Automating checks of *handcrafted* Word tables with {docxtractr}
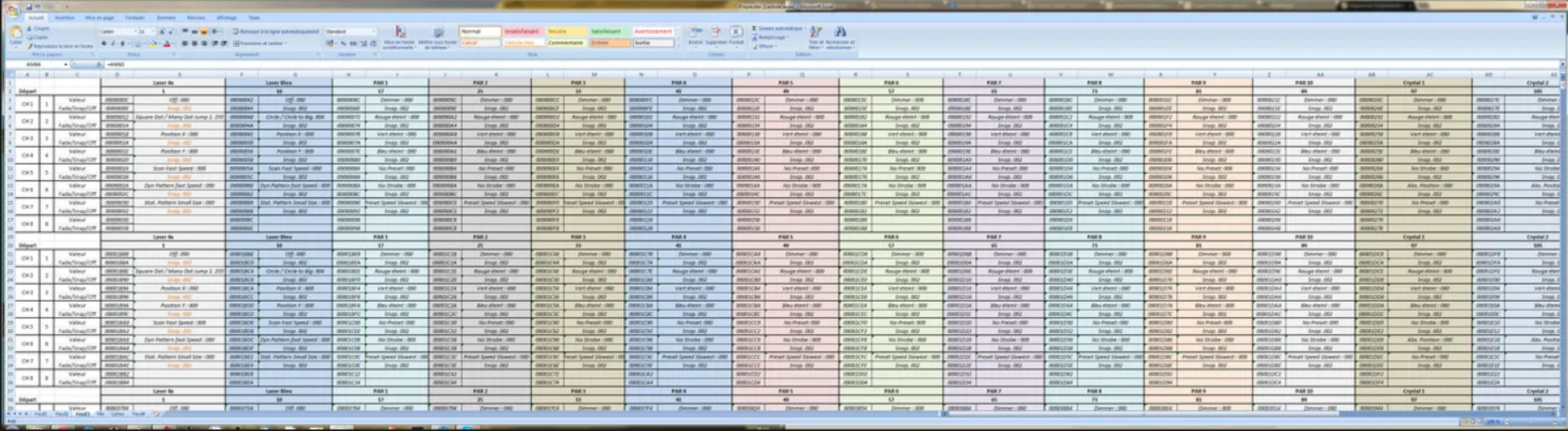
Unfortunately not everyone knows about literate programming so many tables in
Word documents are “generated” by hand (generated is really too strong a word)
and what very often happens is that these handcrafted tables have typos. Usually
it’s totals that are wrong. Checking the totals in these tables by ...