
The Bold & Beautiful Character Similarities using Word Embeddings
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
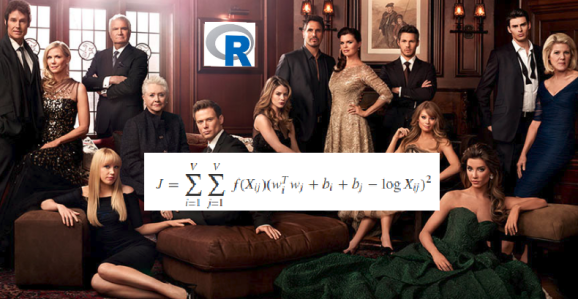
Introduction
I often see advertisement for The Bold and The Beautiful, I have never watched a single episode of the series. Still, even as a data scientist you might be wondering how these beautiful ladies and gentlemen from the show are related to each other. I do not have the time to watch all these episodes to find out, so I am going to use word embeddings on recaps instead…
Calculating word embeddings
First, we need some data, from the first few google hits I got to the site soap central. Recaps can be found from the show that date back to 1997. Then, I used a little bit of rvest code to scrape the daily recaps into an R data set.
Word embedding is a technique to transform a word onto a vector of numbers, there are several approaches to do this. I have used the so-called Global Vector word embedding. See here for details, it makes use of word co-occurrences that are determined from a (large) collection of documents and there is fast implementation in the R text2vec package.
Once words are transformed to vectors, you can calculate distances (similarities) between the words, for a specific word you can calculate the top 10 closest words for example. More over linguistic regularities can be determined, for example:
amsterdam - netherlands + germany
would result in a vector that would be close to the vector for berlin.
Results for The B&B recaps
It takes about an hour on my laptop to determine the word vectors (length 250) from 3645 B&B recaps (15 seasons). After removing some common stop words, I have 10.293 unique words, text2vec puts the embeddings in a matrix (10.293 by 250).
Lets take the lovely steffy,

the ten closest words are:
from to value
<chr> <chr> <dbl>
1 steffy steffy 1.0000000
2 steffy liam 0.8236346
3 steffy hope 0.7904697
4 steffy said 0.7846245
5 steffy wyatt 0.7665321
6 steffy bill 0.6978901
7 steffy asked 0.6879022
8 steffy quinn 0.6781523
9 steffy agreed 0.6563833
10 steffy rick 0.6506576
Lets take take the vector steffy – liam, the closest words we get are
death furious lastly excused frustration onset 0.2237339 0.2006695 0.1963466 0.1958089 0.1950601 0.1937230
and for bill – anger we get
liam katie wyatt steffy quinn said 0.5550065 0.4845969 0.4829327 0.4645065 0.4491479 0.4201712
The following figure shows some other B&B characters and their closest matches.

If you want to see the top n characters for other B&B characters use my little shiny app. The R code for scraping B&B recaps, calculating glove word-embeddings and a small shiny app can be found on my Git Hub.
Conclusion
This is a Mickey Mouse use case, but it might be handy if you are in the train and hear people next to you talking about the B&B, you can join their conversation. Especially if you have had a look at my B&B shiny app……
Cheers, Longhow

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.