All you need to know on Multiple Factor Analysis …
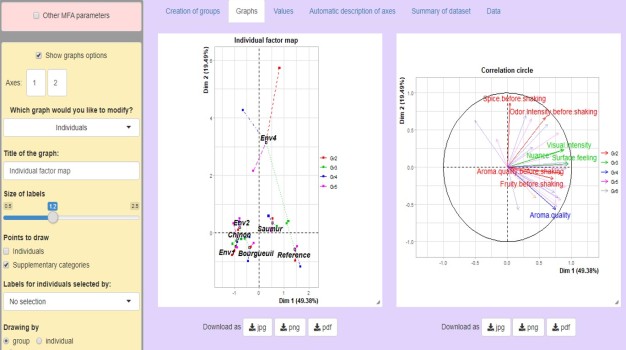
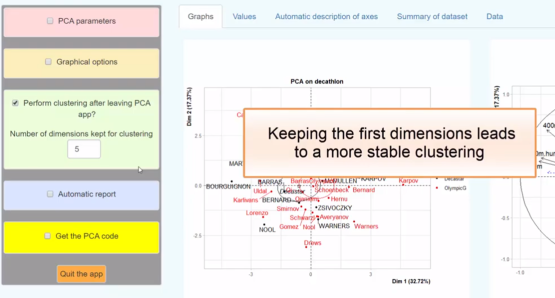
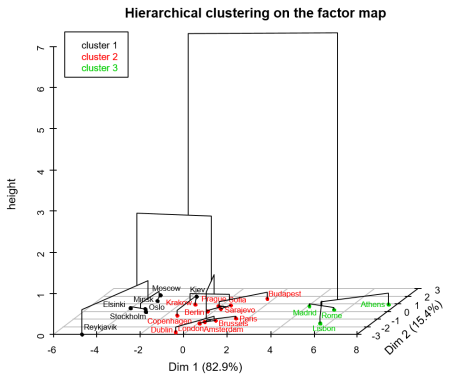
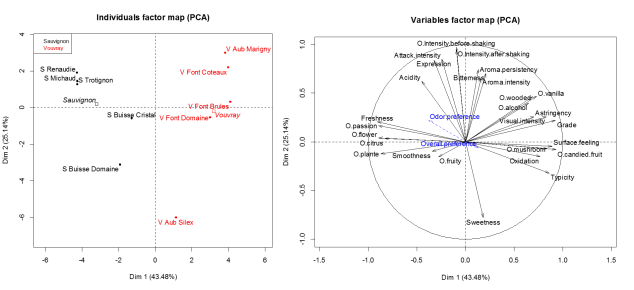
Multiple facrtor analysis deals with dataset where variables are organized in groups. Typically, from data coming from different sources of variables. The method highlights a common structure of all the groups, and the specificity of each group. It allows to compare the results of several PCAs or MCAs in a ...