Hierarchical forecasting of hospital admissions- ML approach (ensemble)
1. Recap
2 Tune again
Modelling
Retuning
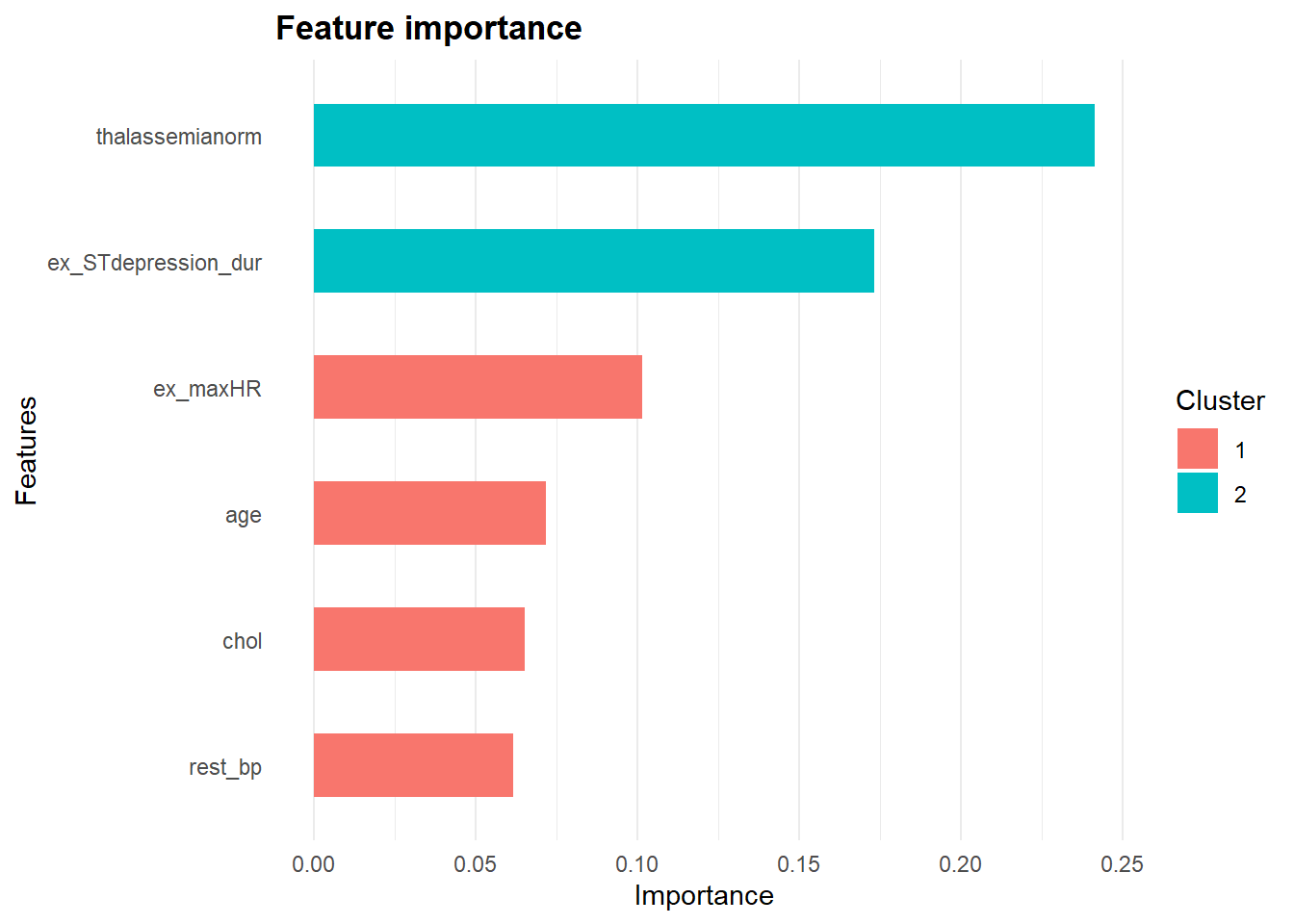
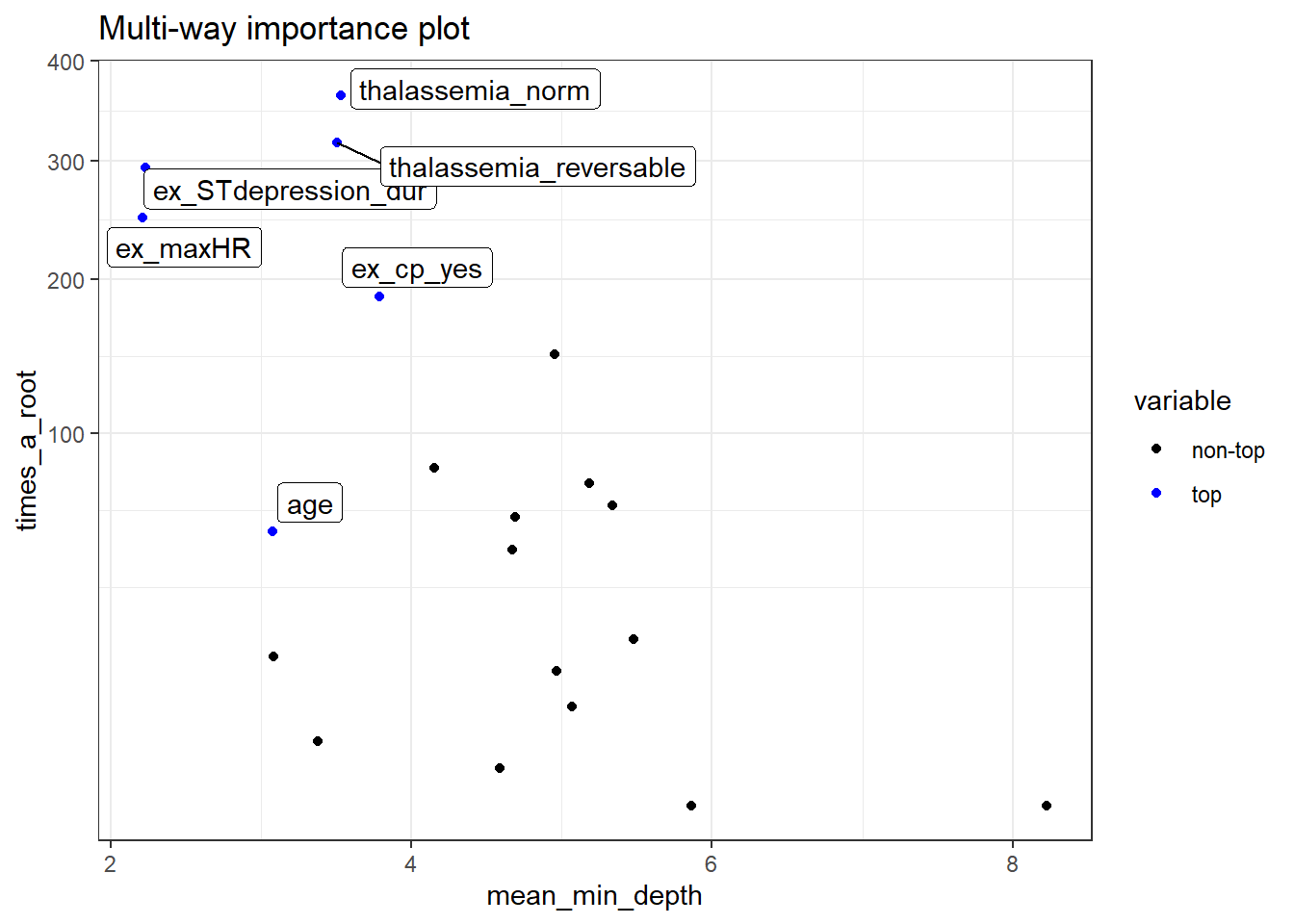
2.1 Retune Random Forest
2.2 Retune Prophet boost
2.3 Performance (after retuning)
3 Ensemble
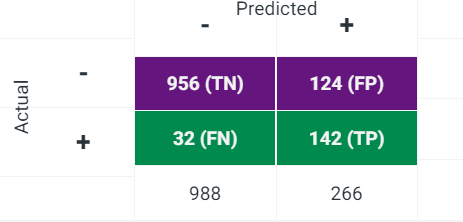
3.1 Peformance (ensemble)
4 Performance (individual levels)
Hospital
Cluster level
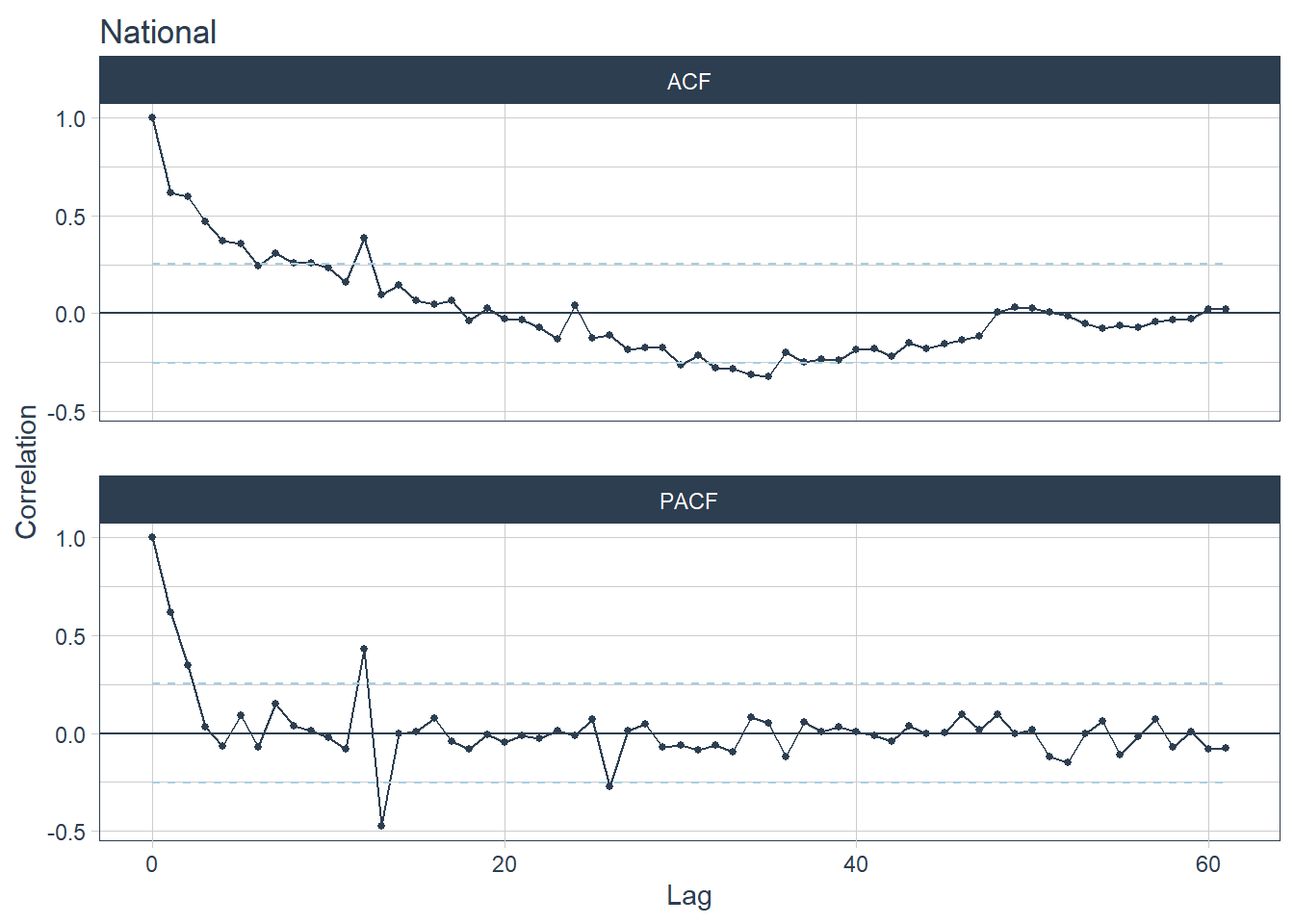
National level
5 The future
Hospital
Cluster
National
6 KIV Plans
Errors
1. Recap
The aim of this series of blog is to predict monthly admissions to Singapore public acute ...