Introducing torch autograd
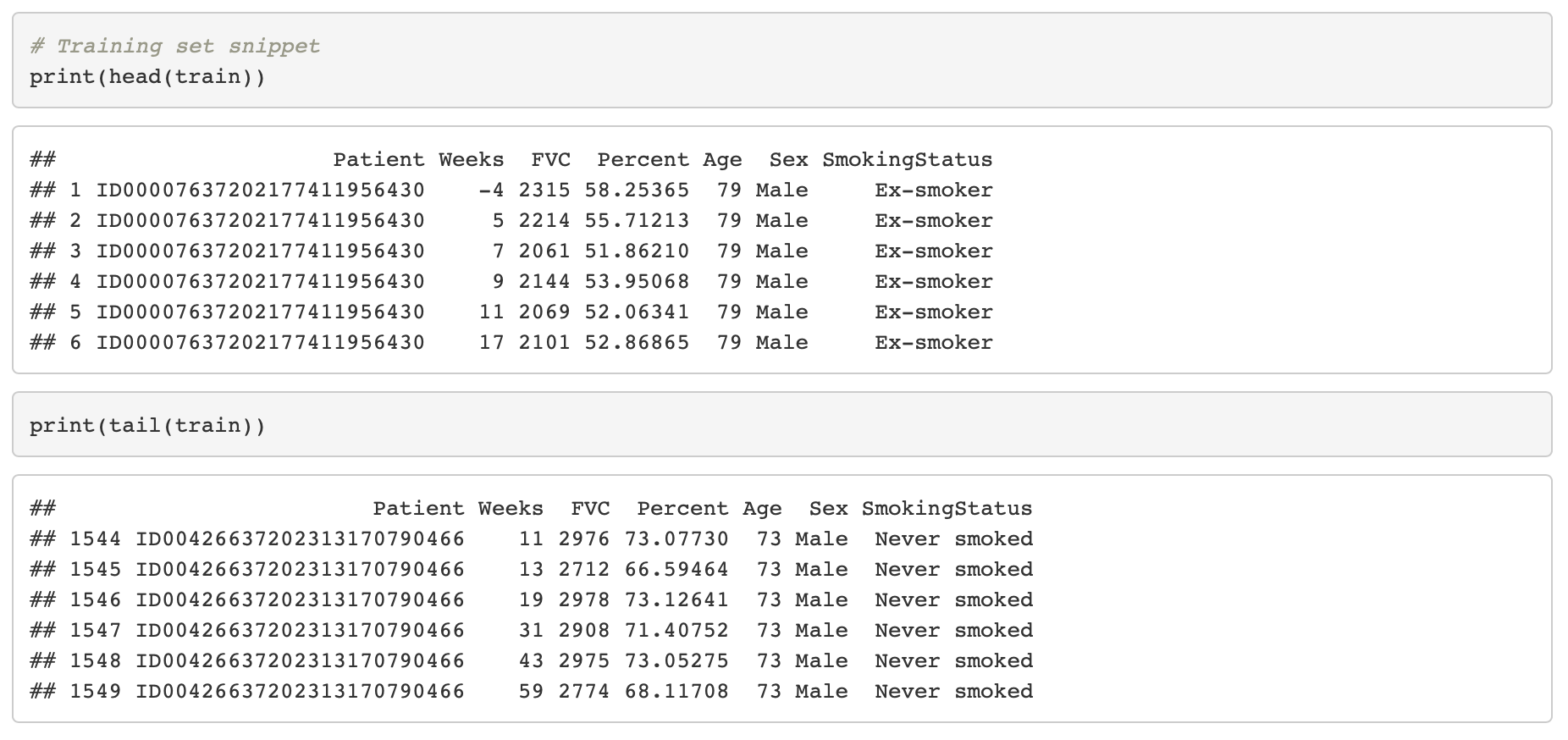
Last week, we saw how to code a simple network from scratch, using nothing but torch tensors. Predictions, loss, gradients, weight updates – all these things we’ve been computing ourselves. Today, we make a significant change: Namely, we spare ourse... [Read more...]