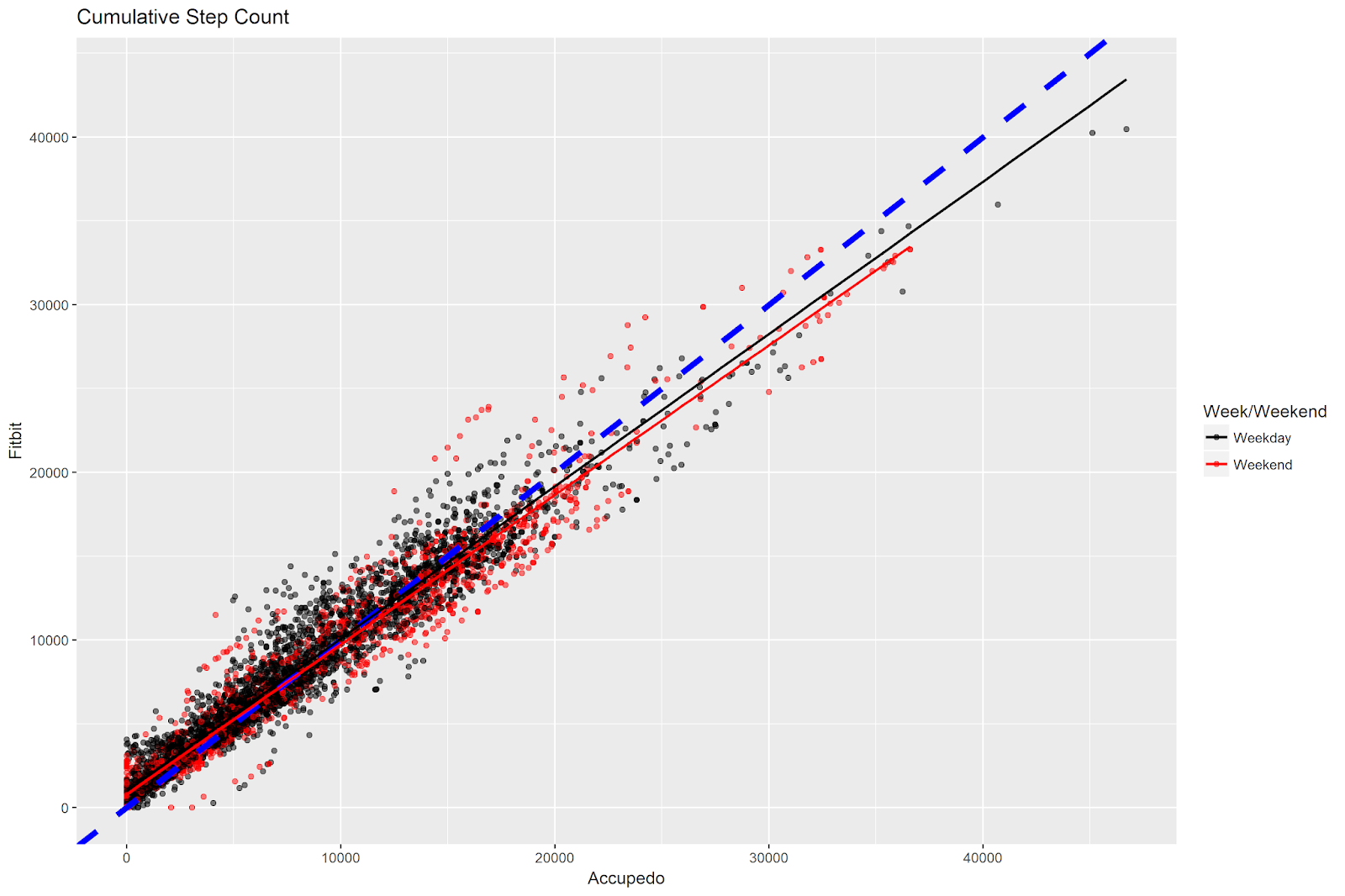
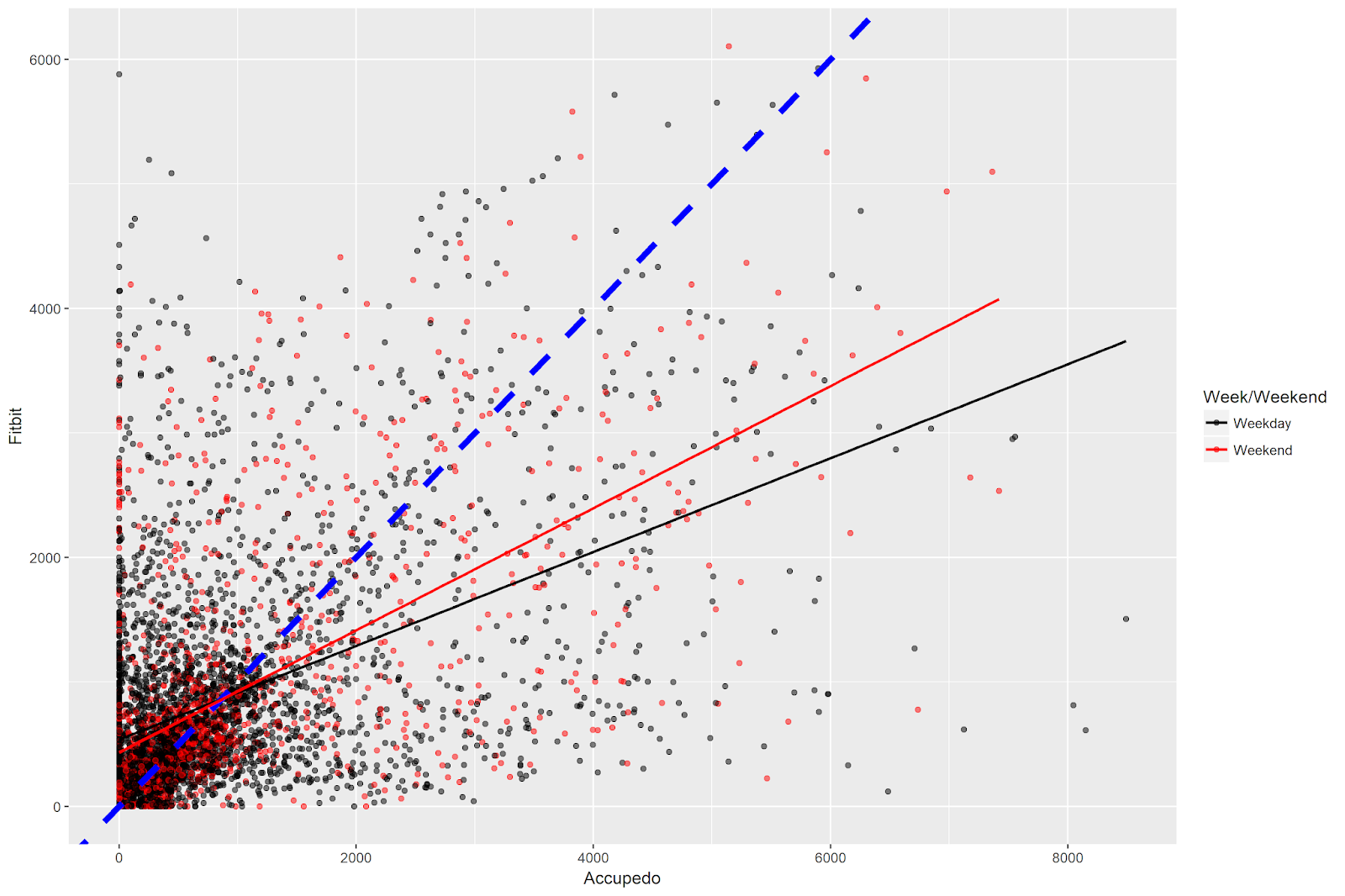
The Vibe of Flanders: Part 2
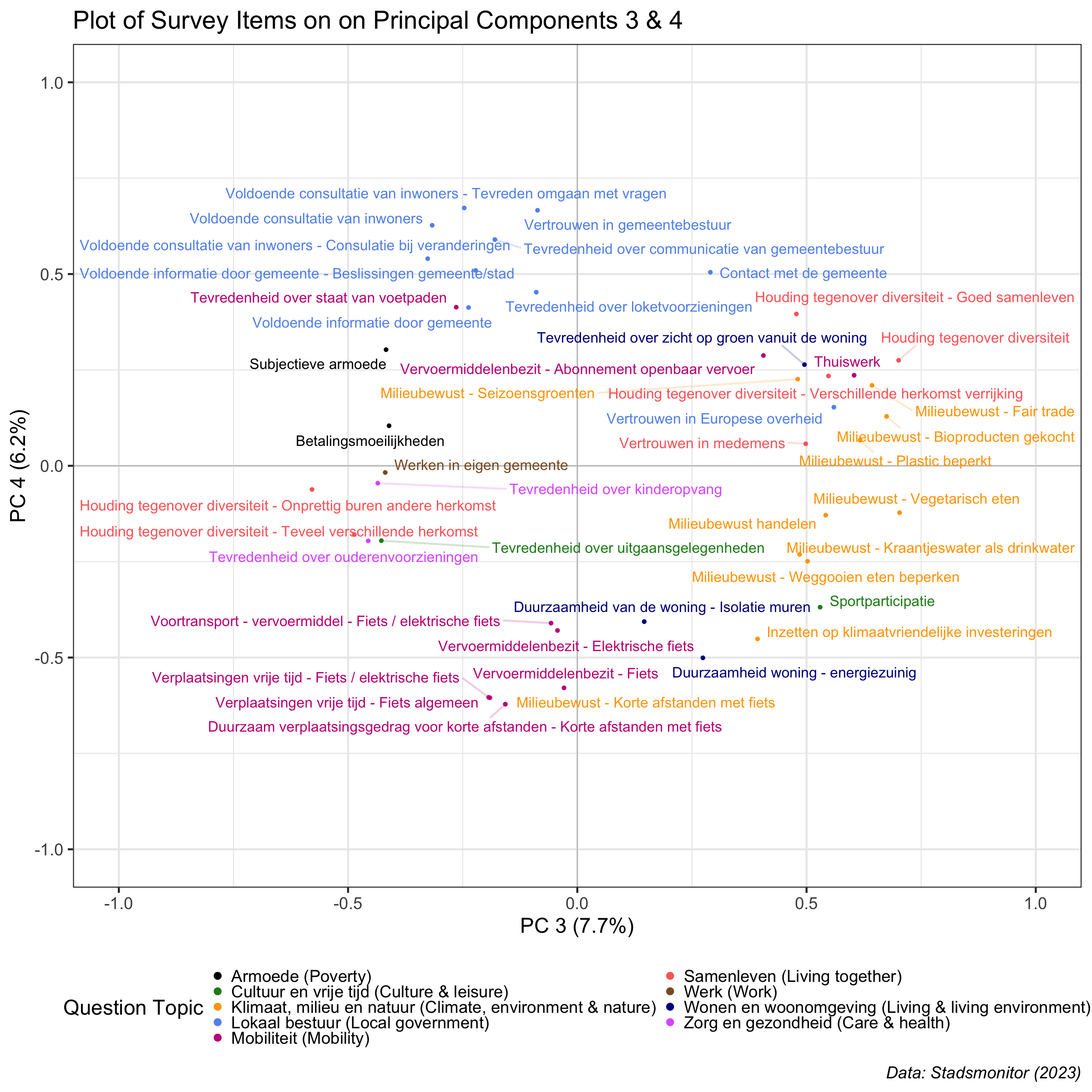
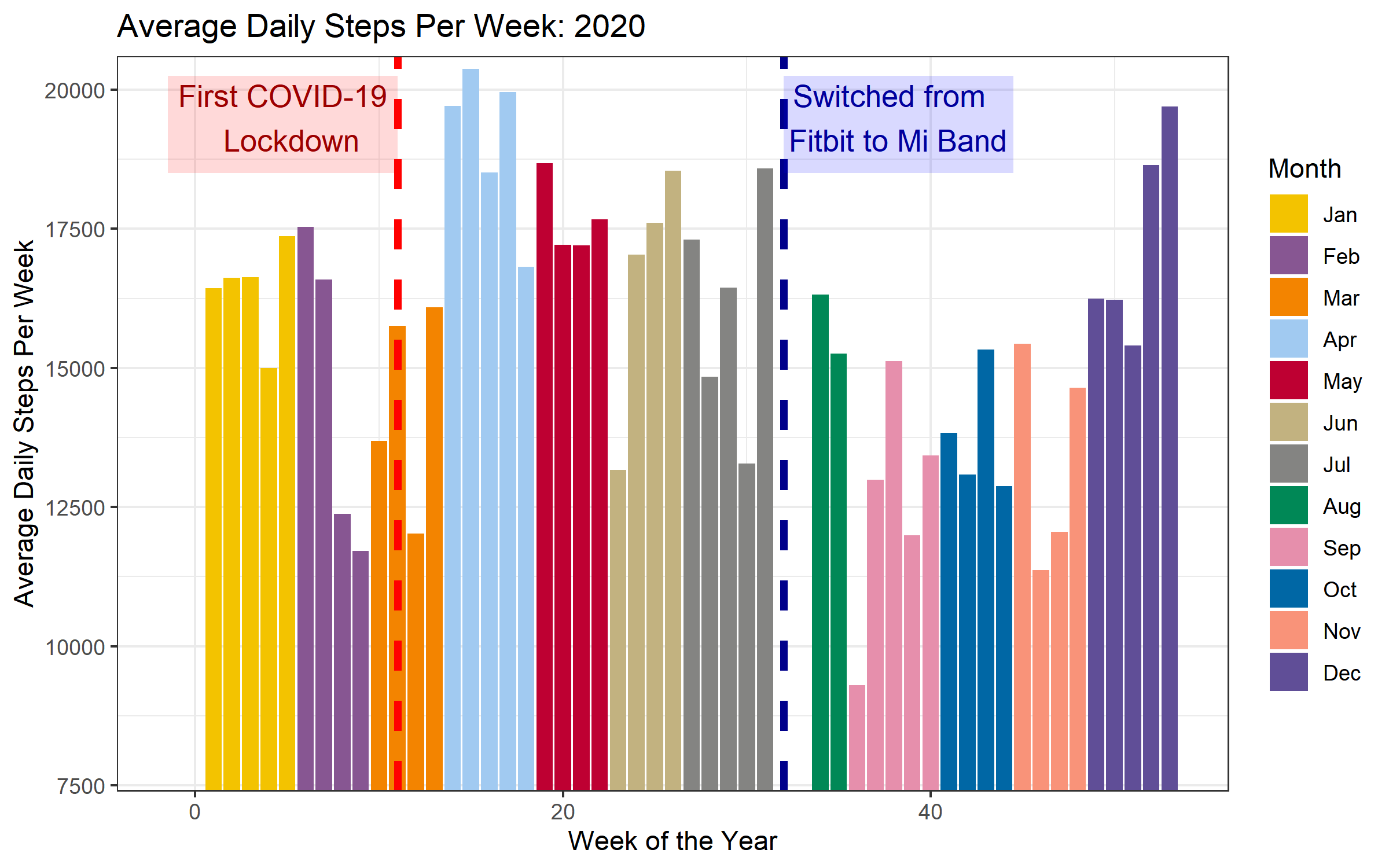
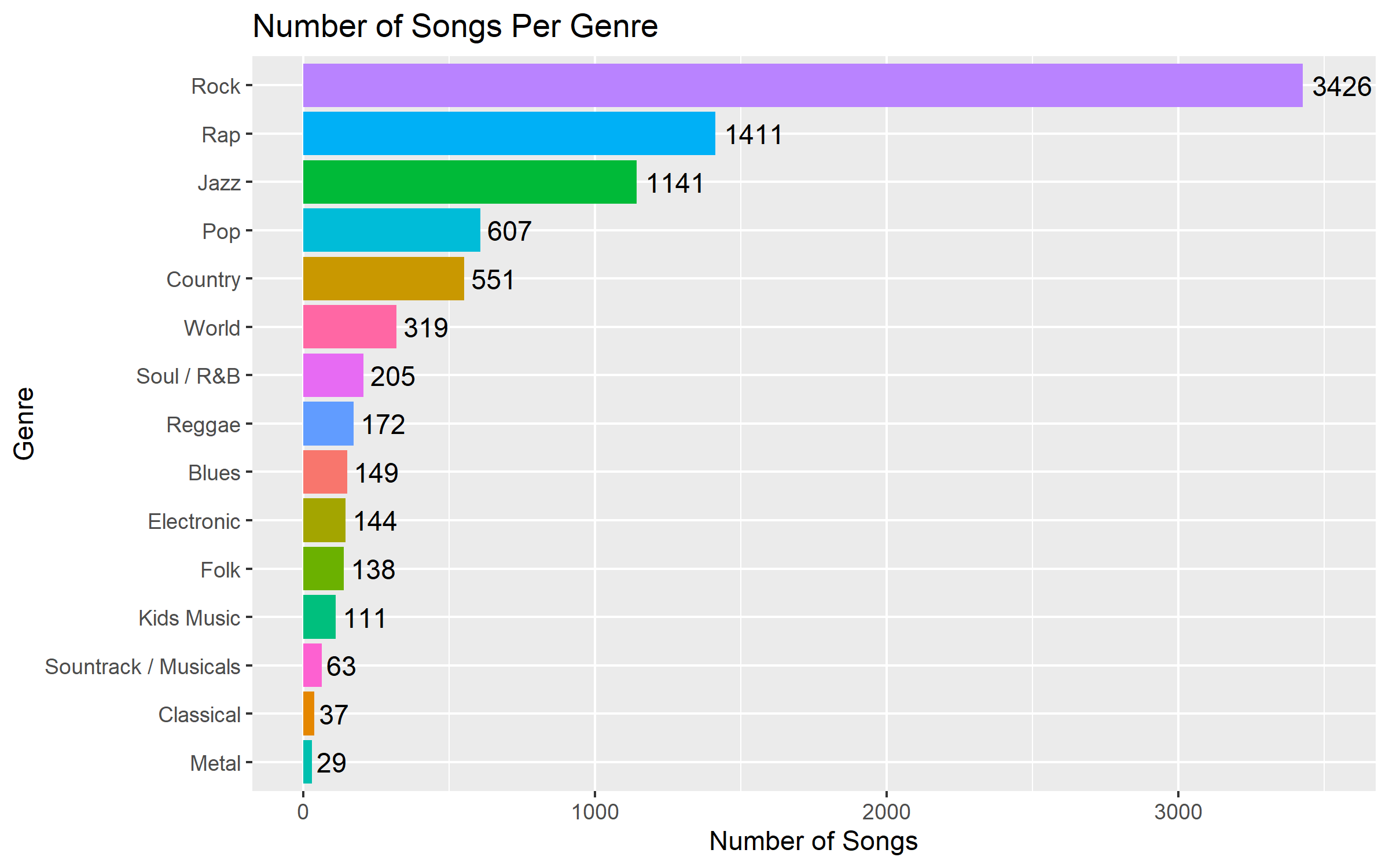
This blog post is the second installment in a series detailing analyses of the 2023 De Gemeente-Stadsmonitor (The Municipality and City Monitor) survey, conducted in the region of Flanders in Belgium. You can check out the first post here.
In the previous post, we used Principal Components Analysis and data visualization ...