
Articles by Econometrics and Free Software

What would a keyboard optimised for Luxembourguish look like?
Explainbility of {tidymodels} models with {iml}

Explainbility of {tidymodels} models with {iml}
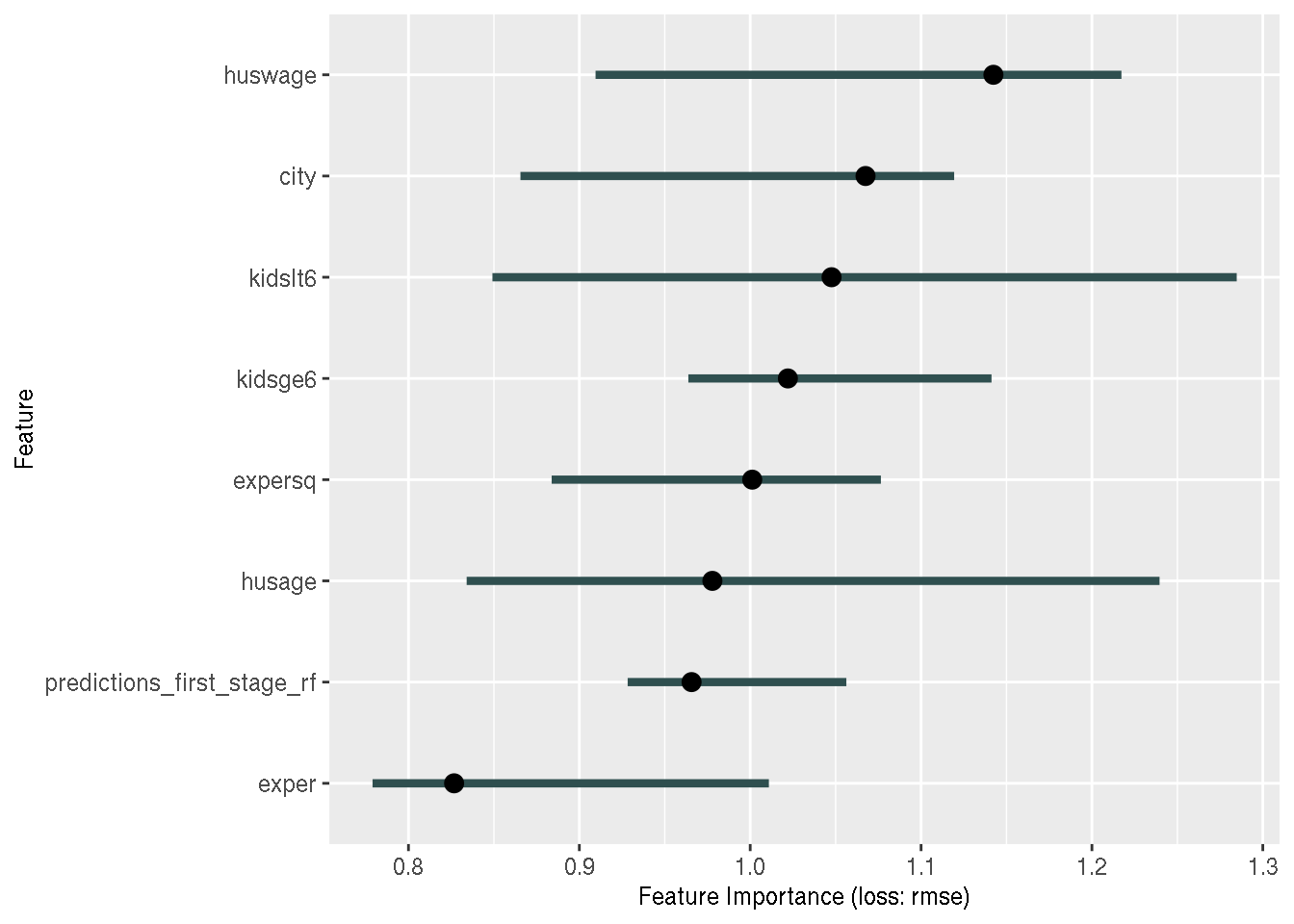
Machine learning with {tidymodels}

Machine learning with {tidymodels}
Synthetic micro-datasets: a promising middle ground between data privacy and data analysis
Intro: the need for microdata, and the risk of disclosure
Survey and administrative data are essential for scientific research, however accessing such datasets
can be very tricky, or even impossible. In my previous job I was responsible for getting access to
such “scientific micro-datasets” from institutions like Eurostat.
In general, ...
Synthetic micro-datasets: a promising middle ground between data privacy and data analysis
Intro: the need for microdata, and the risk of disclosure
Survey and administrative data are essential for scientific research, however accessing such datasets
can be very tricky, or even impossible. In my previous job I was responsible for getting access to
such “scientific micro-datasets” from institutions like Eurostat.
In general, ... [Read more...]
Dynamic discrete choice models, reinforcement learning and Harold, part 2
In this blog post, I present a paper that has really interested me for a long time. This is part2,
where I will briefly present the model of the paper, and try to play around with the data.
If you haven’t, I suggest you read
part 1 where I provid...

Dynamic discrete choice models, reinforcement learning and Harold, part 2
In this blog post, I present a paper that has really interested me for a long time. This is part2,
where I will briefly present the model of the paper, and try to play around with the data.
If you haven’t, I suggest you read
part 1 where I provide ... [Read more...]
Dynamic discrete choice models, reinforcement learning and Harold, part 1
Introduction
I want to write about an Econometrica paper written in 1987 (jstor link) by John Rust, currently Professor of Economics at
Georgetown University, paper which has been on my mind for the past 10 years or so. Why? Because
it is a s...

Dynamic discrete choice models, reinforcement learning and Harold, part 1
Introduction
I want to write about an Econometrica paper written in 1987 (jstor link) by John Rust, currently Professor of Economics at
Georgetown University, paper which has been on my mind for the past 10 years or so. Why? Because
it is a seminal paper in the econometric literature, but it is ... [Read more...]
Intrumental variable regression and machine learning
Intro
Just like the question “what’s the difference between machine learning and statistics” has shed a lot of ink (since at least Breiman (2001)), the same question but where statistics is replaced by econometrics has led to a lot of discussion, as well. I like this presentation by Hal Varian ...
Intrumental variable regression and machine learning
Intro
Just like the question “what’s the difference between machine learning and statistics” has shed a lot of ink (since at least Breiman (2001)), the same question but where statistics is replaced by econometrics has led to a lot of discussion, as well. I like this presentation by Hal Varian ... [Read more...]
Multiple data imputation and explainability
Introduction
Imputing missing values is quite an important task, but in my experience, very often, it is performed
using very simplistic approaches. The basic approach is to impute missing values for
numerical features using the average of each fe...

Multiple data imputation and explainability
Introduction
Imputing missing values is quite an important task, but in my experience, very often, it is performed
using very simplistic approaches. The basic approach is to impute missing values for
numerical features using the average of each feature, or using the mode for categorical features.
There are better ways ... [Read more...]
Cluster multiple time series using K-means
I have been recently confronted to the issue of finding similarities among time-series and though
about using k-means to cluster them. To illustrate the method, I’ll be using data from the
Penn World Tables, readily available in R (inside the {pwt9...

Cluster multiple time series using K-means
I have been recently confronted to the issue of finding similarities among time-series and though
about using k-means to cluster them. To illustrate the method, I’ll be using data from the
Penn World Tables, readily available in R (inside the {pwt9} package):
library(tidyverse) library(lubridate) library(pwt9) library(brotools)First, of all, let’s only ... [Read more...]
Split-apply-combine for Maximum Likelihood Estimation of a linear model
Intro
Maximum likelihood estimation is a very useful technique to fit a model to data used a lot in
econometrics and other sciences, but seems, at least to my knowledge, to not be so well known by
machine learning practitioners (but I may be wro...

Split-apply-combine for Maximum Likelihood Estimation of a linear model
Intro
Maximum likelihood estimation is a very useful technique to fit a model to data used a lot in
econometrics and other sciences, but seems, at least to my knowledge, to not be so well known by
machine learning practitioners (but I may be wrong about that). Other useful techniques ... [Read more...]
Copyright © 2025 | MH Corporate basic by MH Themes