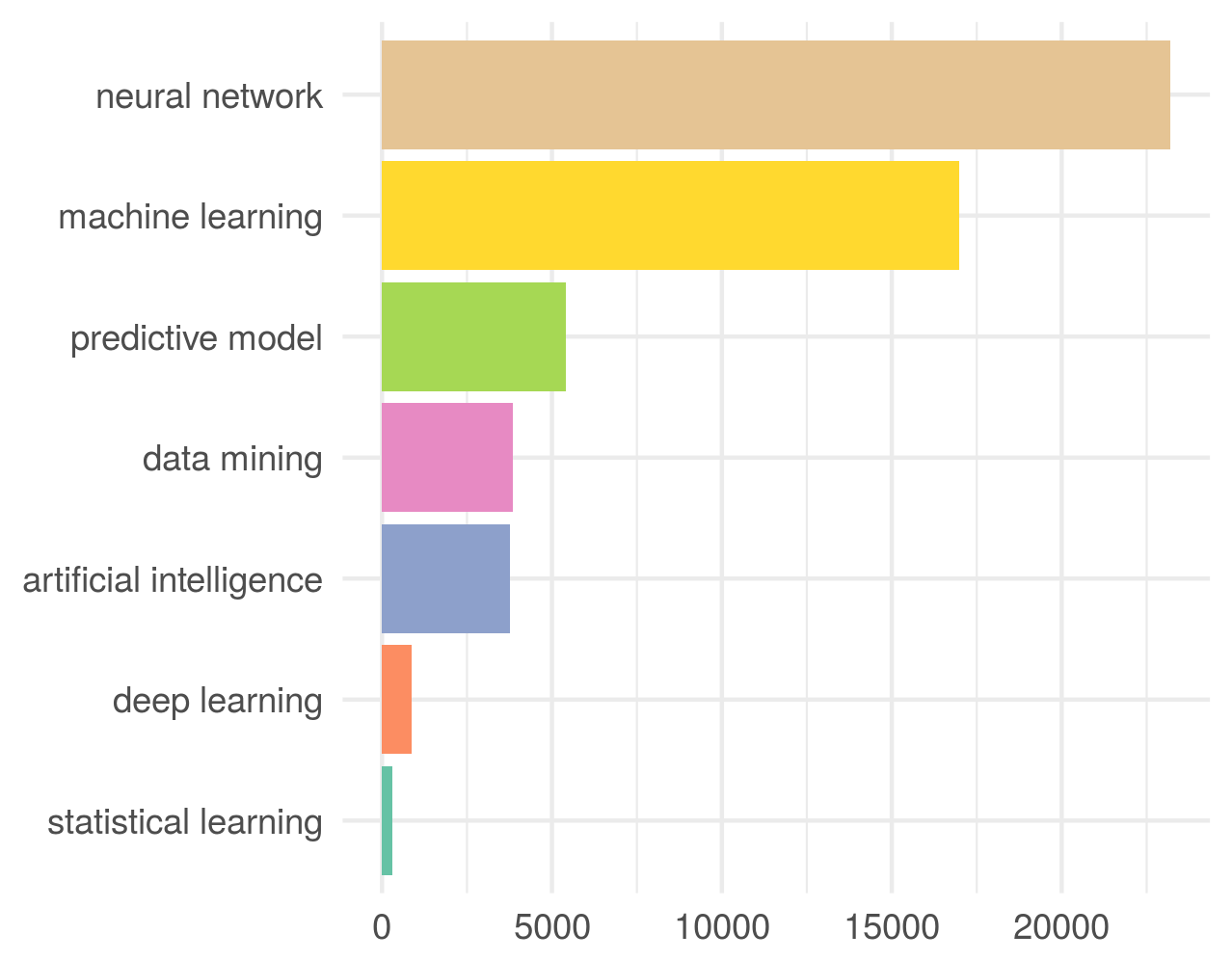
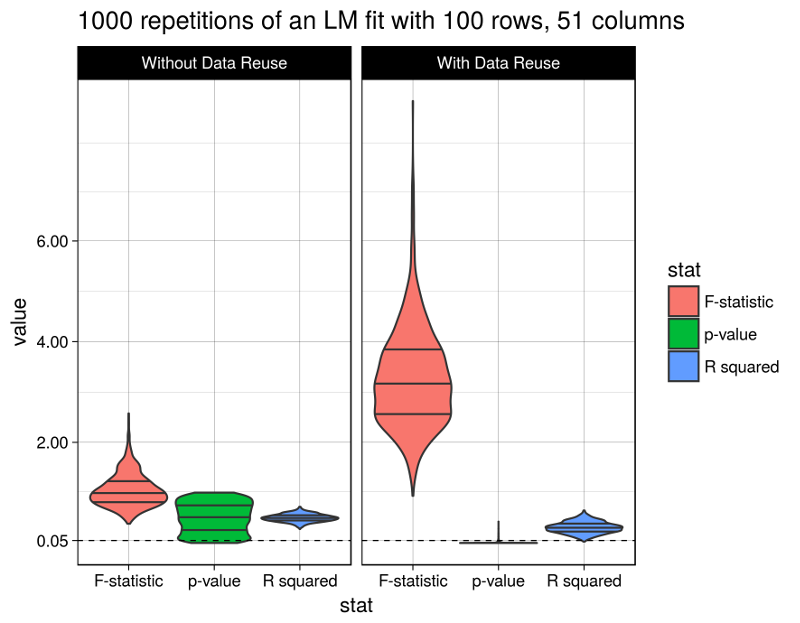
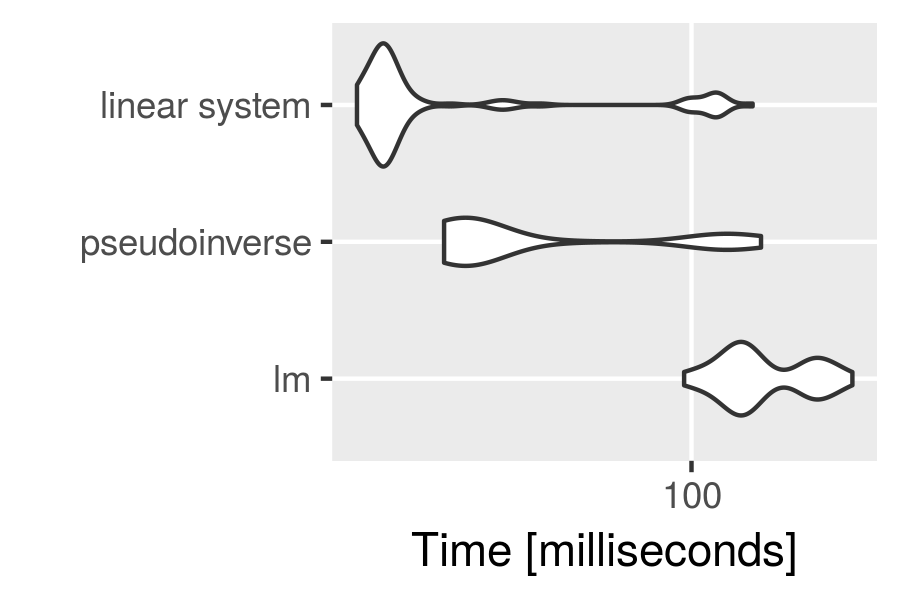
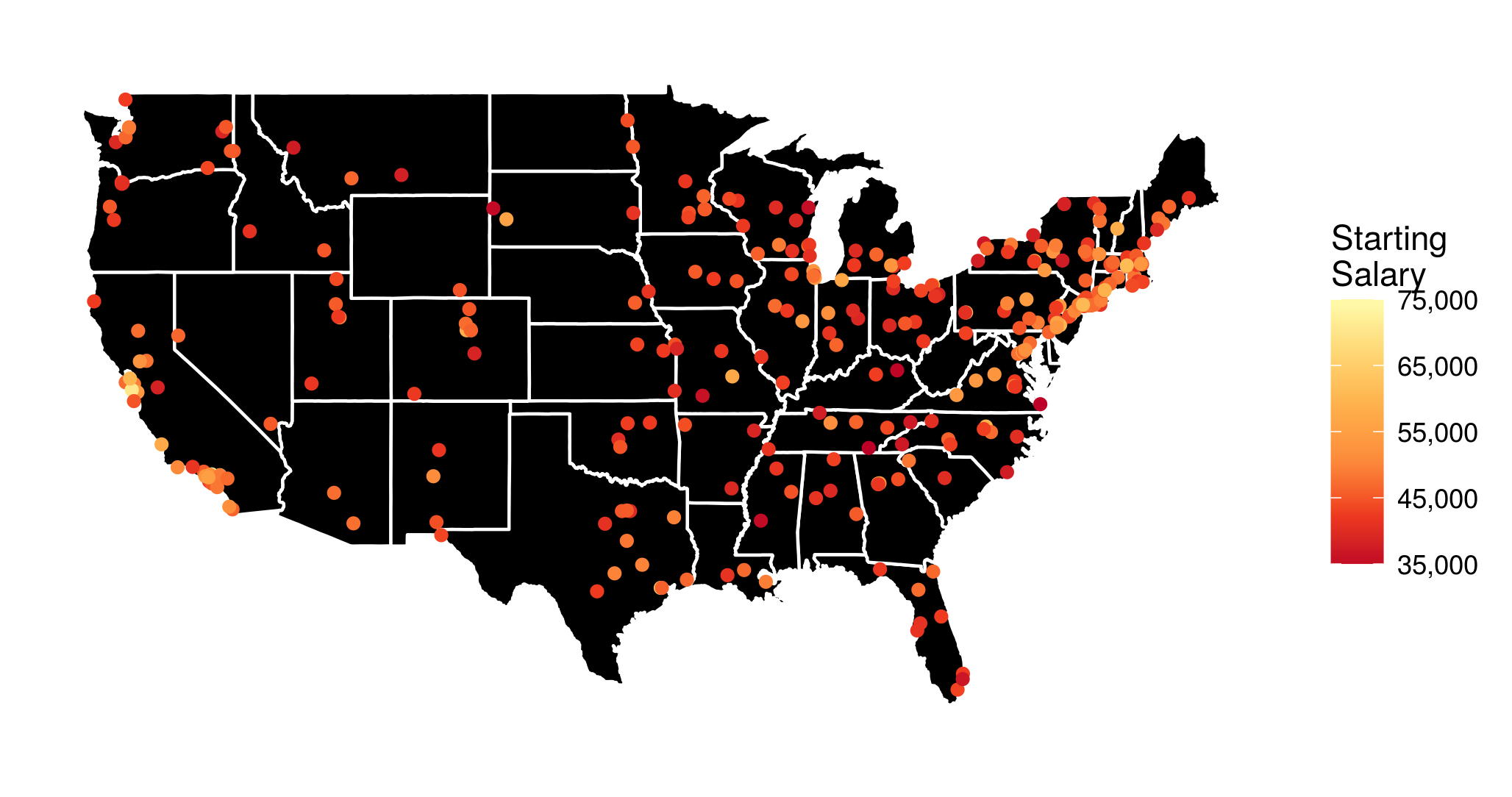
Probabilistic interpretation of AUC
Unfortunately this was not taught in any of my statistics or data analysis classes at university (wtf it so needs to be :scream_cat:).
So it took me some time until I learned that the AUC has a nice probabilistic meaning.
What’s AUC anyway?
AUC is the area under ... [Read more...]