
Differences between Real and Fantasy Basketball in the NBA, Part I
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
In recent years, fantasy sports have become increasingly popular, and for sports enthusiasts and data analysts alike who can make the best predictions on which players to bet on, huge profits are reaped. Oftentimes, people think that using traditional sports authorities like ESPN is a reliable reference for fantasy betting. However, there are substantial differences between real and fantasy basketball, due to the fact that not all good players generate eye-catching statistics. Here, I will examine how different real and fantasy basketball can be, using R’s packages “dplyr and “ggvis” in a two-part blog post.
I will need to import 2 datasets from the following websites:
- (dataset name is “player” in code) Player stats for all players from the past year: http://www.basketball-reference.com/leagues/NBA_2016_per_game.html
- (dataset name is “ddtd” in code) Double-doubles and triple-doubles in the season: http://espn.go.com/nba/statistics/player/_/stat/double-doubles/sort/doubleDouble
From these datasets, I will calculate a player’s average worth per game in fantasy basketball and rank them,based on the scoring formats for the two most popular fantasy basketball websites, DraftKings and FanDuel. In the following post, I will compare these rankings with the third dataset, which has ESPN’s rankings of the most “efficient” players, to see discrepancies.
Let’s begin.
I open R studio and load the libraries I need.
library(dplyr) library(ggvis)
I then import my first two datasets to calculate a player’s worth in respective fantasy sites. To spare you the tedious part of cleaning the datasets, I will just past the code here and add minimal explanation as comments between the code blocks.
names(player) <- player[1,]
#This assigns names to columns of player dataset
for (i in 1: nrow(player)) {
if (toString(player[i,1]) == "Rk") {
player<- player[-i,]
}
}
#eliminates extra rows containing column names that we don't need
for (i in 1: nrow(ddtd)) {
if (toString(ddtd[i,1]) == "RK") {
ddtd <- ddtd[-i,]
}
}
#eliminates extra rows again in ddtd dataset
names(player)[12] <- "Threes"
#original column name is "3s" which is hard to reference in R
#this makes it easier to reference in future
player <- player %>% select(Player, G, Threes, TRB, AST, STL, BLK, TOV, PTS)
#select relevant columns
player$dd <- 0
player$td <- 0
ddtd <- ddtd %>% select(V2,V11,V12)
#prepares to merge ddtd and player dataset for calculation
row.names(player) <- 1:nrow(player)
row.names(ddtd) <- row.names(ddtd)
for (i in 1:nrow(ddtd)) {
for (j in 1:nrow(player)) {
if (strsplit (ddtd[i,1],",")[[1]][1] == player$Player[j]) {
player$dd[j] <- ddtd$V11[i]
player$td[j] <- ddtd$V12[i]
}
}
}
player$td[is.na(player$td)] <- 0
#merges player and ddtd dataset and removes NA's
for (i in 2:ncol(player)) {
player[,i] <- as.numeric(player[,i])
}
#converts entire dataset to numeric type for calculations
player <- player %>% mutate(tdd = dd/G, ttd = td/G)
#converts double-doubles and triple-doubles to a per game basis
player <- player %>% mutate(
dk = PTS + 0.5*Threes + 1.25*TRB + 1.5*AST + 2*STL + 2*BLK - 0.5*TOV + 1.5 * tdd + 3*ttd,
fd = PTS + 1.2*TRB + 1.5*AST + 2*STL + 2*BLK - TOV)
#calculates player's worth using DraftKing and FanDuel scoring
player <- player %>% arrange(desc(dk))
#rearranges dataset by players in descending value order
Here, the dataset “player” will look something like this
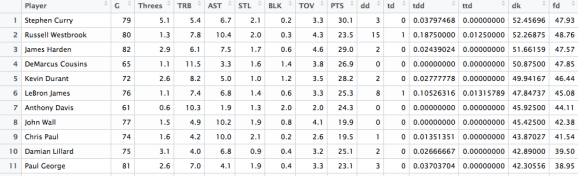
We can see each player’s worth in DraftKings here in the “dk” column. In addition, since the players are arranged in descending value order, we immediately see who are the most valuable players in the 2015-2016 season in fantasy basketball. Not surprising to Warrior fans, Stephen Curry is at the top of that list. In the next blog post, we will compare our results with ESPN’s rankings of who are the best players to see the differences.

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.