
Scraping Web Pages With R
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
One of the things I tend to avoid doing in R, partly because there are better tools elsewhere, is screenscraping. With the release of the new rvest package, I thought I’d have a go at what amounts to one of the simplest webscraping activites – grabbing HTML tables out of webpages.
The tables I had in my sights (when I can actually find them…) are the tables that appear on the newly designed FIA website that describe a range of timing results for F1 qualifying and races [quali example, race example].
Inspecting an example target web page, whilst a menu allows you to select several different results tables, a quick look at the underlying HTML source code reveals that all the tables relevant to the session (that is, a particular race, or complete qualifying session) are described within a single page.
So how can we grab those tables down from a target page? The following recipe seems to do the trick:
#install.packages("rvest")
library(rvest)
#URL of the HTML webpage we want to scrape
url="http://www.fia.com/events/formula-1-world-championship/season-2015/qualifying-classification"
fiaTableGrabber=function(url,num){
#Grab the page
hh=html(url)
#Parse HTML
cc=html_nodes(hh, xpath = "//table")[[num]] %>% html_table(fill=TRUE)
#TO DO - extract table name
#Set the column names
colnames(cc) = cc[1, ]
#Drop all NA column
cc=Filter(function(x)!all(is.na(x)), cc[-1,])
#Fill blanks with NA
cc=apply(cc, 2, function(x) gsub("^$|^ $", NA, x))
#would the dataframe cast handle the NA?
as.data.frame(cc)
}
#Usage:
#NUM:
## Qualifying:
### 1 CLASSIFICATION
### 2 BEST SECTOR TIMES
### 3 SPEED TRAP
### 4 MAXIMUM SPEEDS
##Race:
### 1 CLASSIFICATION
### 2 FASTEST LAPS
### 3 BEST SECTOR TIMES
### 4 SPEED TRAP
### 5 MAXIMUM SPEEDS
### 6 PIT STOPS
xx=fiaTableGrabber(url,NUM)
The fiaTableGrabber() grabs a particular table from a page with a particular URL (I really should grab the page separately and then extract whatever table from the fetched page, or at least cache the page (unless there is a cacheing option built-in?)
Depending on the table grabbed, we may then need to tidy it up. I hacked together a few sketch functions that tidy up (and remap) column names, convert “natural times” in minutes and seconds to seconds equivalent, and in the case of the race pits data, separate out two tables that get merged into one.
#1Q
fiaQualiClassTidy=function(xx){
for (q in c('Q1','Q2','Q3')){
cn=paste(q,'time',sep='')
xx[cn]=apply(xx[q],1,timeInS)
}
xx=dplyr:::rename(xx, Q1_laps=LAPS)
xx=dplyr:::rename(xx, Q2_laps=LAPS.1)
xx=dplyr:::rename(xx, Q3_laps=LAPS.2)
xx
}
#2Q, 3R
fiaSectorTidy=function(xx){
colnames(xx)=c('pos',
's1_driver','s1_nattime',
's2_driver','s2_nattime',
's3_driver','s3_nattime')
for (s in c('s1','s2','s3')) {
sn=paste(s,'_time',sep='')
sm=paste(s,'_nattime',sep='')
xx[sn]=apply(xx[sm],1,timeInS)
}
xx[-1,]
}
#3Q, 4R
fiaTrapTidy=function(xx){
xx
}
# 4Q, 5R
fiaSpeedTidy=function(xx){
colnames(xx)=c('pos',
'inter1_driver','inter1_speed',
'inter2_driver','inter2_speed',
'inter3_driver','inter3_speed')
xx[-1,]
}
# 2R
fiaRaceFastlapTidy=function(xx){
xx['time']=apply(xx['LAP TIME'],1,timeInS)
xx
}
# 6R
fiaPitsSummary=function(xx){
r=which(xx['NO']=='RACE - PIT STOP - DETAIL')
xx['tot_time']=apply(xx['TOTAL TIME'],1,timeInS)
Filter(function(x)!all(is.na(x)), xx[1:r-1,])
}
#6R
fiaPitsDetail=function(xx){
colnames(xx)=c('NO','DRIVER','LAP','TIME','STOP','NAT DURATION','TOTAL TIME')
xx['tot_time']=apply(xx['TOTAL TIME'],1,timeInS)
xx['duration']=apply(xx['NAT DURATION'],1,timeInS)
r=which(xx['NO']=='RACE - PIT STOP - DETAIL')
xx=xx[r+2:nrow(xx),]
#Remove blank row - http://stackoverflow.com/a/6437778/454773
xx[rowSums(is.na(xx)) != ncol(xx),]
}
So for example:
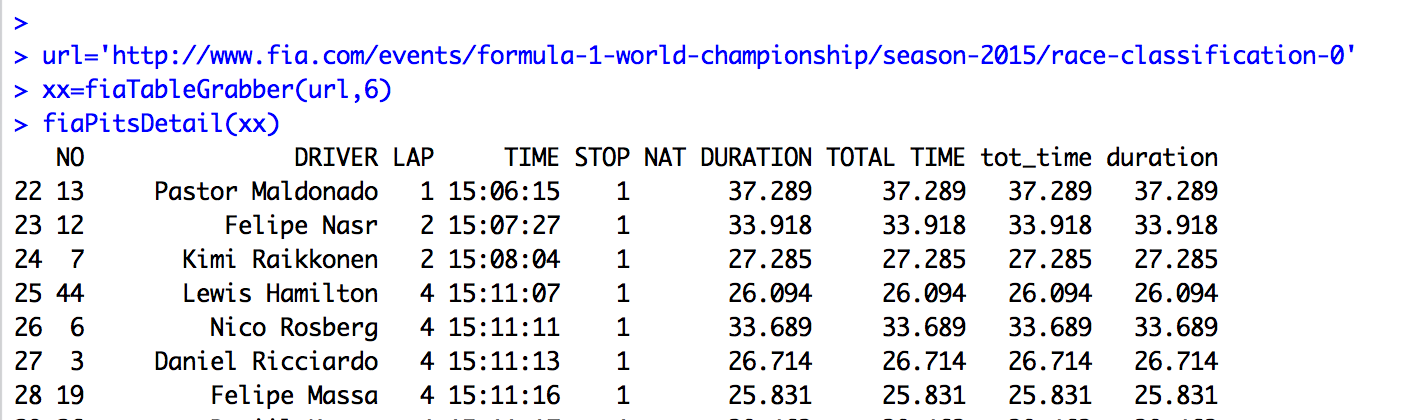
I’m still not convinced that R is the most natural, efficient, elegant or expressive language for scraping with, though…
PS In passing, I note the release of the readxl Excel reading library (no external-to-R dependencies, compatible with various flavours of Excel spreadsheet).
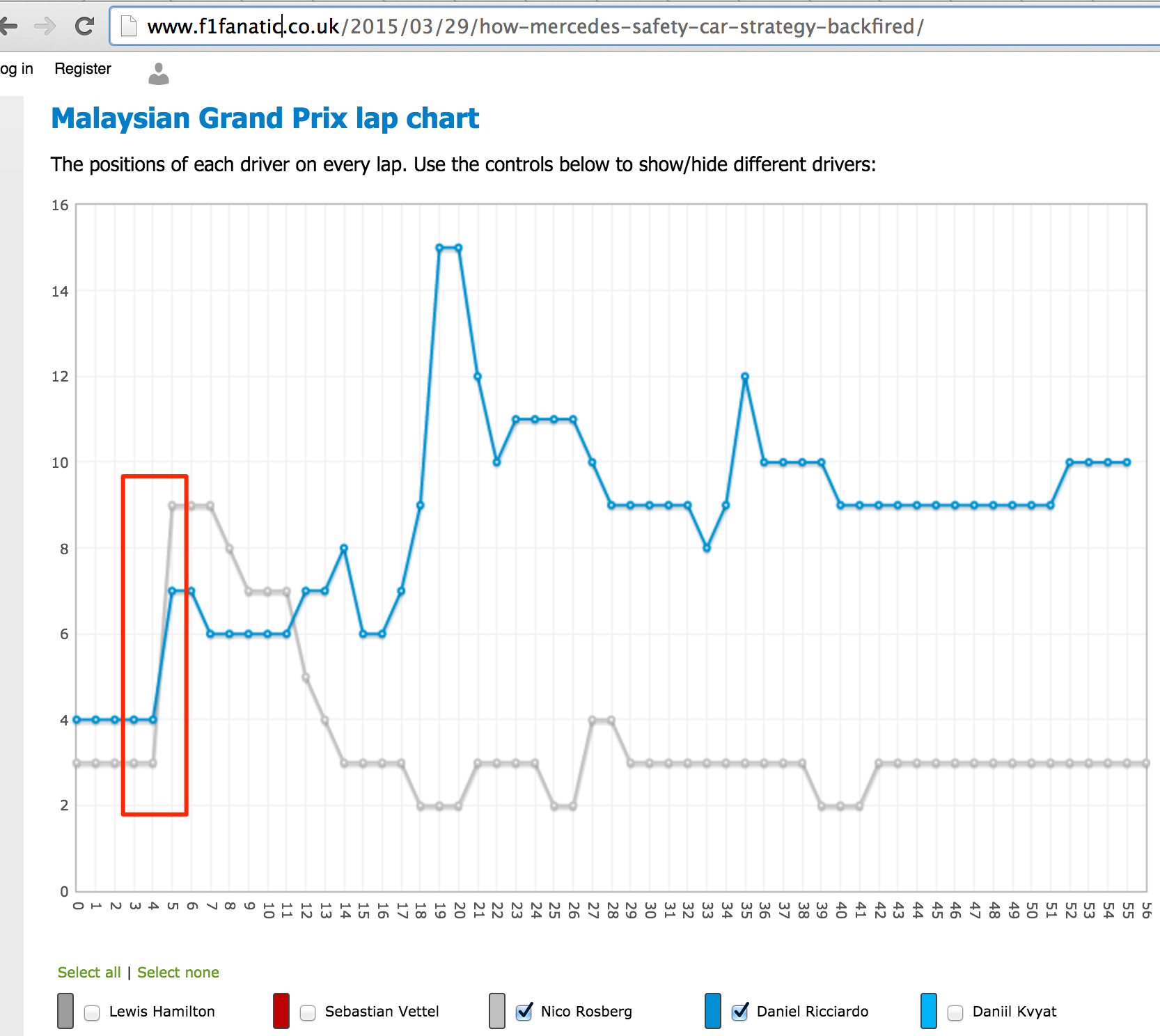
PPS Looking at the above screenshot, it strikes me that if we look at the time of day of and the duration, we can tell if there is a track position (at least) change in the pits… So for example, ROS goes in at 15:11:11 with a 33.689 stop and RIC goes in at 15:11:13 with a 26.714. So ROS enters the pits ahead of RIC and leaves after him? The following lap chart from f1fanatic perhaps reinforces this view?

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.