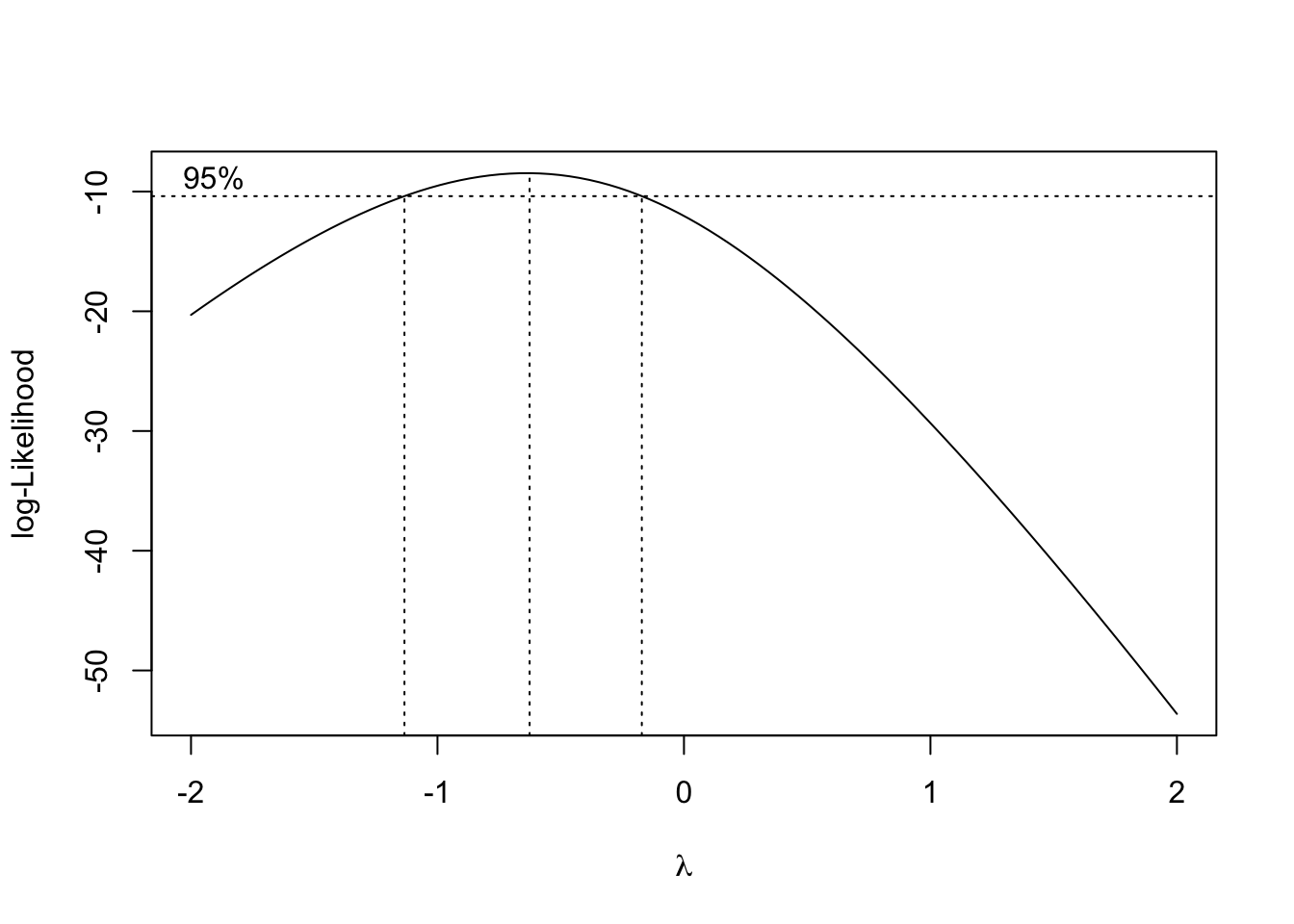
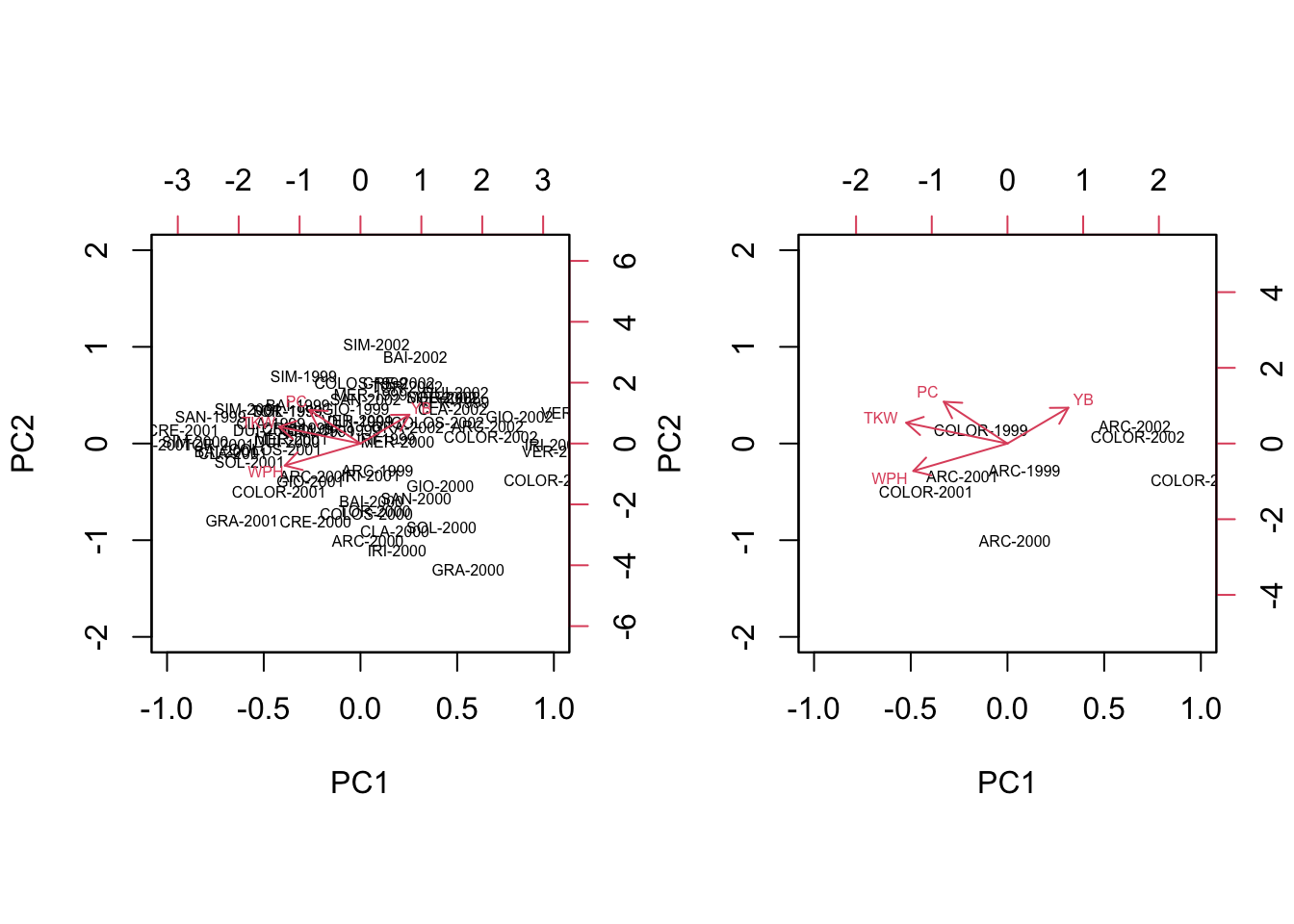
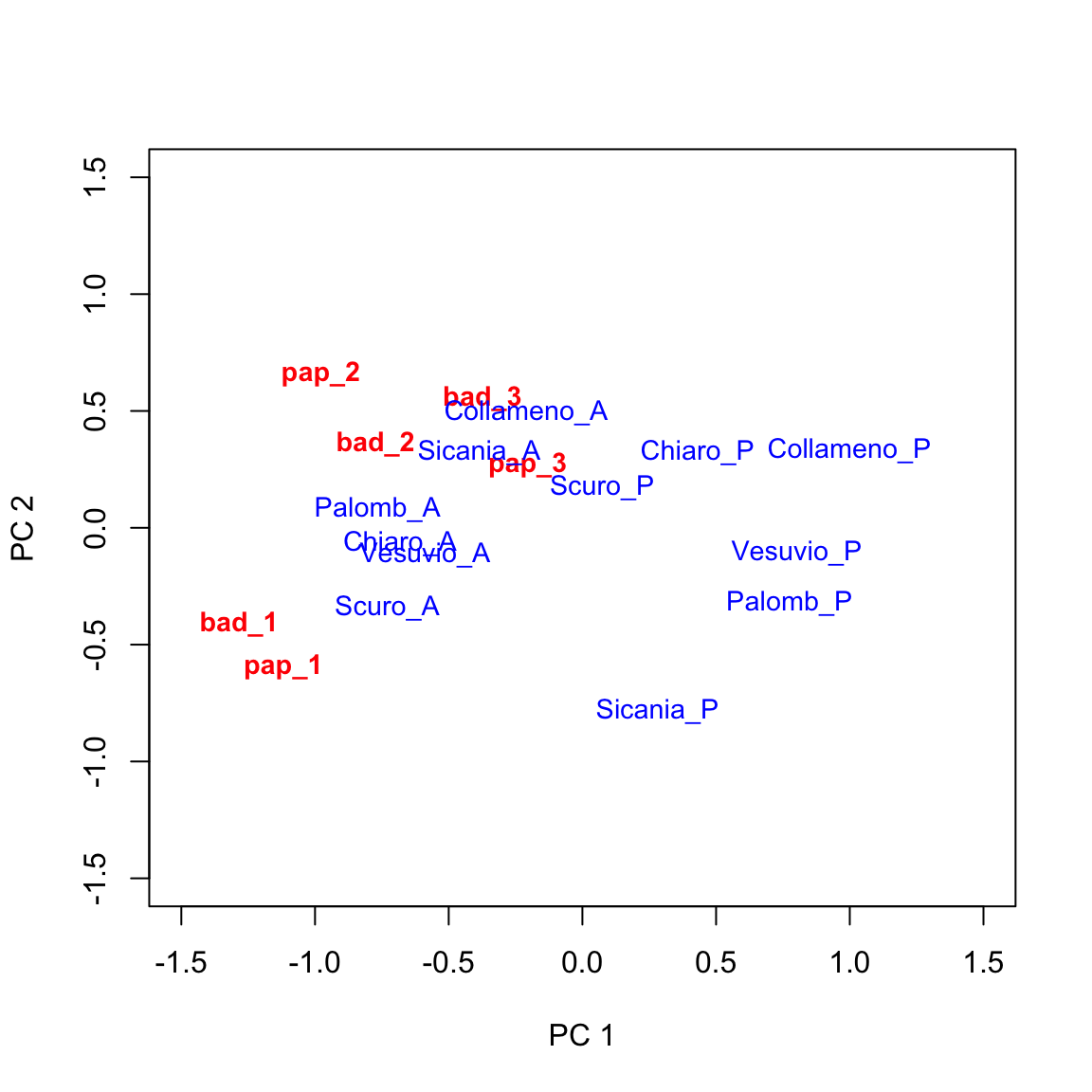
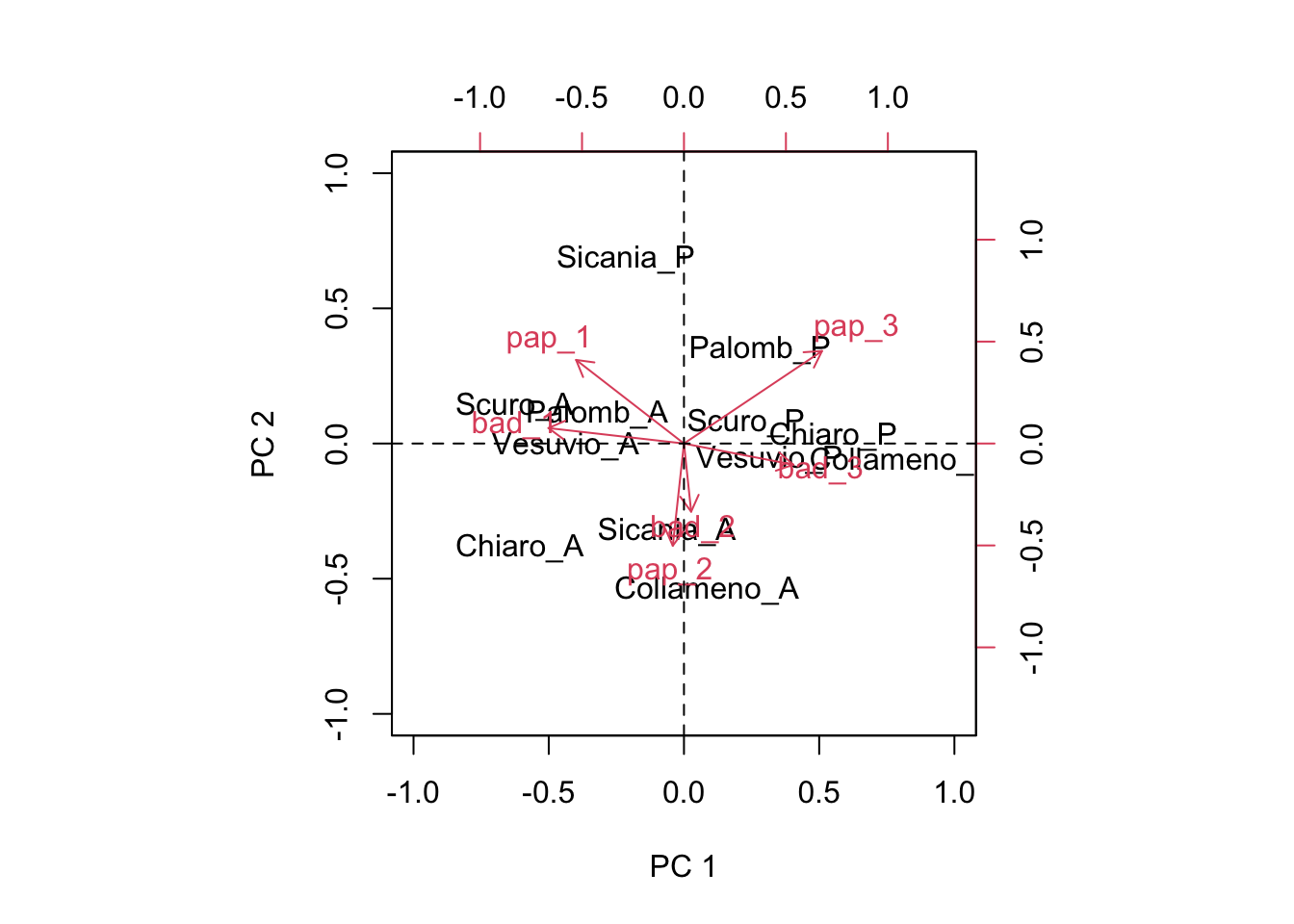
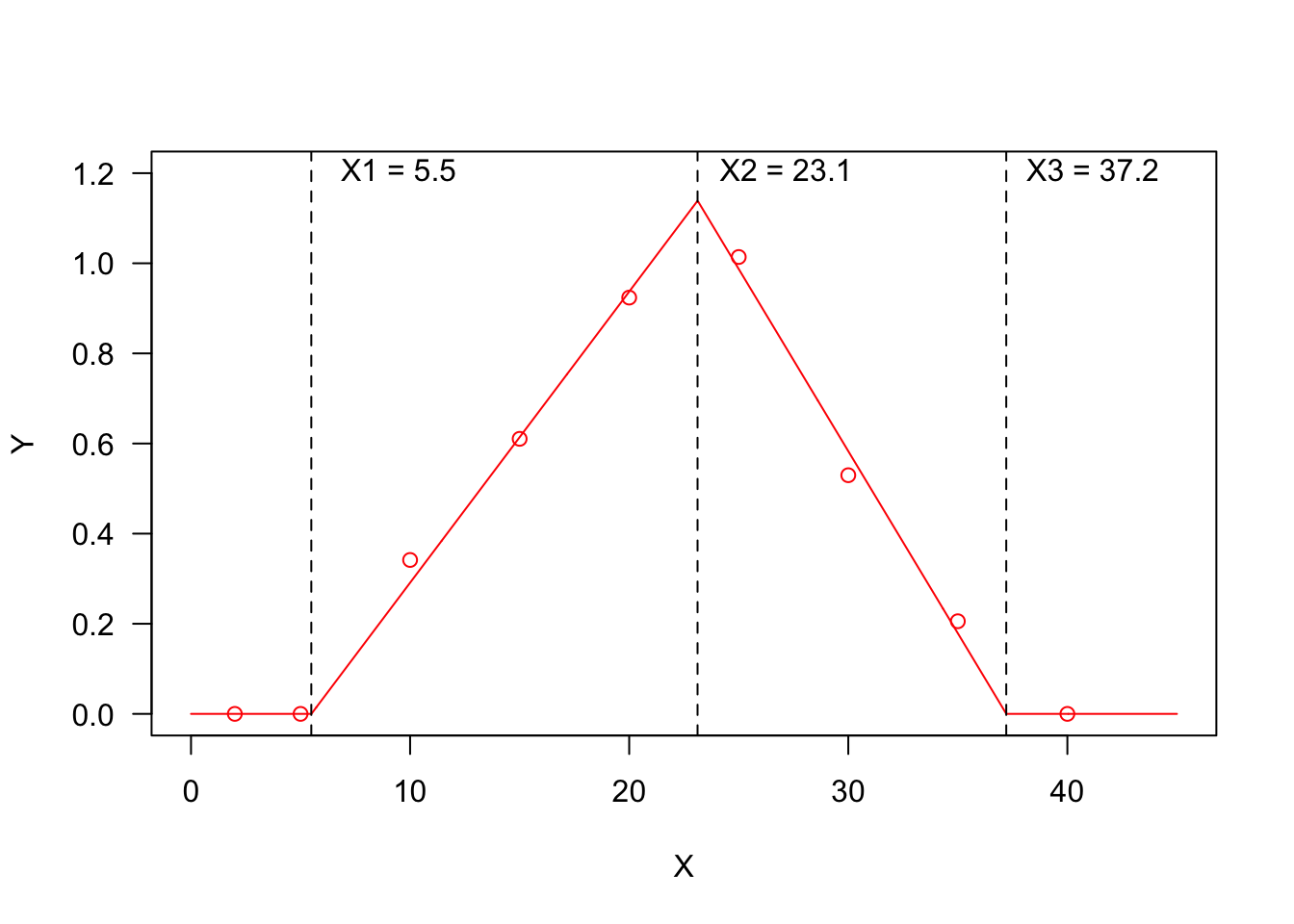
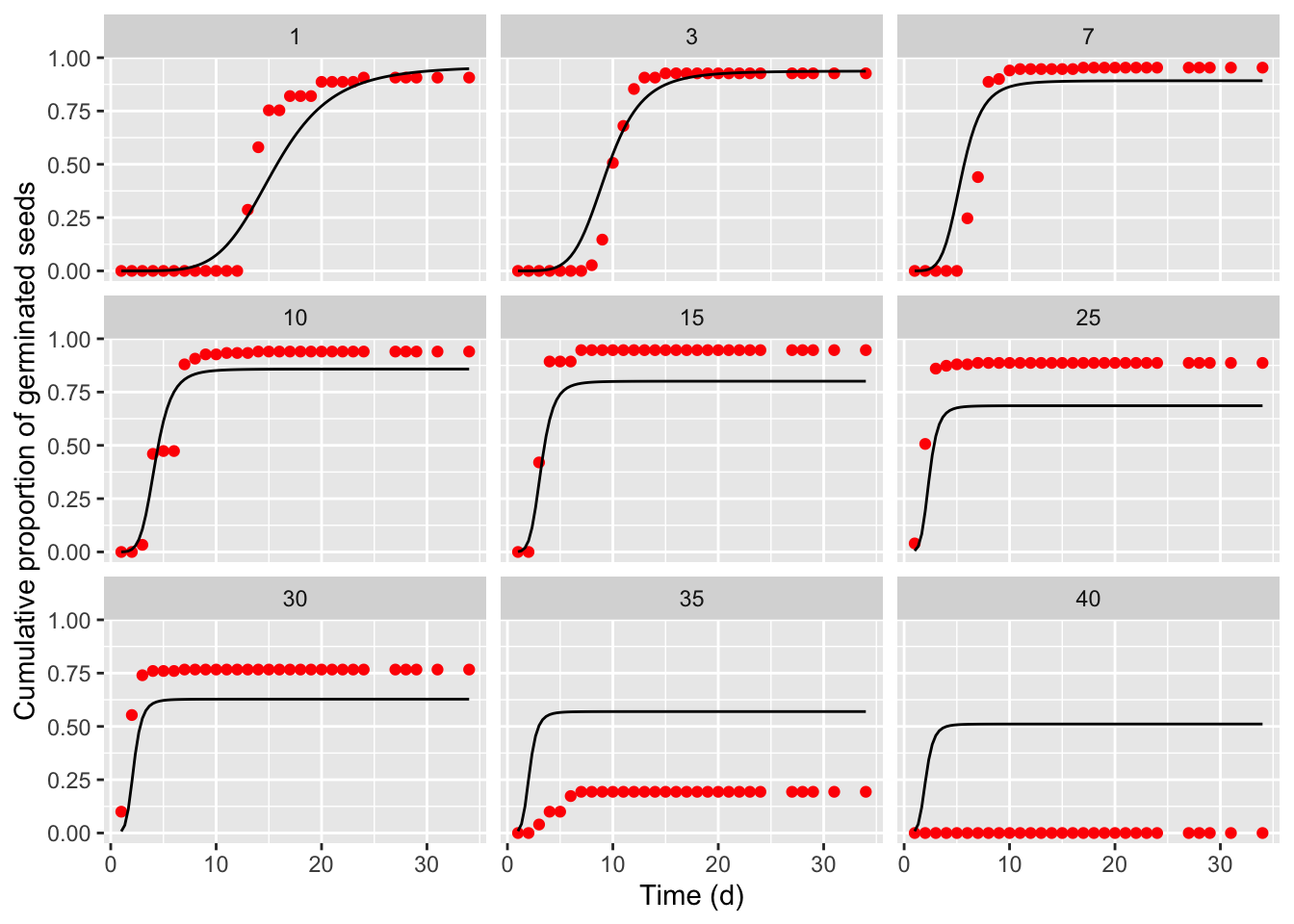
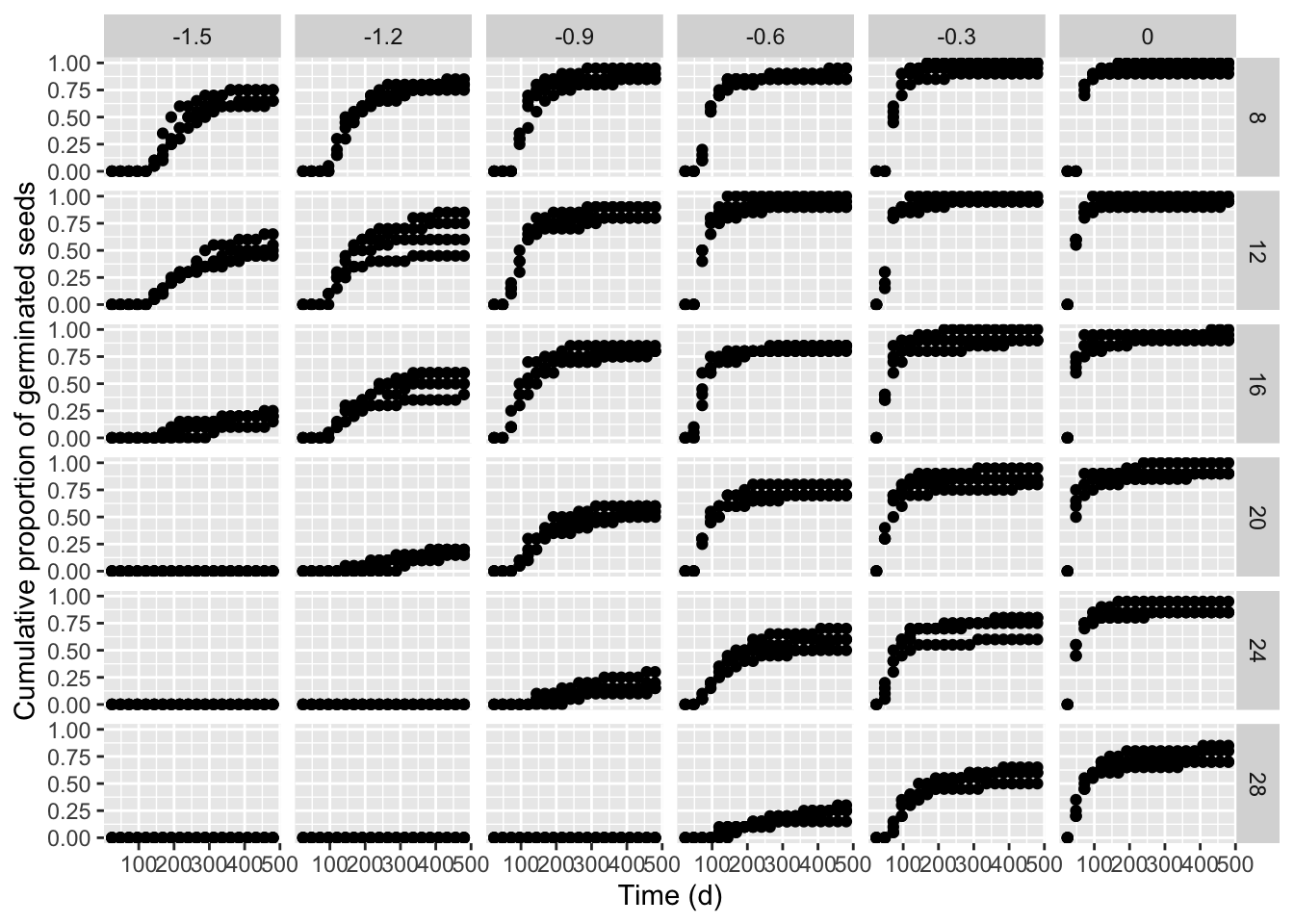
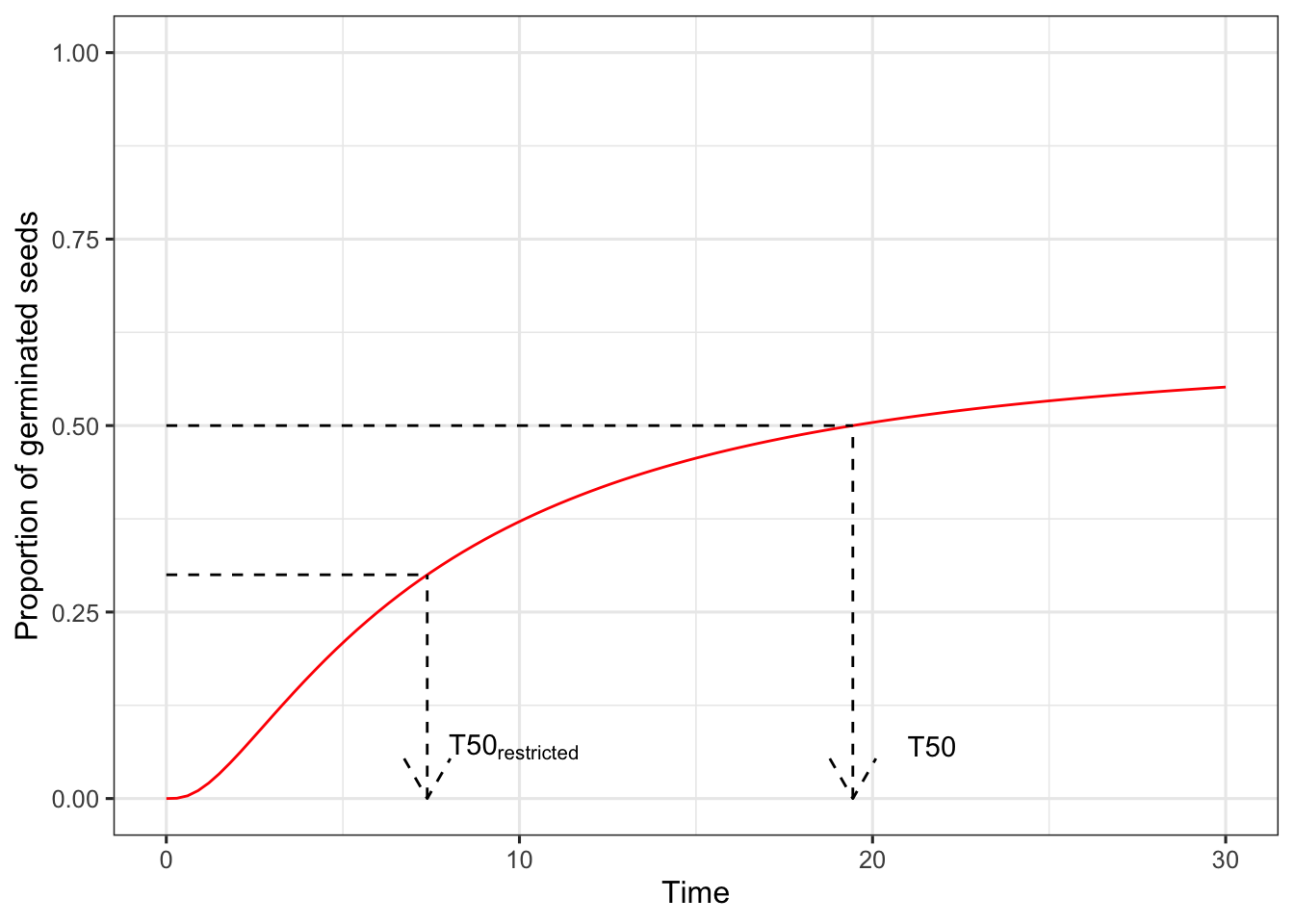
Pairwise comparisons in nonlinear regression
Pairwise comparisons are one of the most debated topic in agricultural research: they are very often used and, sometimes, abused, in literature. I have nothing against the appropriate use of this very useful technique and, for those who are interest... [Read more...]