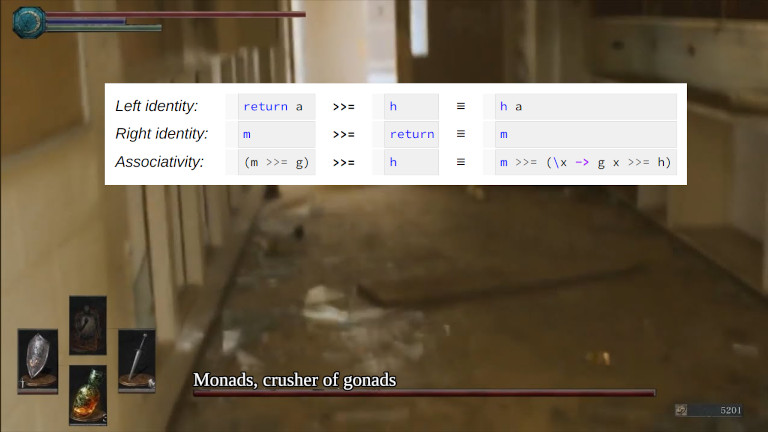
The {chronicler} package, an implementation of the logger monad in R
Back in February I discussed a package I was working on
which allowed users to add logging to function calls. I named the package {loudly} but decided
to rename it to {chronicler}.
I have been working on it for the past few weeks, and I think that a CRAN release ...