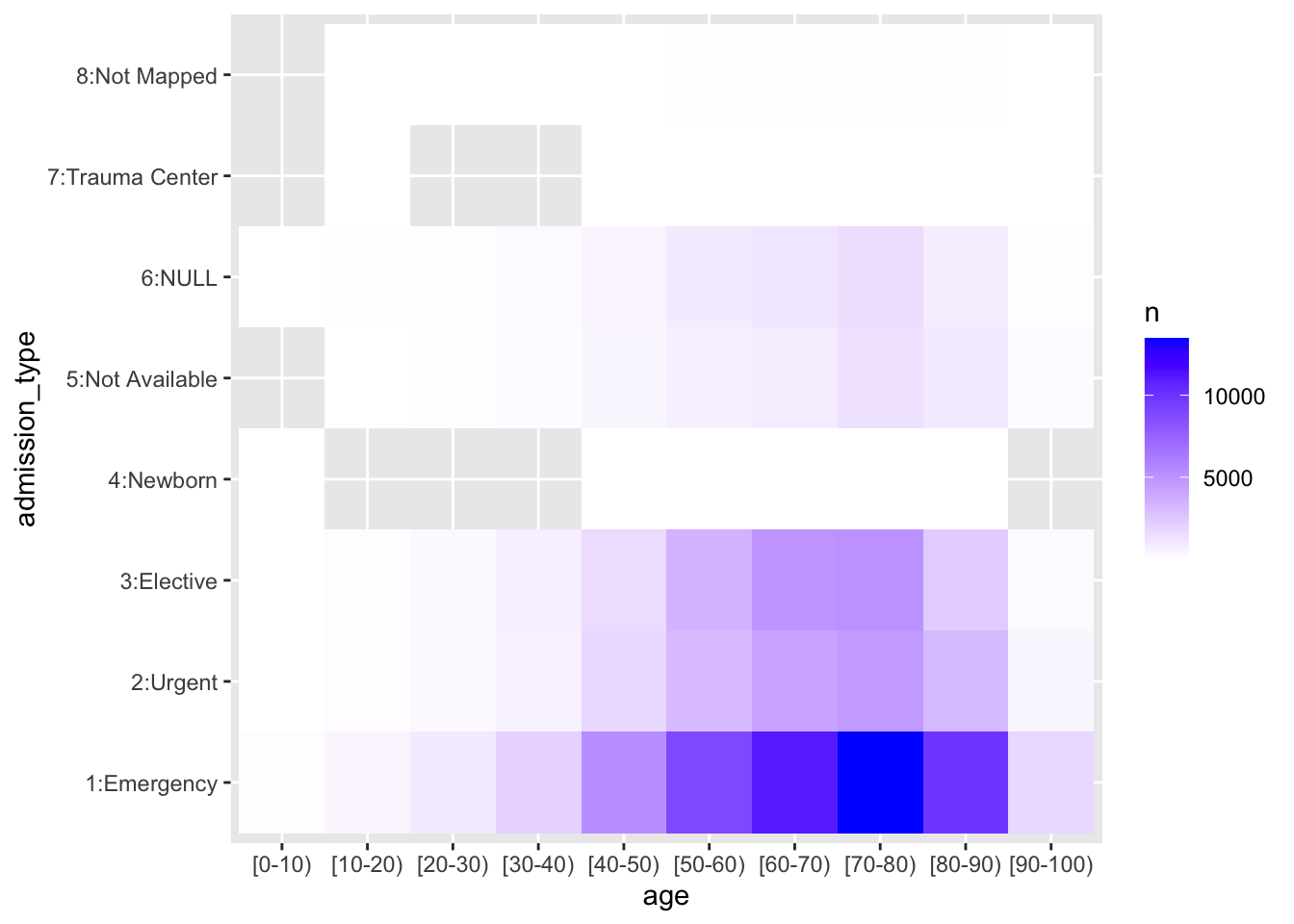
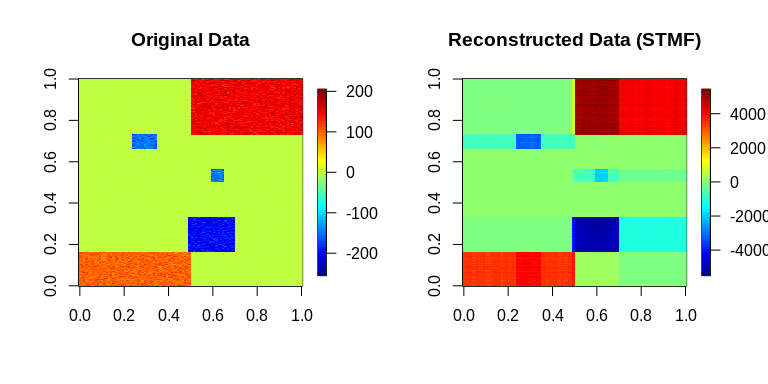
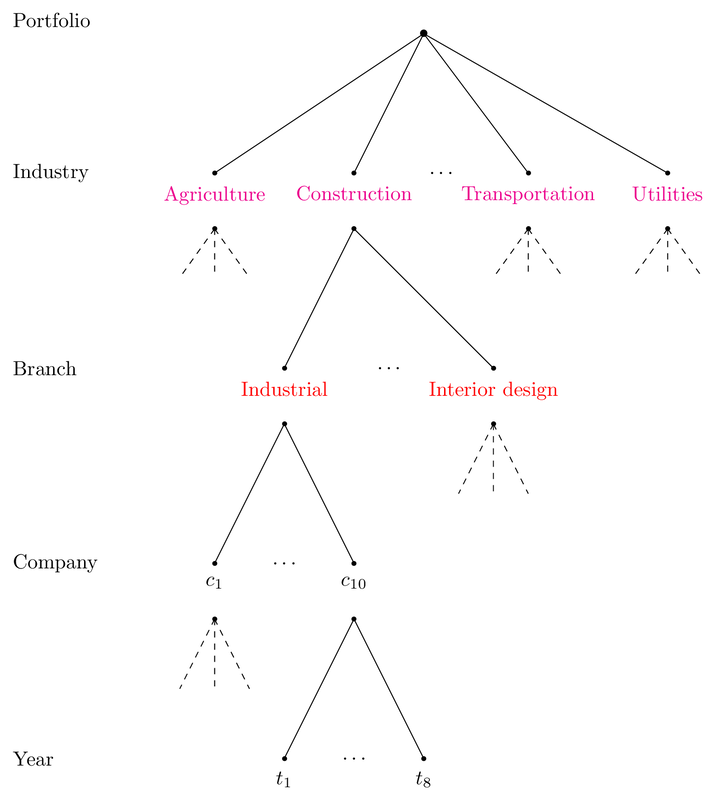
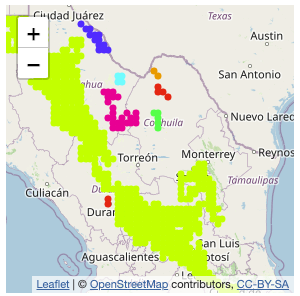
May 2023: “Top 40” New CRAN Packages
This will be my final R Views post offering my totally idiosyncratic selection of 40 CRAN packages. It has been a good run that began in August 2016. I would like to thank all of you who followed these posts. Your readership kept me going. I hope that the “Top 40” posts were ...