
Draft position for players in the NBA for the 2020-21 season
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
When the 2022 NBA draft happened almost a month ago, I thought to myself: do players picked earlier in the draft (i.e. higher-ranked) actually end up having better/longer careers?
If data wasn’t an issue, the way I would do it would be to look at players chosen in the draft lottery (top 60 picks) in the past 10/20 years. For each player, I would look at how many years he played in the NBA and see if there was a correlation between that and draft position. (Here, number of years in the NBA is a proxy for how successful an NBA career is. There are other possible ways to define success, e.g. minutes played, points scored.)
Unfortunately data is an issue, so I ended up looking at a related question: What are the draft positions of players currently in the NBA? If players picked earlier in the draft are more successful, than we would see more of such players in the mix. I had wanted to do this analysis for the season that just happened (2021-2022) but could not find the data, and so I’m doing this for the 2020-21 season.
Importing the data
I got the list of players that played in the 2020-21 season from Basketball Reference. I got the draft position of the players from Wyatt Walsh on Kaggle. (Walsh provides a lot more data than just draft position: it’s worth a look!)
The code below loads the draft data (file path will depend on where the datasets are saved on your machine). We only look at draft data from 2002 onwards as none of the players from earlier drafts were still playing in the 2020-21 season.
library(DBI)
library(RSQLite)
library(tidyverse)
sql_file <- "basketball.sqlite"
# load the whole draft data frame
mydb <- dbConnect(SQLite(), sql_file)
draft_df <- dbGetQuery(mydb, "SELECT * FROM Draft")
dbDisconnect(mydb)
# get just the columns we want
draft_df <- draft_df %>%
select(year = yearDraft,
number_pick_overall = numberPickOverall,
player = namePlayer) %>%
filter(year >= 2002)
head(draft_df)
# year number_pick_overall player
# 1 2020 1 Anthony Edwards
# 2 2020 2 James Wiseman
# 3 2020 3 LaMelo Ball
# 4 2020 4 Patrick Williams
# 5 2020 5 Isaac Okoro
# 6 2020 6 Onyeka Okongwu
The next block gets the list of players for the 2020-21 season. We have to do some deduplication as players who play for multiple teams in the season have more than one row in the dataset.
players_file <- "nba_players_2020-21.csv" # read players file, just get unique player names players_df <- read.csv(players_file) players <- unique(players_df$Player) length(players) # [1] 540
Looks like there were 540 players who played in this season.
Cleaning and joining the data
The names of players weren’t consistent across the two datasets and so I had to do a bit of manual cleaning. The main inconsistency was for players with names that had accents on some letters. There were also a handful of differences due to suffixes and abbreviations.
There might be a better way to do this cleaning: I would love to hear if there are better alternatives! It’s also possible that I missed out some differences.
# some data wrangling to get player names to match across the two
# data sources
players <- gsub("ā", "a", players)
players <- gsub("ã", "a", players)
players <- gsub("á", "a", players)
players <- gsub("ć", "c", players)
players <- gsub("Č", "C", players)
players <- gsub("č", "c", players)
players <- gsub("é", "e", players)
players <- gsub("ģ", "g", players)
players <- gsub("ņ", "n", players)
players <- gsub("ó", "o", players)
players <- gsub("ò", "o", players)
players <- gsub("ö", "o", players)
players <- gsub("Š", "S", players)
players <- gsub("š", "s", players)
players <- gsub("ū", "u", players)
players <- gsub("ý", "y", players)
players <- gsub("ž", "z", players)
players <- gsub("Frank Mason III", "Frank Mason", players)
players <- gsub("J.J. Redick", "JJ Redick", players)
players <- gsub("Xavier Tillman Sr.", "Xavier Tillman", players)
df <- data.frame(player = players)
Let’s join the data:
joined_df <- df %>% left_join(draft_df, by = "player") head(joined_df) # player year number_pick_overall # 1 Precious Achiuwa 2020 20 # 2 Jaylen Adams NA NA # 3 Steven Adams 2013 12 # 4 Bam Adebayo 2017 14 # 5 LaMarcus Aldridge 2006 2 # 6 Ty-Shon Alexander NA NA
An NA in the number_pick_overall column means that the player was undrafted. The year column refers to the year the player was drafted.
Analysis
The first surprise I had was how many NBA players were undrafted:
sum(is.na(joined_df$number_pick_overall)) # [1] 145
145 out of 540 players, or almost 27% of players were undrafted! (It’s possible that the number is slightly smaller due to inadequate data cleaning on my part. If you spot any mistakes, let me know!)
The second surprise is how many drafted players are no longer playing in the NBA. The earliest drafted player in this dataset was in 2003 and the latest was in 2020, meaning that in this period, 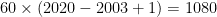
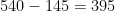
The percentage is still pretty low even if you restrict the computation to players drafted in the last 10 years. From 2011 to 2020, 600 players were drafted. From the code below, only 335 of them (about 56%) played in the 2020-21 season.
joined_df %>% filter(year >= 2011) %>% nrow() # [1] 335
Next, let’s make a plot of the number of players for each pick position. If the order of the draft means anything, we should see more players at higher pick positions (smaller numbers). That’s roughly what we see.
theme_set(theme_bw())
ggplot(joined_df) +
geom_bar(aes(x = number_pick_overall)) +
labs(x = "Pick number", y = "# of players",
title = "# of players who played in 2021-22 at each pick number")

Let’s look at the same histogram, except where we aggregate the draft position into groups of 5.
joined_df$pick_group <- (joined_df$number_pick_overall - 1) %/% 5 + 1
factor_levels <- paste(0:11 * 5 + 1, 1:12 * 5, sep = "-")
joined_df$pick_group <- factor(joined_df$pick_group, labels = factor_levels)
ggplot(filter(joined_df, !is.na(pick_group))) +
geom_bar(aes(x = pick_group)) +
labs(x = "Pick number", y = "# of players",
title = "# of players who played in 2021-22 at each pick number")

There’s a clear trend: there are fewer players at larger draft numbers as one might expect. The trend is clearly decreasing until roughly pick 31 onwards, which corresponds to the second round of the draft.
Here’s that same plot but with NAs (i.e. undrafted players) included:

Next, we have a scatterplot that shows the players who played in 2020-21 by their pick number and year drafted. There is no overplotting here (i.e. dots on top of each other) since there is exactly one player for each pick and year combination.
ggplot(joined_df) +
geom_point(aes(x = year, y = number_pick_overall)) +
labs(x = "Year", y = "Pick number",
title = "Players by pick number and year drafted")

As one might expect, players drafted earlier who are still playing in the league tend to have been picked early in the draft.
The thing about static plots is that it’s a bit hard to probe the data further. For example, upon seeing this chart, I was really interested in knowing which player each point corresponded to, especially those in the top-left corner (drafted low but have lasted in the NBA). The plotly package makes it easy to do this by providing data on the point when hovering over it. Unfortunately I can’t insert the plot in WordPress, but if you run the code below on your machine, you can get information just like the screenshot below the code.
library(plotly)
plot_ly(data = joined_df, x = ~year, y = ~number_pick_overall,
text = joined_df$player)

Finally let’s end off with list of #1 picks. 14 number one picks were still playing in the 2020-21 season. (Only one #1 in the last decade was not playing: Anthony Bennett from the 2013 draft.)
joined_df %>% filter(number_pick_overall == 1) %>% arrange(year) %>% select(player, year) # player year # 1 LeBron James 2003 # 2 Dwight Howard 2004 # 3 Derrick Rose 2008 # 4 Blake Griffin 2009 # 5 John Wall 2010 # 6 Kyrie Irving 2011 # 7 Anthony Davis 2012 # 8 Andrew Wiggins 2014 # 9 Karl-Anthony Towns 2015 # 10 Ben Simmons 2016 # 11 Markelle Fultz 2017 # 12 Deandre Ayton 2018 # 13 Zion Williamson 2019 # 14 Anthony Edwards 2020
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.