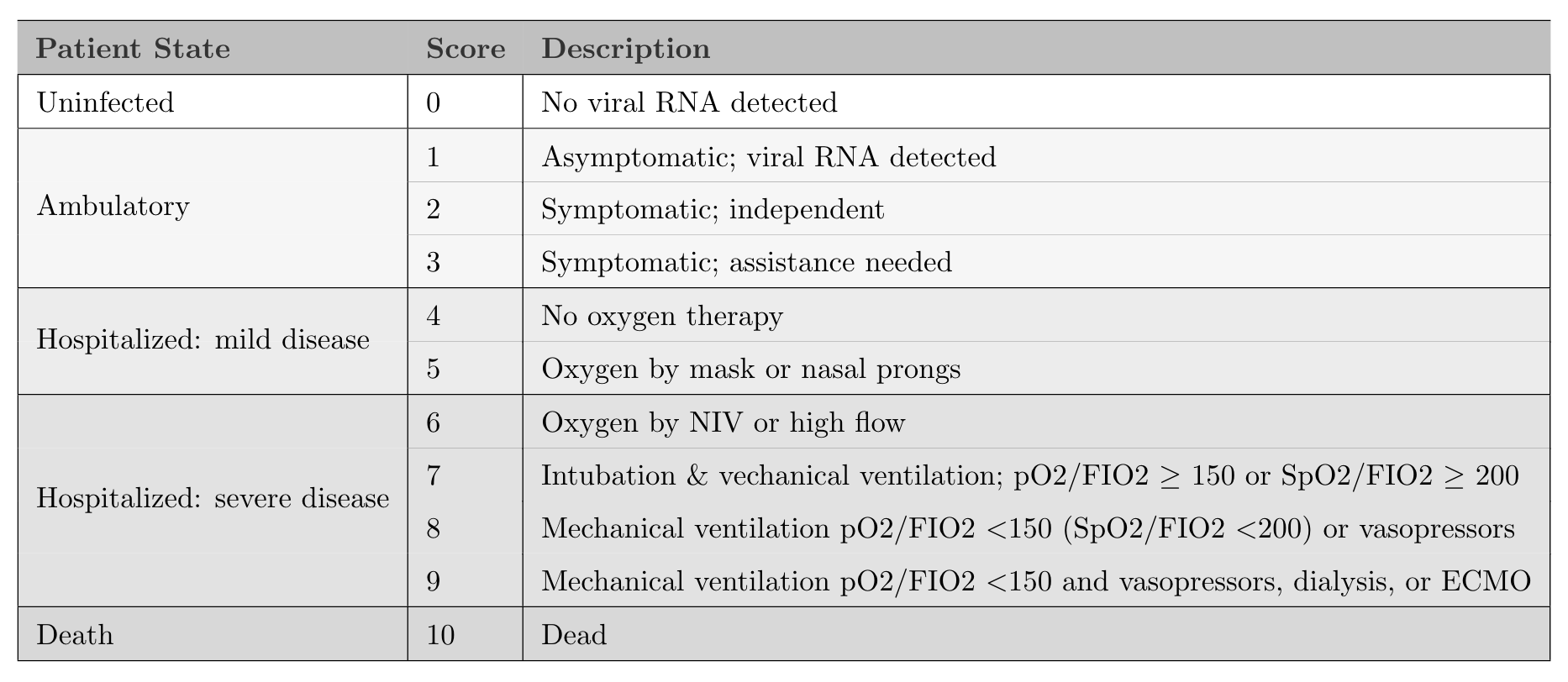
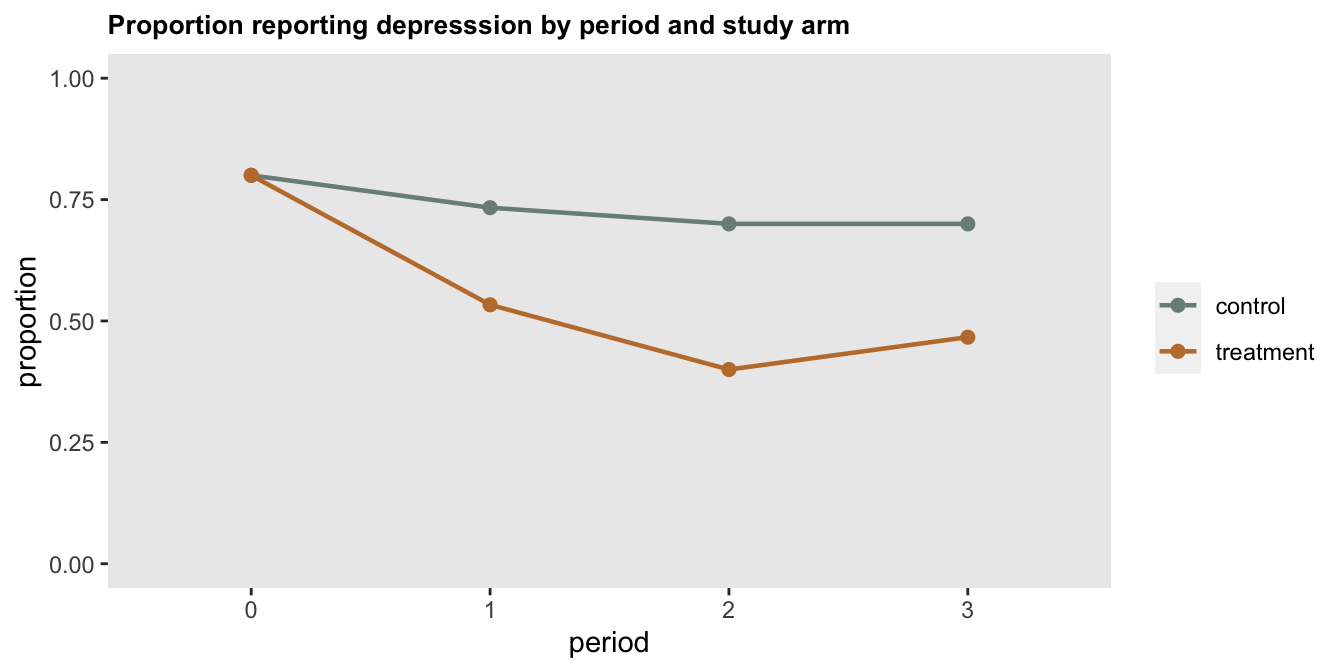
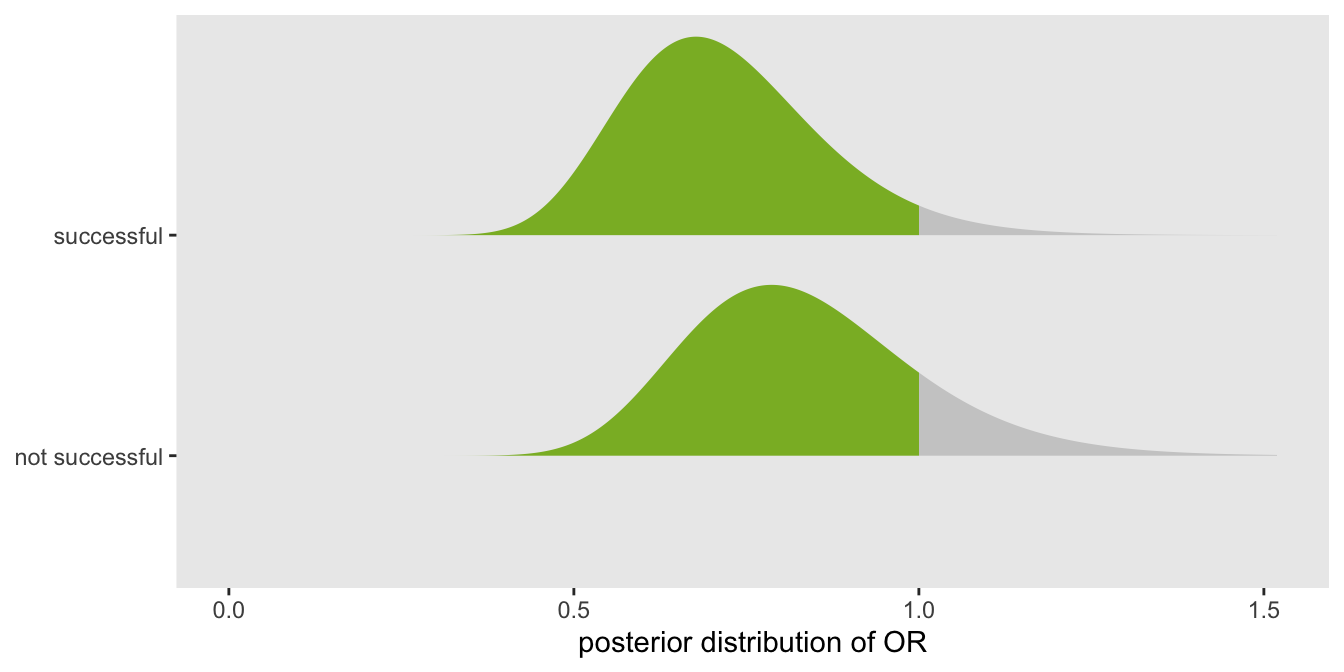
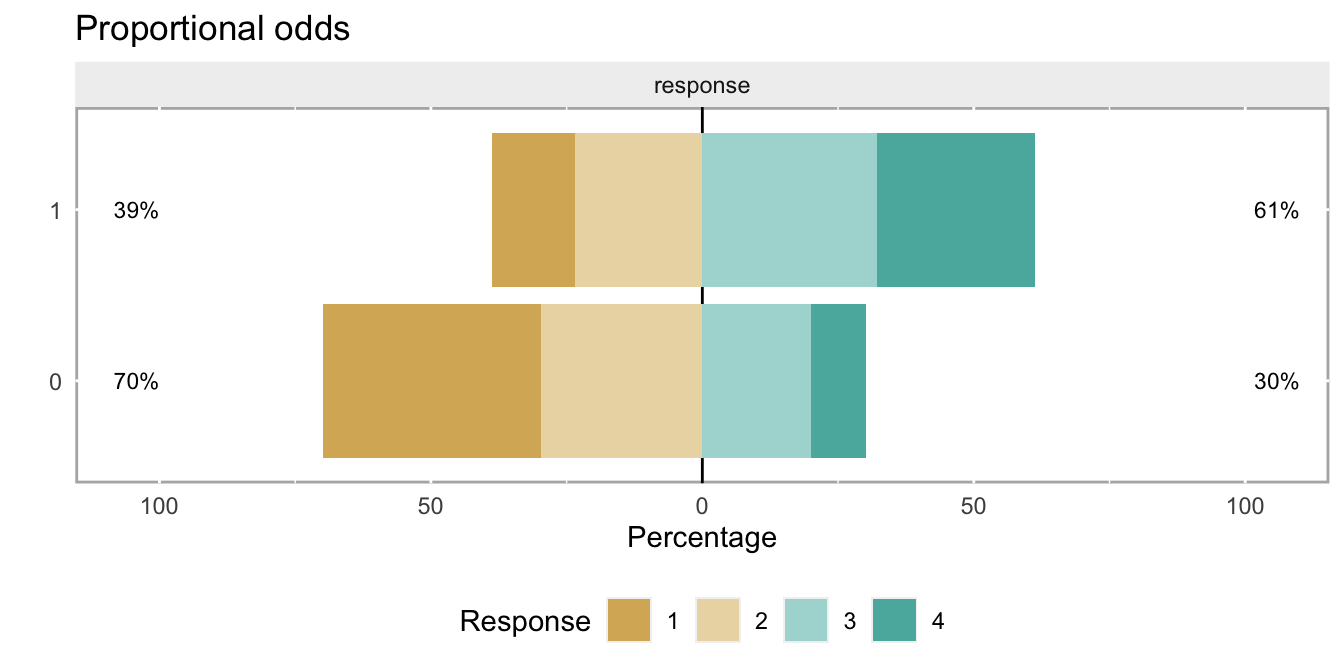
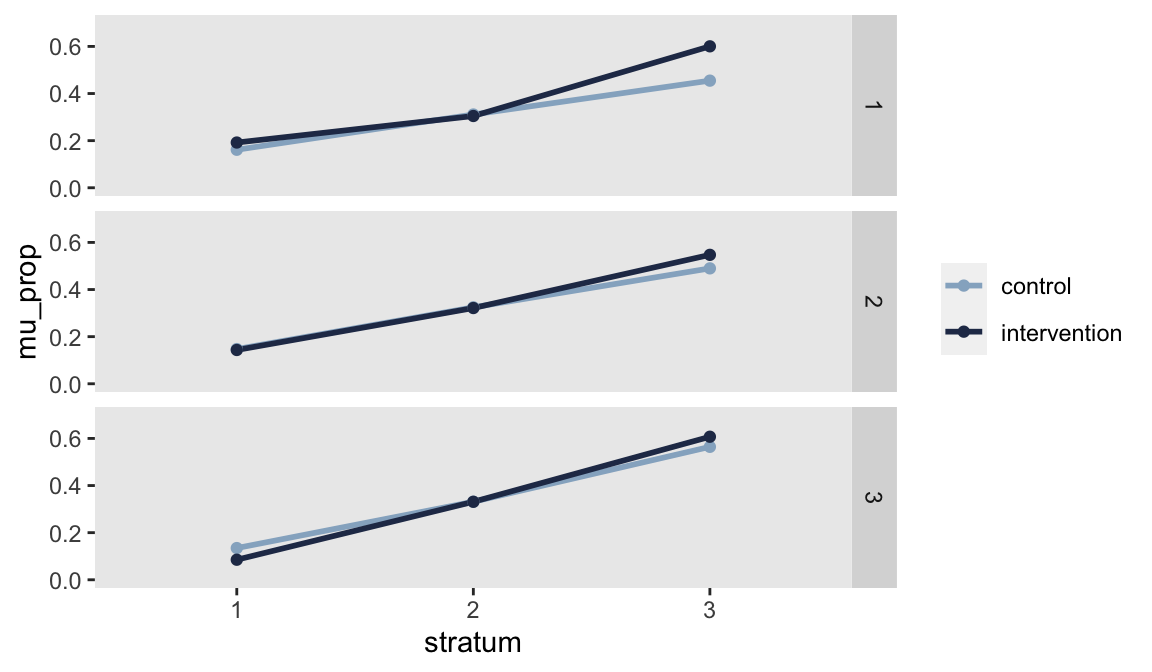
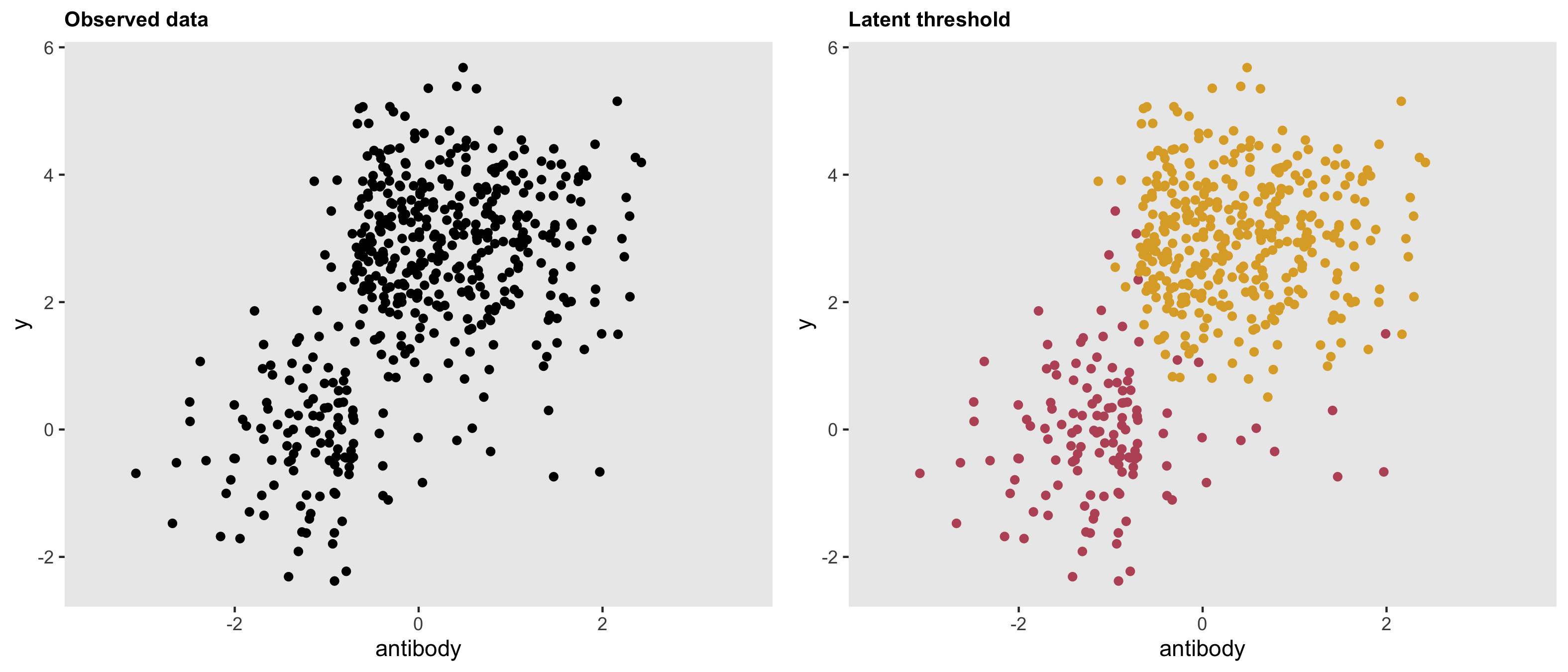
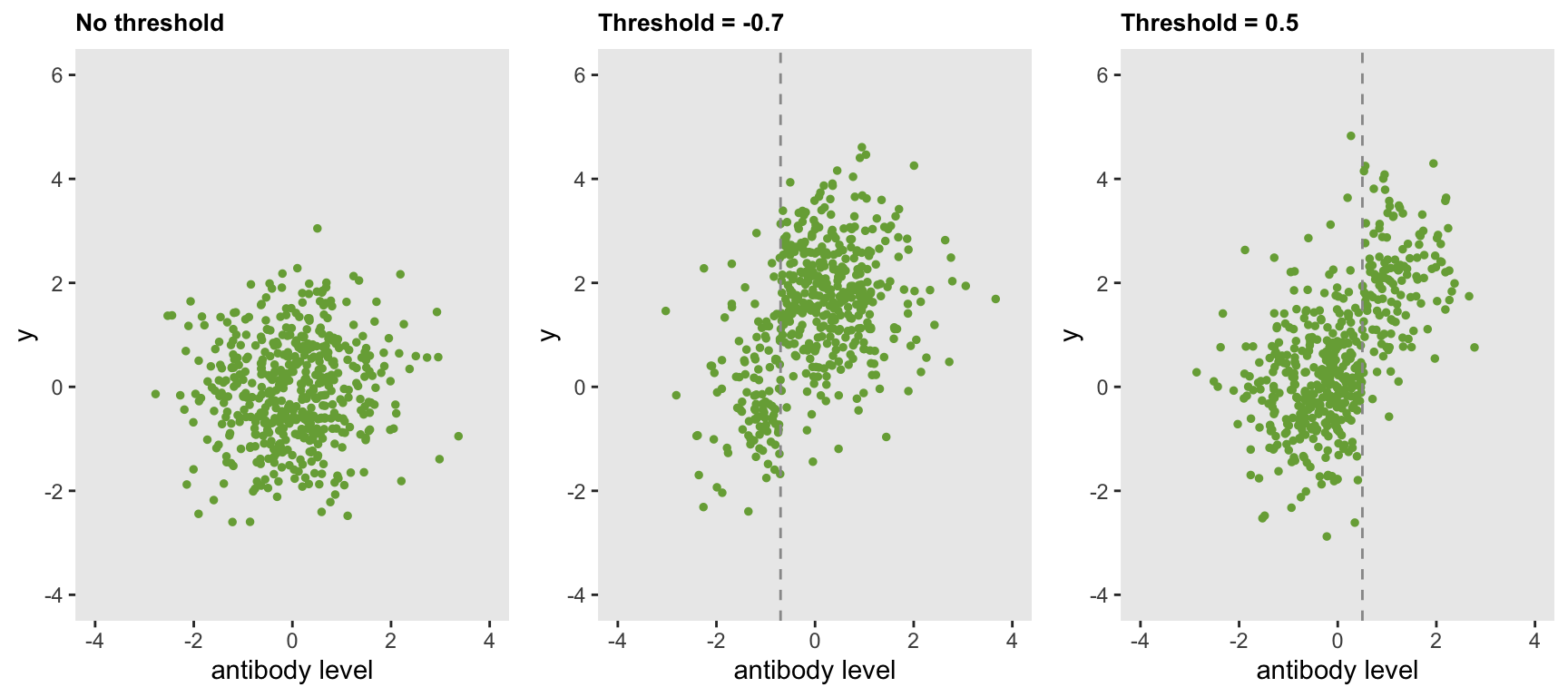
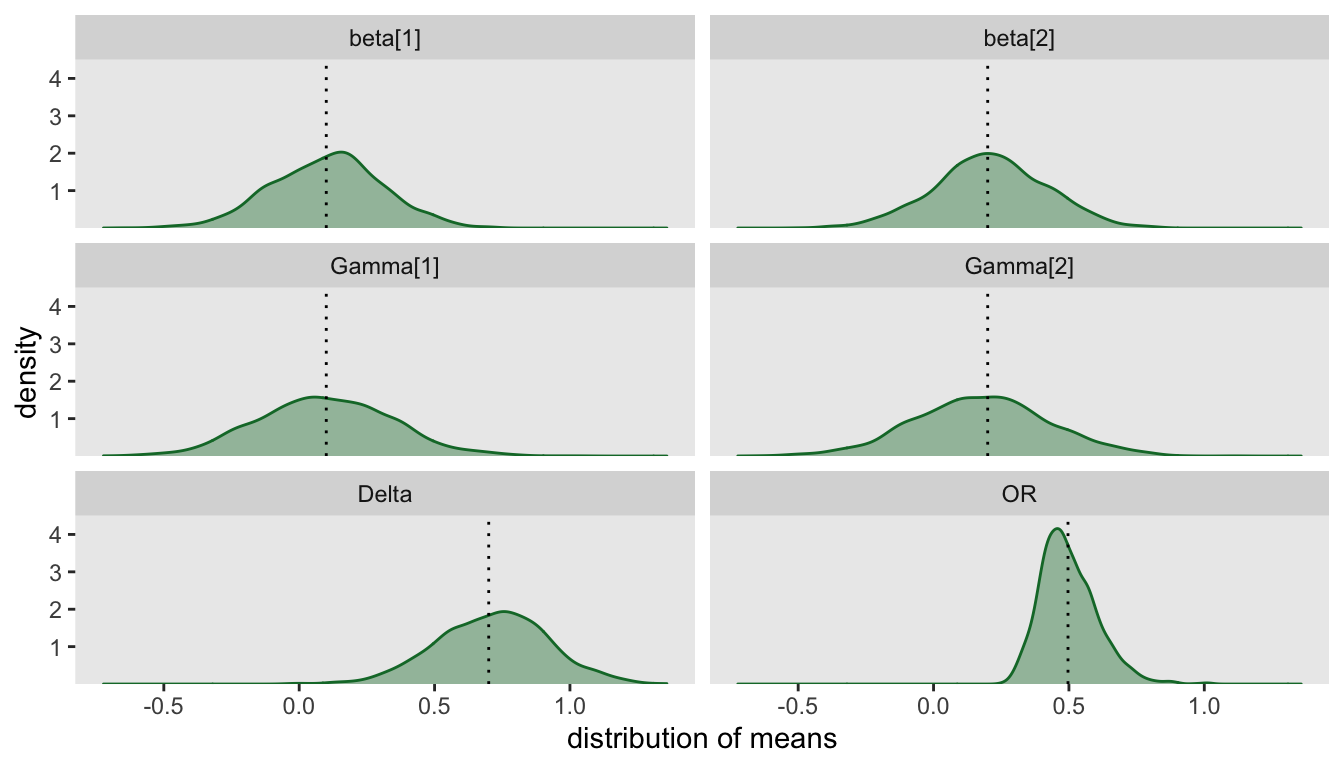
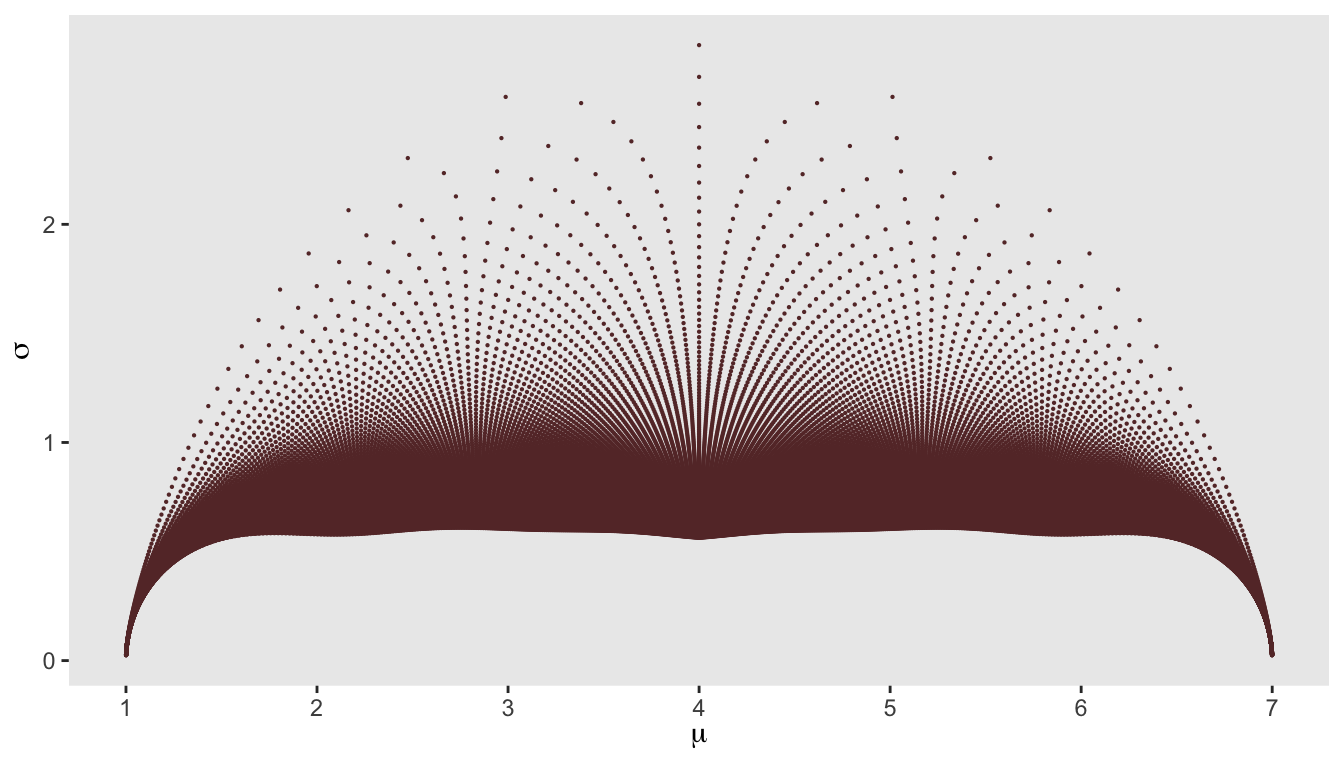
Analyzing a factorial design by focusing on the variance of effect sizes
Way back in 2018, long before the pandemic, I described a soon-to-be implemented simstudy function genMultiFac that facilitates the generation of multi-factorial study data. I followed up that post with a description of how we can use these types of efficient designs to answer multiple questions in the context of a ...