
Advent of 2023, Day 10 – Creating Job Spark definition
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
n this Microsoft Fabric series:
- Dec 01: What is Microsoft Fabric?
- Dec 02: Getting started with Microsoft Fabric
- Dec 03: What is lakehouse in Fabric?
- Dec 04: Delta lake and delta tables in Microsoft Fabric
- Dec 05: Getting data into lakehouse
- Dec 06: SQL Analytics endpoint
- Dec 07: SQL commands in SQL Analytics endpoint
- Dec 08: Using Lakehouse REST API
- Dec 09: Building custom environments
An Apache Spark job definition is a single computational action, that is normally scheduled and triggered. In Microsoft Fabric (same as in Synapse), you could submit batch/streaming jobs to Spark clusters.
By uploading a binary file, or libraries in any of the languages (Java / Scala, R, Python), you can run any kind of logic (transformation, cleaning, ingest, ingress, …) to the data that is hosted and server to your lakehouse.
When creating a new Job Spark definition, you will get to the definition screen, where you upload the binary file(s)

My R script is just a toy example of how to read the delta table and append all the records to the same delta table. Important (!) Spark context (or session) must be initialized using the code for the Job definition to be successful (otherwise, the job fails). Still not sure, I understand why the context must be set additionally (??)
library(SparkR)
sparkR.session(master = "", appName = "SparkR", sparkConfig = list())
df_iris <- read.df("abfss://[email protected]/a574d1a3-xxxxxxxxx-7128f/Tables/iris_data")
head(df_iris)
#every run we append the whole delta table into itself
write.df(df_iris,
source = "delta",
path = "abfss://[email protected]/a574d1a3-xxxxxxxxx-7128f/Tables/iris_data",
mode = "append")
Do not forget to assign Lakehouse workspace to the job definition. Go to Lakehouse Reference and add the preferred Lakehouse.

Once you upload the file, you can schedule the job:
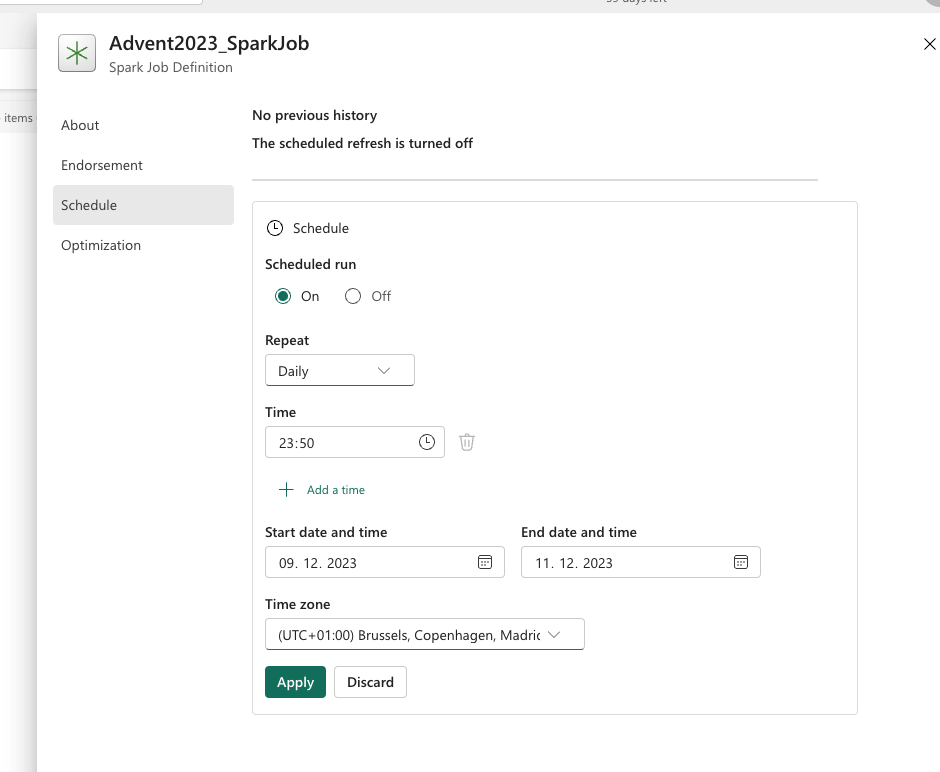
You can always test the job by running it and checking the results:
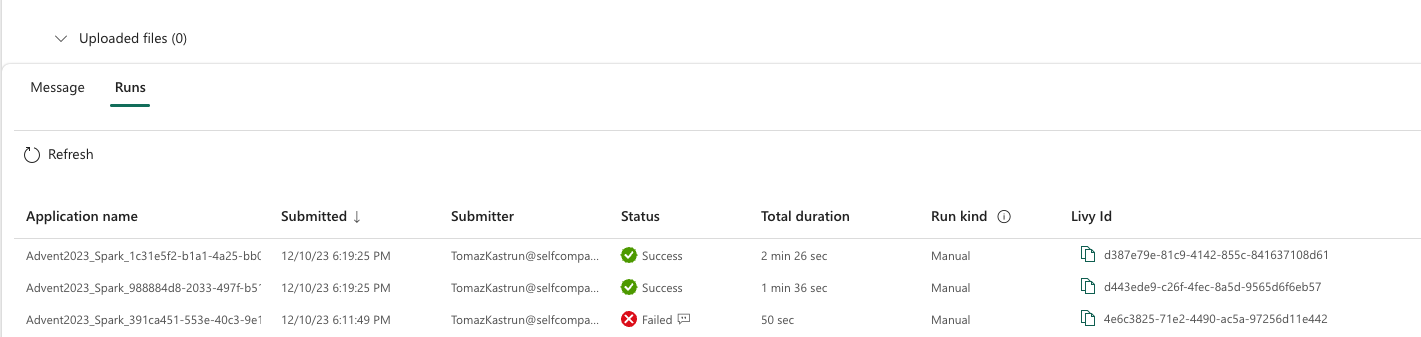
You can also deep dive into each Job run to get some additional information.
To check if the R code above was successful, I quickly opened a notebook and checked the number of rows (original 150) and we saw there were multiple rows added to the delta table.

Tomorrow we will look the exploring the data science part!
Complete set of code, documents, notebooks, and all of the materials will be available at the Github repository: https://github.com/tomaztk/Microsoft-Fabric
Happy Advent of 2023! ![]()
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.