
Simulating Endogeneity
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Introduction The topic in this post is endogeneity, which can severely bias regression estimates. I will specifically simulate endogeneity caused by an omitted variable. In future posts in this series, I’ll simulate other specification issues such as heteroskedasticity, multicollinearity, and collider bias.
The Data-Generating Process
Consider the data-generating process (DGP) of some outcome variable 

")
For the simulation, I set parameter values for 




# simulation parameters set.seed(144); ss=500; trials=5000; a=50; b=.5; c=.01; d=25; h=.9; # generate two independent variables x=rnorm(n=ss,mean=1000,sd=50); z=d+h*x+rnorm(ss,0,10)
The Simulation
The simulation will estimate the two models below. The first model is correct in the sense that it includes all terms in the actual DGP. However, the second model omits a variable that is present in the DGP. Instead, the variable is obsorbed into the error term 
\thinspace Y = a+\beta x+c z + \epsilon_1")
 \thinspace Y = a+\beta x + \epsilon_1")
This second model will yield a biased estimator of 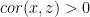
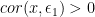
sim=function(endog){
# assume normal error with constant variance to start
e=rnorm(n=ss,mean=0,sd=10)
y=a+b*x+c*z+e
# Select data generation process
if(endog==TRUE){ fit=lm(y~x) }else{ fit=lm(y~x+z)}
return(fit$coefficients)
}
# run simulation - with and wihtout endogeneity
sim_results=t(replicate(trials,sim(endog=FALSE)))
sim_results_endog=t(replicate(trials,sim(endog=TRUE)))
Simulation Results This simulation yields two different sampling distributions for 
 Bias Analysis The bias in
Bias Analysis The bias in
\thinspace z = d+hx+\epsilon_2")
Substituting
 + \epsilon_1")
\thinspace Y = (a+cd)+(\beta+ch) x + (\epsilon_1+c\epsilon_2)")
When omitting variable 

 The derivation above also lets us determine the direction of bias from knowing the correlation of
The derivation above also lets us determine the direction of bias from knowing the correlation of 

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.