
Notes on Linear Algebra Part 4
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Back in Part 2 I mentioned some of the challenges of learning linear algebra. One of those challenges is making sense of all the special types of matrices one encounters. In this post I hope to shed a little light on that topic.
A Taxonomy of Matrices
I am strongly drawn to thinking in terms of categories and relationships. I find visual presentations like phylogenies showing the relationships between species very useful. In the course of my linear algebra journey, I came across an interesting Venn diagram developed by the very creative thinker Kenji Hiranabe. The diagram is discussed at Matrix World, but the latest version is at the Github link. A Venn diagram is a useful format, but I was inspired to recast the information in different format. Figure 1 shows a taxonomy I created using a portion of the information in Hiranabe’s Venn diagram.1 The taxonomy is primarily organized around what I am calling the structure of a matrix: what does it look like upon visual inspection? Of course this is most obvious with small matrices. To me at least, structure is one of the most obvious characteristics of a matrix: an upper triangular matrix really stands out for instance. Secondarily, the taxonomy includes a number of queries that one can ask about a matrix: for instance, is the matrix invertible? We’ll need to expand on all of this of course, but first take a look at the figure.2
flowchart TD
A(all matrices <br/> n x m) --> C(row matrices <br/> 1 x n)
A --> D(column matrices <br/> n x 1)
A ---> B(square matrices <br/> n x n)
B --> E(upper triangular<br/>matrices)
B --> F(lower triangular<br/>matrices)
B --> G{{<b>either</b><br/>is singular?}}
B --> H{{<b>or</b><br/>is invertible?}}
H --> I{{is diagonalizable?}}
I --> J{{is normal?}}
J --> K(symmetric)
K --> L(diagonal)
L --> M(identity)
J --> N{{is orthogonal?}}
N --> M
style G fill:#FFF0F5
style H fill:#FFF0F5
style I fill:#FFF0F5
style J fill:#FFF0F5
style N fill:#FFF0F5
Touring the Taxonomy
Structure Examples
Let’s use R to construct and inspect examples of each type of matrix. We’ll use integer matrices to keep the print output nice and neat, but of course real numbers could be used as well.3 Most of these are pretty straightforward so we’ll keep comments to a minimum for the simple cases.
Rectangular Matrix 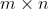
A_rect <- matrix(1:12, nrow = 3) # if you give nrow, A_rect # R will compute ncol from the length of the data
[,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 2 5 8 11 [3,] 3 6 9 12
Notice that R is “column major” meaning data fills the first column, then the second column and so forth.
Row Matrix/Vector 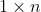
A_row <- matrix(1:4, nrow = 1) A_row
[,1] [,2] [,3] [,4] [1,] 1 2 3 4
Column Matrix/Vector 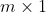
A_col <- matrix(1:4, ncol = 1) A_col
[,1] [1,] 1 [2,] 2 [3,] 3 [4,] 4
Keep in mind that to save space in a text-dense document one would often write A_col as its transpose.4
Square Matrix 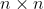
A_sq <- matrix(1:9, nrow = 3) A_sq
[,1] [,2] [,3] [1,] 1 4 7 [2,] 2 5 8 [3,] 3 6 9
Upper and Lower Triangular Matrices
Creating an upper triangular matrix requires a few more steps. Function upper.tri() returns a logical matrix which can be used as a mask to select entries. Function lower.tri() can be used similarly. Both functions have an argument diag = TRUE/FALSE indicating whether to include the diagonal.5
upper.tri(A_sq, diag = TRUE)
[,1] [,2] [,3] [1,] TRUE TRUE TRUE [2,] FALSE TRUE TRUE [3,] FALSE FALSE TRUE
A_upper <- A_sq[upper.tri(A_sq)] # gives a logical matrix A_upper # notice that a vector is returned, not quite what might have been expected!
[1] 4 7 8
A_upper <- A_sq # instead, create a copy to be modified A_upper[lower.tri(A_upper)] <- 0L # assign the lower entries to zero A_upper
[,1] [,2] [,3] [1,] 1 4 7 [2,] 0 5 8 [3,] 0 0 9
Notice to create an upper triangular matrix we use lower.tri() to assign zeros to the lower part of an existing matrix.
Identity Matrix
If you give diag() a single value it defines the dimensions and creates a matrix with ones on the diagonal, in other words, an identity matrix.
A_ident <- diag(4) A_ident
[,1] [,2] [,3] [,4] [1,] 1 0 0 0 [2,] 0 1 0 0 [3,] 0 0 1 0 [4,] 0 0 0 1
Diagonal Matrix
If instead you give diag() a vector of values these go on the diagonal and the length of the vector determines the dimensions.
A_diag <- diag(1:4) A_diag
[,1] [,2] [,3] [,4] [1,] 1 0 0 0 [2,] 0 2 0 0 [3,] 0 0 3 0 [4,] 0 0 0 4
Symmetric Matrices
Matrices created by diag() are symmetric matrices, but any matrix where is symmetric. There is no general function to create symmetric matrices since there is no way to know what data should be used. However, one can ask if a matrix is symmetric, using the function
isSymmetric().
isSymmetric(A_diag)
[1] TRUE
The Queries
Let’s take the queries in the taxonomy in order, as the hierarchy is everything.
Is the Matrix Singular or Invertible?
A singular matrix is one in which one or more rows are multiples of another row, or alternatively, one or more columns are multiples of another column. Why do we care? Well, it turns out a singular matrix is a bit of a dead end, you can’t do much with it. An invertible matrix, however, is a very useful entity and has many applications. What is an invertible matrix? In simple terms, being invertible means the matrix has an inverse. This is not the same as the algebraic definition of an inverse, which is related to division:
Instead, for matrices, invertibility of is defined as the existence of another matrix
such that
Just as cancels out
in
,
cancels out
to give the identity matrix. In other words,
is really
.
A singular matrix has determinant of zero. On the other hand, an invertible matrix has a non-zero determinant. So to determine which type of matrix we have before us, we can simply compute the determinant.
Let’s look at a few simple examples.
A_singular <- matrix(c(1, -2, -3, 6), nrow = 2, ncol = 2) A_singular # notice that col 2 is col 1 * -3, they are not independent
[,1] [,2] [1,] 1 -3 [2,] -2 6
det(A_singular)
[1] 0
A_invertible <- matrix(c(2, 2, 7, 8), nrow = 2, ncol = 2) A_invertible
[,1] [,2] [1,] 2 7 [2,] 2 8
det(A_invertible)
[1] 2
Is the Matrix Diagonalizable?
A matrix that is diagonalizable can be expressed as:
where is a diagonal matrix – the diagonalized version of the original matrix
. How do we find out if this is possible, and if possible, what are the values of
and
? The answer is to decompose
using the eigendecomposition:
Now there is a lot to know about the eigendecomposition, but for now let’s just focus on a few key points:
- The columns of
contains the eigenvectors. Eigenvectors are the most natural basis for describing the data in
.6
is a diagonal matrix with the eigenvalues on the diagonal, in descending order. The individual eigenvalues are typically denoted
.
- Eigenvectors and eigenvalues always come in pairs.
We can answer the original question by using the eigen() function in R. Let’s do an example.
A_eigen <- matrix(c(1, 0, 2, 2, 3, -4, 0, 0, 2), ncol = 3) A_eigen
[,1] [,2] [,3] [1,] 1 2 0 [2,] 0 3 0 [3,] 2 -4 2
eA <- eigen(A_eigen) eA
eigen() decomposition
$values
[1] 3 2 1
$vectors
[,1] [,2] [,3]
[1,] 0.4082483 0 0.4472136
[2,] 0.4082483 0 0.0000000
[3,] -0.8164966 1 -0.8944272
Since eigen(A_eigen) was successful, we can conclude that A_eigen was diagonalizable. You can see the eigenvalues and eigenvectors in the returned value. We can reconstruct A_eigen using Equation 4:
eA$vectors %*% diag(eA$values) %*% solve(eA$vectors)
[,1] [,2] [,3] [1,] 1 2 0 [2,] 0 3 0 [3,] 2 -4 2
Remember, diag() creates a matrix with the values along the diagonal, and solve() computes the inverse when it gets only one argument.
The only loose end is which matrices are not diagonalizable? These are covered in this Wikipedia article. Briefly, most non-diagonalizable matrices are fairly exotic and real data sets will likely not be a problem.
In texts, eigenvalues and eigenvectors are universally introduced as a scaling relationship
where is a column eigenvector and
is a scalar eigenvalue. One says “
scales
by a factor of
.” A single vector is used as one can readily illustrate how that vector grows or shrinks in length when multiplied by
. Let’s call this the “bottom up” explanation.
Let’s check that is true using our values from above by extracting the first eigenvector and eigenvalue from eA. Notice that we are using regular multiplication on the right-hand-side, i.e. *, rather than %*%, because eA$values[1] is a scalar. Also on the right-hand-side, we have to add drop = FALSE to the subsetting process or the result is no longer a matrix.7
isTRUE(all.equal( A_eigen %*% eA$vectors[,1], eA$values[1] * eA$vectors[,1, drop = FALSE]))
[1] TRUE
If instead we start from Equation 4 and rearrange it to show the relationship between and
we get:
Let’s call this the “top down” explanation. We can verify this as well, making sure to convert eA$values to a diagonal matrix as the values are stored as a vector to save space.
isTRUE(all.equal(A_eigen %*% eA$vectors, eA$vectors %*% diag(eA$values)))
[1] TRUE
Notice that in Equation 6 is on the right of
, but in Equation 5 the corresponding value,
, is to the left of
. This is a bit confusing until one realizes that Equation 5 could have been written
since is a scalar. It’s too bad that the usual, bottom up, presentation seems to conflict with the top down approach. Perhaps the choice in Equation 5 is a historical artifact.
Is the Matrix Normal?
A normal matrix is one where . As far as I know, there is no function in
R to check this condition, but we’ll write our own in a moment. One reason being “normal” is interesting is if is a normal matrix, then the results of the eigendecomposition change slightly:
where is an orthogonal matrix, which we’ll talk about next.
Is the Matrix Orthogonal?
An orthogonal matrix takes the definition of a normal matrix one step further: . If a matrix is orthogonal, then its transpose is equal to its inverse:
, which of course makes any special computation of the inverse unnecessary. This is a significant advantage in computations.
To aid our learning, let’s write a simple function that will report if a matrix is normal, orthogonal, or neither.8
normal_or_orthogonal <- function(M) {
if (!inherits(M, "matrix")) stop("M must be a matrix")
norm <- orthog <- FALSE
tst1 <- M %*% t(M)
tst2 <- t(M) %*% M
norm <- isTRUE(all.equal(tst1, tst2))
if (norm) orthog <- isTRUE(all.equal(tst1, diag(dim(M)[1])))
if (orthog) message("This matrix is orthogonal\n") else
if (norm) message("This matrix is normal\n") else
message("This matrix is neither orthogonal nor normal\n")
invisible(NULL)
}
And let’s run a couple of tests.
normal_or_orthogonal(A_singular)
This matrix is neither orthogonal nor normal
Norm <- matrix(c(1, 0, 1, 1, 1, 0, 0, 1, 1), nrow = 3) normal_or_orthogonal(Norm)
This matrix is normal
normal_or_orthogonal(diag(3)) # the identity matrix is orthogonal
This matrix is orthogonal
Orth <- matrix(c(0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0), nrow = 4) normal_or_orthogonal(Orth)
This matrix is orthogonal
The columns of an orthogonal matrix are orthogonal to each other. We can show this by taking the dot product between any pair of columns. Remember is the dot product is zero the vectors are orthogonal.
t(Orth[,1]) %*% Orth[,2] # col 1 dot col 2
[,1] [1,] 0
t(Orth[,1]) %*% Orth[,3] # col 1 dot col 3
[,1] [1,] 0
Finally, not only are the columns orthogonal, but each column vector has length one, making them orthonormal.
sqrt(sum(Orth[,1]^2))
[1] 1
Appreciating the Queries
Taking these queries together, we see that symmetric and diagonal matrices are necessarily invertible, diagonalizable and normal. They are not however orthogonal. Identity matrices however, have all these properties. Let’s double-check these statements.
A_sym <- matrix( c(1, 5, 4, 5, 2, 9, 4, 9, 3), ncol = 3) # symmetric matrix, not diagonal A_sym
[,1] [,2] [,3] [1,] 1 5 4 [2,] 5 2 9 [3,] 4 9 3
normal_or_orthogonal(A_sym)
This matrix is normal
normal_or_orthogonal(diag(1:3)) # diagonal matrix, symmetric, but not the identity matrix
This matrix is normal
normal_or_orthogonal(diag(3)) # identity matrix (also symmetric, diagonal)
This matrix is orthogonal
So what’s the value of these queries? As mentioned, they help us understand the relationships between different types of matrices, so they help us learn more deeply. On a practical computational level they may not have much value, especially when dealing with real-world data sets. However, there are some other interesting aspects of these queries that deal with decompositions and eigenvalues. We might cover these in the future.
An Emerging Theme?
A more personal thought: In the course of writing these posts, and learning more linear algebra, it increasingly seems to me that a lot of the “effort” that goes into linear algebra is about making tedious operations simpler. Anytime one can have more zeros in a matrix, or have orthogonal vectors, or break a matrix into parts, the simpler things become. However, I haven’t really seen this point driven home in texts or tutorials. I think linear algebra learners would do well to keep this in mind.
Annotated Bibliography
These are the main sources I relied on for this post.
- The No Bullshit Guide to Linear Algebra by Ivan Savov.
- Section 6.2 Special types of matrices
- Section 6.6 Eigendecomposition
- Linear Algebra: step by step by Kuldeep Singh, Oxford Univerity Press, 2014.
- Section 4.4 Orthogonal Matrices
- Section 7.3.2 Diagonalization
- Section 7.4 Diagonalization of Symmetric Matrices
- Wikipedia articles on the types of matrices.
Footnotes
I’m only using a portion because the Hiranbe’s original contains a bit too much information for someone trying to get their footing in the field.↩︎
I’m using the term taxonomy a little loosely of course, you can call it whatever you want. The name is not so important really, what is important is the hierarchy of concepts.↩︎
As could complex numbers.↩︎
Usually in written text a row matrix, sometimes called a row vector, is written as
. In order to save space in documents, rather than writing
, a column matrix/vector can be kept to a single line by writing it as its transpose:
, but this requires a little mental gymnastics to visualize.↩︎
Upper and lower triangular matrices play a special role in linear algebra. Because of the presence of many zeros, multiplying them and inverting them is relatively easy, because the zeros cause terms to drop out.↩︎
This idea of the “most natural basis” is most easily visualized in two dimensions. If you have some data plotted on
and
axes, determining the line of best fit is one way of finding the most natural basis for describing the data. However, more generally and in more dimensions, principal component analysis (PCA) is the most rigorous way of finding this natural basis, and PCA can be calculated with the
eigen()function. Lots more information here.↩︎The
dropargument to subsetting/extracting defaults toTRUEwhich means that if subsetting reduces the necessary number of dimensions, the unneeded dimension attributes are dropped. Under the default, selecting a single column of a matrix leads to a vector, not a one column vector. In thisall.equal()expression we need both sides to evaluate to a matrix.↩︎One might ask why
Rdoes not provide a user-facing version of such a function. I think a good argument can be made that the authors ofRpassed down a robust and lean set of linear algebra functions, geared toward getting work done, and throwing errors as necessary.↩︎
Reuse
Citation
@online{hanson2022,
author = {Bryan Hanson},
editor = {},
title = {Notes on {Linear} {Algebra} {Part} 4},
date = {2022-09-26},
url = {http://chemospec.org/Linear-Alg-Notes-Pt4.html},
langid = {en}
}
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.