
A Recession Before 2020 Is Likely; On the Distribution of Time Between Recessions
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I recently saw a Reddit thread in r/PoliticalDiscussion asking the question “If the economy is still booming 2020, how should the Democratic address this?” This gets to an issue that’s been on my mind since at least 2016, maybe even 2014: when will the current period of economic growth end?
For some context, the Great Recession, as economists colloquially call the recession beginning in 2007 and punctuated with the 2008 financial crisis, ended officially in June 2009; it was then the economy resumed growth. As of this writing, that was about eight years, ten months ago. The longest previous period between recessions was the time between the early 1990s recession and the recession in the early 2000s that coincided with the collapse of the dot-com bubble; that period was ten years, and the only period longer than the present period between recessions.
There is growing optimism in the economy, most noticeably amongst consumers, and we are finally seeing wages increase in the United States after years of stagnation. Donald Trump and Republicans point to the economy as a reason to vote for Republicans in November (and yet Donald Trump is still historically unpopular and Democrats have a strong chance of capturing the House, and a fair chance at the Senate). Followers of the American economy are starting to ask, “How long can this last?”
In 2016, I was thinking about this issue in relation to the election. I wanted Hillary Clinton to win, but at the same time I feared that a Clinton win would be a short-term gain, long-term loss for Democrats. One reason why is I believe there’s a strong chance of a recession within the next few years.
The 2008 financial crisis was a dramatic event, yet the Dodd-Frank reforms and other policy responses, in my opinion, did not go far enough to address the problems unearthed by the financial crisis. Too-big-to-fail institutions are now a part of law (though the policy jargon is systemically important financial institution, or SIFI). In fact, the scandal surrounding HSBC’s support of money laundering and the Justice Departments weak response suggested bankers may be too-big-to-jail! Many of the financial products and practices that caused the financial crisis are still legal; the fundamentals that produced the crisis have not changed. Barack Obama and the Democrats (and the Republicans, certainly) failed to break the political back of the bankers.
While I did not think Bernie Sanders’ reforms would necessarily make the American economy better, I thought he would put the fear of God back into the financial sector, and that alone could help keep risky behavior in check. Donald Trump, for all his populist rhetoric, has not demonstrated he’s going to put that fear in them. In fact, the Republicans passed a bill that’s a gift to corporations and top earners. The legacy of the 2008 financial crisis is that the financial sector can make grossly risky bets in the good “get government off our back!” times, but will have their losses covered by taxpayers in the “we need government help!” times. Recessions and financial crises are a part of the process of expropriating taxpayers. (I wrote other articles about this topic: see this article and this article, as well as this paper I wrote for an undergraduate class.)
Given all this, there’s good reason to believe that nothing has changed about the American economy that would change the likelihood of a financial crisis. Since it has been so long since the last one, it’s time to start expecting one, and whoever holds the Presidency will be blamed.
Right now that’s Donald Trump and the Republicans. And I don’t need to tell you that given Trump’s popularity in good economic times is historically low, a recession before the 2020 election would lead to a Republican rout, with few survivors.
And in a Census year, too!
So what is the probability of a recession? The rest of this article will focus on finding a statistical model for duration between elections and using that model to estimate the probability of a recession.
A recent article in the magazine Significance entitled “The Weibull distribution” describes the Weibull distribution, a common and expressive probability distribution (and one I recently taught in my statistics class). This distribution is used to model a lot of phenomena, including survival times, the time until a system fails or how long a patient diagnosed with a disease survives. Time until recession sounds like a “survival time”, so perhaps the Weibull distribution can be used to model it.
First, I’m going to be doing some bootstrapping, so here’s the seed for replicability:
set.seed(4182018)
The dataset below, obtained from this Wikipedia article, contains the time between recessions in the United States. I look only at recessions since the Great Depression, considering this to be the “modern” economic era for the United States. The sample size is necessarily small, at 13 observations.
recessions <- c( 4+ 2/12, 6+ 8/12, 3+ 1/12, 3+ 9/12, 3+ 3/12, 2+ 0/12,
8+10/12, 3+ 0/12, 4+10/12, 1+ 0/12, 7+ 8/12, 10+ 0/12,
6+ 1/12)
hist(recessions)

plot(density(recessions))

The fitdistrplus allows for estimating the parameters of statistical distributions using the usual statistical techniques. (I found J.Stat.Soft article useful for learning about the package.) I load it below and look at an initial plot to get a sense of appropriate distributions.
suppressPackageStartupMessages(library(fitdistrplus)) descdist(recessions, boot = 1000)

## summary statistics ## ------ ## min: 1 max: 10 ## median: 4.166667 ## mean: 4.948718 ## estimated sd: 2.71943 ## estimated skewness: 0.51865 ## estimated kurtosis: 2.349399
The recessions dataset is platykurtic though right-skewed, a surprising result. However, that’s not enough to deter me from attempting to use the Weibull distribution to model time between recessions. (I should mention here that I am assuming essentially that I’m assuming that time between recessions since the Great Depression are independent and identically distributed. This is not obvious or uncontroversial, but I doubt this could be credibly disproven or that assuming dependence would improve the model.) Let’s fit parameters.
fw <- fitdist(recessions, "weibull") summary(fw) ## Fitting of the distribution ' weibull ' by maximum likelihood ## Parameters : ## estimate Std. Error ## shape 2.001576 0.4393137 ## scale 5.597367 0.8179352 ## Loglikelihood: -30.12135 AIC: 64.2427 BIC: 65.3726 ## Correlation matrix: ## shape scale ## shape 1.0000000 0.3172753 ## scale 0.3172753 1.0000000
plot(seq(0, 15, length.out = 1000), dweibull(seq(0, 15, length.out = 1000),
shape = fw$estimate["shape"],
scale = fw$estimate["scale"]),
col = "blue", type = "l", xlab = "Duration", ylab = "Density",
main = "Weibull distribution applied to recession duration")
lines(density(recessions))

plot(fw)

The plots above suggest the fitted Weibull distribution describe the observed distribution; the Q-Q plot, P-P plot, and the estimated density function all fit well with a Weibull distribution. I also compared the AIC values of the fitted Weibull distribution to two other close candidates, the gamma and log-normal distributions; the Weibull distribution provides the best fit according to the AIC criterion, being twice as reasonable as the log-normal distribution, although only slightly better than the gamma distribution (which is not surprising, given that the two distributions are similar). Due to the interpretations that come with the Weibull distribution and the statistical evidence, I believe it provides the better fit and should be used.
Based on the form of the distribution and the estimated parameters we can find a point estimate for the probability of a recession both before the 2018 midterm election and before the 2020 presidential election. That is, if 
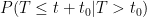
alpha <- fw$estimate["shape"]
beta <- fw$estimate["scale"]
recession_prob_wei <- function(delta, passed, shape, scale) {
# Computes the probability of a recession within the next delta years given
# passed years
#
# args:
# delta: a number representing time to next recession
# passed: a number representing time since last recession
# shape: the shape parameter of the Weibull distribution
# scale: the scale parameter of the Weibull distribution
if (delta < 0 | passed < 0) {
stop("Both delta and passed must be non-negative")
}
return(1 - pweibull(passed + delta, shape = shape, scale = scale,
lower.tail = FALSE) /
pweibull(passed, shape = shape, scale = scale, lower.tail = FALSE))
}
# Recession prob. before 2018 election point estimate recession_prob_wei(6/12, 8+10/12, shape = alpha, scale = beta) ## [1] 0.252013
# Before 2020 election recession_prob_wei(2+6/12, 8+10/12, shape = alpha, scale = beta) ## [1] 0.8005031
Judging by the point estimates, there’s a 25% chance of a recession before the 2018 midterm election and an 80% chance of a recession before the 2020 election.
The code below finds bootstrapped 95% confidence intervals for these numbers.
suppressPackageStartupMessages(library(boot))
recession_prob_wei_bootci <- function(data, delta, passed, conf = .95,
R = 1000) {
# Computes bootstrapped CI for the probability a recession will occur before
# a certain time given some time has passed
#
# args:
# data: A numeric vector containing recession data
# delta: A nonnegative real number representing maximum time till recession
# passed: A nonnegative real number representing time since last recession
# conf: A real number between 0 and 1; the confidence level
# R: A positive integer for the number of bootstrap replicates
bootobj <- boot(recessions, R = R, statistic = function(data, indices) {
d <- data[indices]
params <- fitdist(d, "weibull")$estimate
return(recession_prob_wei(delta, passed, shape = params["shape"],
scale = params["scale"]))
})
boot.ci(bootobj, type = "perc", conf = conf)
}
# Bootstrapped 95% CI for probability of recession before 2018 election
recession_prob_wei_bootci(recessions, 6/12, 8+10/12, R = 10000)
## BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
## Based on 10000 bootstrap replicates
##
## CALL :
## boot.ci(boot.out = bootobj, conf = conf, type = "perc")
##
## Intervals :
## Level Percentile
## 95% ( 0.1691, 0.6174 )
## Calculations and Intervals on Original Scale
# Bootstrapped 95% CI for probability of recession before 2020 election recession_prob_wei_bootci(recessions, 2+6/12, 8+10/12, R = 10000) ## BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS ## Based on 10000 bootstrap replicates ## ## CALL : ## boot.ci(boot.out = bootobj, conf = conf, type = "perc") ## ## Intervals : ## Level Percentile ## 95% ( 0.6299, 0.9974 ) ## Calculations and Intervals on Original Scale
These CIs suggest that while the probability of a recession before the 2018 midterm is very uncertain (it could plausibly be between 17% and 62%), my hunch about 2020 has validity; even the lower bound of that CI suggests a recession before 2020 is likely, and the upper bound is almost-certainty.
How bad could it be? That’s hard to say. However, these odds make the Republican tax bill and its trillion-dollar deficits look even more irresponsible; that money will be needed to deal with a potential recession’s fallout.
As bad as 2018 looks for Republicans, it could look like a cakewalk compared to 2020.
(And despite the seemingly jubilant tone, this suggests I may have trouble finding a job in the upcoming years.)
I have created a video course published by Packt Publishing entitled Data Acqusition and Manipulation with Python, the second volume in a four-volume set of video courses entitled, Taming Data with Python; Excelling as a Data Analyst. This course covers more advanced Pandas topics such as reading in datasets in different formats and from databases, aggregation, and data wrangling. The course then transitions to cover getting data in “messy” formats from Web documents via web scraping. The course covers web scraping using BeautifulSoup, Selenium, and Scrapy. If you are starting out using Python for data analysis or know someone who is, please consider buying my course or at least spreading the word about it. You can buy the course directly or purchase a subscription to Mapt and watch it there.
If you like my blog and would like to support it, spread the word (if not get a copy yourself)! Also, stay tuned for future courses I publish with Packt at the Video Courses section of my site.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.