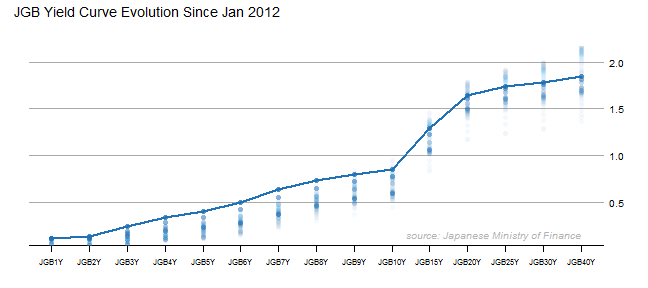
See the last post for all the details. I just could not help creating a couple more. Variations on Favorite Plot - Time Series Line of JGB Yields by Maturity
p2 <- xyplot(value ~ date | indexname, data = jgb.melt, <br> type = "l", layout = c(length(unique(jgb.melt$indexname)), <br> 1), panel = function(x, y, ...) {<br> panel.abline(h = c(min(y), max(y)))<br> panel.xyplot(x = x, y = y, ...)<br> panel.text(x = x[length(x)/2], y = max(y), <br> labels = levels(jgb.melt$indexname)[panel.number()], <br> cex = 0.7, pos = 3)<br> }, scales = list(x = list(tck = c(1, 0), alternating = 1), <br> y = list(tck = c(1, 0), lwd = c(0, 1))), strip = FALSE, <br> par.settings = list(axis.line = list(col = 0)), <br> xlab = NULL, ylab = "Yield", main = "JGB Yields by Maturity Since Jan 2012")<br>p2 <- p2 + layer(panel.abline(h = pretty(jgb.melt$value), <br> lty = 3))<br>p2<br>
From TimelyPortfolio
<br>jgb.xts.diff <- jgb.xts["2012::", ] - matrix(rep(jgb.xts["2012::", <br> ][1, ], NROW(jgb.xts["2012::", ])), ncol = NCOL(jgb.xts), <br> byrow = TRUE)<br>jgb.diff.melt <- xtsMelt(jgb.xts.diff)<br>jgb.diff.melt$date <- as.Date(jgb.diff.melt$date)<br>jgb.diff.melt$value <- as.numeric(jgb.diff.melt$value)<br>jgb.diff.melt$indexname <- factor(jgb.diff.melt$indexname, <br> levels = colnames(jgb.xts))<br><br>p4 <- xyplot(value ~ date | indexname, data = jgb.diff.melt, <br> type = "h")<br><br>update(p2, ylim = c(min(jgb.diff.melt$value), max(jgb.melt$value) + <br> 0.5)) + p4<br>
From TimelyPortfolio
<br>update(p2, ylim = c(min(jgb.diff.melt$value), max(jgb.melt$value) + <br> 0.5), par.settings = list(axis.line = list(col = "gray70"))) + <br> update(p4, panel = function(x, y, col, ...) {<br> # do color scale from red(negative) to<br> # blue(positive)<br> cc.palette <- colorRampPalette(c(brewer.pal("Reds", <br> n = 9)[7], "white", brewer.pal("Blues", <br> n = 9)[7]))<br> cc.levpalette <- cc.palette(20)<br> cc.levels <- level.colors(y, at = do.breaks(c(-0.3, <br> 0.3), 20), col.regions = cc.levpalette)<br> panel.xyplot(x = x, y = y, col = cc.levels, <br> ...)<br> })<br>
From TimelyPortfolio
<br><br>p5 <- horizonplot(value ~ date | indexname, data = jgb.diff.melt, <br> layout = c(1, length(unique(jgb.diff.melt$indexname))), <br> scales = list(x = list(tck = c(1, 0))), xlab = NULL, <br> ylab = NULL)<br><br>p5<br>
From TimelyPortfolio
<br>update(p2, ylim = c(0, max(jgb.melt$value) + 0.5), <br> panel = panel.xyplot) + p5 + update(p2, ylim = c(0, <br> max(jgb.melt$value)))<br>
From TimelyPortfolio
Variations on Yield Curve Evolution ...