
A Comparison of Several qeML Predictive Methods
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Is machine learning overrated, with traditional methods being underrated these days? Yes, ML has had some celebrated successes, but these have come after huge amounts of effort, and it’s possible that similar effort with traditional methods may have produced similar results.
A related issue concerns the type of data. Hard core MLers tend to divide applications into tabular and nontabular data. The former consists of the classical observations in rows, variables in columns format, while the latter means image processing, NLP and the like. The MLers’ prescription: use XGBoost for tabular data, deep learning (in some form) for the nontabular apps.
In this post, I’ll compare the performance of four predictive methods on a year 2000 census dataset svcensus, included with the qeML package. The comparison is just for illustration, not comprehensive by any means. For each method, I vary only one hyperparameter: k for qeKNN; minimum leaf size for qeRFranger; polynomial degree for qePolyLin; and max tree depth for qeXGBoost.
I used only the first 5000 rows of the dataset. There were 5 predictors, becoming 10 after categoricals were converted (internally) to dummies. The variable being predicted is wage income. For each hyperparameter value, 100 runs were done. (Recall: by default, qeML predictive functions form a random holdout set.)
15 hyperparameter values were tried for each method. In the case of qeKNN and qeRFranger, these were seq(5,75,5). For the other two methods, the values were 1:15.
Here are the results:
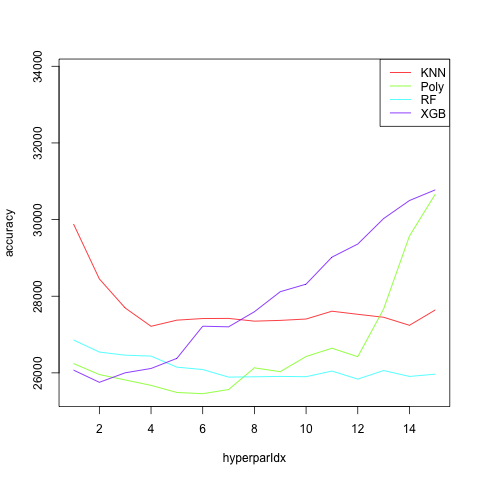
The winner here turned out to be good ol’ polynomial regression. Obviously overfitting occurs, but somewhat surprisingly, only after degree 6 or so. Random forests seems to have leveled off at 60 or so. All might do better by tweaking other default hyperparameters, especially KNN.
Of course, all the methods here could be considered traditional statistical methods, as all had significant statistician contribution. But only polynomial regression is truly traditional, and it’s interesting to see that it prevailed in this case.
From now on, I plan to make code for my blog posts available in my qeML repo, https://github.com/matloff/qeML in the inst/blogs subdirectory. So, readers can conveniently try their own experiments.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.