
Modelling Dependence with Copulas in R
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
A copula is a function which couples a multivariate distribution function to its marginal distribution functions, generally called marginals or simply margins. Copulas are great tools for modelling and simulating correlated random variables.
The main appeal of copulas is that by using them you can model the correlation structure and the marginals (i.e. the distribution of each of your random variables) separately. This can be an advantage because for some combination of marginals there are no built-in functions to generate the desired multivariate distribution. For instance, in R it is easy to generate random samples from a multivariate normal distribution, however it is not so easy to do the same with say a distribution whose margins are Beta, Gamma and Student, respectively.
Furthermore, as you can probably see by googling copulas, there is a wide range of models providing a set of very different and customizable correlation structures that can be easily fitted to observed data and used for simulations. This variety of choice is one of the things I like the most about copulas.
In this post, we are going to show how to use a copula in R using the copula package and then we try to provide a simple example of application.
How copulas work (roughly)
But first, let’s try to get a grasp on how copulas actually work.
We generate n samples from a multivariate normal distribution of 3 random variables given the covariance matrix sigma using the MASS package.
library(MASS)
set.seed(100)
m <- 3
n <- 2000
sigma <- matrix(c(1, 0.4, 0.2,
0.4, 1, -0.8,
0.2, -0.8, 1),
nrow=3)
z <- mvrnorm(n,mu=rep(0, m),Sigma=sigma,empirical=T)
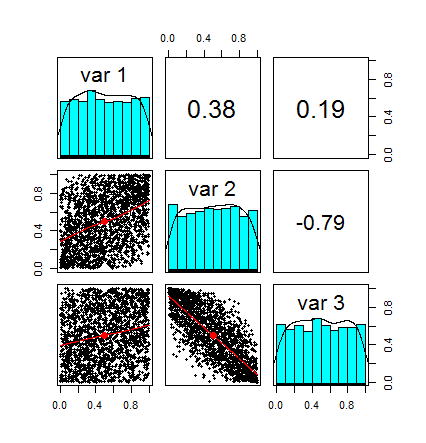
Now we check the samples correlation using cor() and a pairplot.
We are going to set method='spearman' in order to use Spearman’s Rho instead of the 'pearson' method in the cor() function (this is not strictly necessary in our example since we are going to use an elliptical copula, if you use non-elliptical copulas you may want to use either Spearman’s Rho or Kendall’s Tau).
library(psych)
cor(z,method='spearman')
pairs.panels(z)
[,1] [,2] [,3]
[1,] 1.0000000 0.3812244 0.1937548
[2,] 0.3812244 1.0000000 -0.7890814
[3,] 0.1937548 -0.7890814 1.0000000
The output and the pairplot show us that indeed our samples have exactly the expected correlation structure.

And now comes the magic trick: recall that if (X) is a random variable with distribution (F) then (F(X)) is uniformly distributed in the interval [0, 1]. In our toy example we already know the distribution (F) for each of the three random variables so this part is quick and straightforward.
u <- pnorm(z) pairs.panels(u)
Here is the pairplot of our new random variables contained in u. Note that each distribution is uniform in the [0,1] interval. Note also that the correlation the same, in fact, the transformation we applied did not change the correlation structure between the random variables. Basically we are left only with what is often referred as the dependence structure.
By using the rgl library we can plot a nice 3D representation of the vector u. This is very nice for presentation purposes, you can easily rotate around the graph in case you would like to check a different perspective: go nuts! Just click on the picture and drag the mouse around.
library(rgl) plot3d(u[,1],u[,2],u[,3],pch=20,col='navyblue')
Here is the plot:

Now, as a last step, we only need to select the marginals and apply them to u. I chose the marginals to be Gamma, Beta and Student distributed with the parameters specified below.
x1 <- qgamma(u[,1],shape=2,scale=1) x2 <- qbeta(u[,2],2,2) x3 <- qt(u[,3],df=5) plot3d(x1,x2,x3,pch=20,col='blue')
Below is the 3D plot of our simulated data. Spend a few seconds inspecting it. For sure this is a not so trivial dependence structure that has been generated in a very simple way and very few steps.

What is worth noticing is that by starting from a multivariate normal sample we have build a sample with the desired and fixed dependence structure and, basically, arbitrary marginals.
df <- cbind(x1,x2,x3)
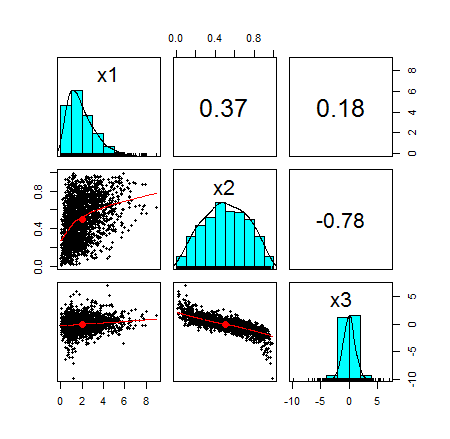
pairs.panels(df)
cor(df,meth='spearman')
x1 x2 x3
x1 1.0000000 0.3812244 0.1937548
x2 0.3812244 1.0000000 -0.7890814
x3 0.1937548 -0.7890814 1.0000000
Here is the pairplot of the random variables:

Again, I would like to emphasize that I chose totally arbitrary marginals. I could have chosen any marginal as long as it was a continuous function.
Using the copula package
The whole process performed above can be done more efficiently, concisely and with some additional care entirely by the copula package. Let’s replicate the process above using copulas.
library(copula)
set.seed(100)
myCop <- normalCopula(param=c(0.4,0.2,-0.8), dim = 3, dispstr = "un")
myMvd <- mvdc(copula=myCop, margins=c("gamma", "beta", "t"),
paramMargins=list(list(shape=2, scale=1),
list(shape1=2, shape2=2),
list(df=5)) )
Now that we have specified the dependence structure through the copula (a normal copula) and set the marginals, the mvdc() function generates the desired distribution. Then we can generate random samples using the rmvdc() function.
Z2 <- rmvdc(myMvd, 2000)
colnames(Z2) <- c("x1", "x2", "x3")
pairs.panels(Z2)
The simulated data is of course very close to the one simulated before and is displayed in the pairplot below:
A simple example of application
Now for the real world example. We are going to fit a copula to the returns of two stocks and try to simulate the returns using the copula. I already cleaned the data from two stocks and calculated the returns, you can download the data in .csv format (yahoo, cree). Note that the data may not be exactly the one you can find on Google finance because I made some data cleaning and removed some outliers without much thinking mainly because this is a another toy example of application.
Let’s load the returns in R
cree <- read.csv('cree_r.csv',header=F)$V2
yahoo <- read.csv('yahoo_r.csv',header=F)$V2
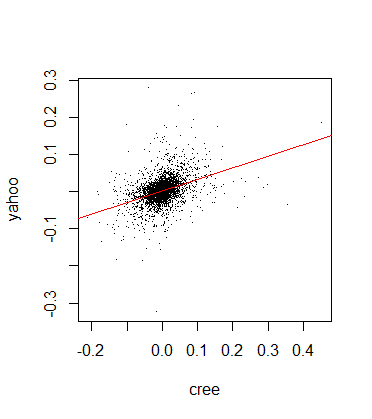
Before going straight to the copula fitting process, let’s check the correlation between the two stock returns and plot the regression line:
plot(cree,yahoo,pch='.') abline(lm(yahoo~cree),col='red',lwd=1) cor(cree,yahoo,method='spearman') [1] 0.4023584
We can see a very mild positive correlation, the returns look mainly like a random blob on the plot:
In the first example above I chose a normal copula model without much thinking, however, when applying these models to real data one should carefully think at what could suit the data better. For instance, many copulas are better suited for modelling asymetrical correlation other emphasize tail correlation a lot, and so on. My guess for stock returns is that a t-copula should be fine, however a guess is certainly not enough. Fortunately, the VineCopula package offers a great function which tells us what copula we should use. Essentially the VineCopula library allows us to perform copula selection using BIC and AIC through the function BiCopSelect()
library(VineCopula) u <- pobs(as.matrix(cbind(cree,yahoo)))[,1] v <- pobs(as.matrix(cbind(cree,yahoo)))[,2] selectedCopula <- BiCopSelect(u,v,familyset=NA) selectedCopula $family [1] 2 $par [1] 0.4356302 $par2 [1] 3.844534
Note that I fed into the selection algorithm the pseudo observations using the pobs() function. Pseudo observations are the observations in the [0,1] interval.
The fitting algorithm indeed selected a t-copula (encoded as 2 in the $family reference) and estimated the parameters for us. By typing ?BiCopSelect() you can actually see the encoding for each copula.
Let’s try to fit the suggested model using the copula package and double check the parameters fitting.
t.cop <- tCopula(dim=2) set.seed(500) m <- pobs(as.matrix(cbind(cree,yahoo))) fit <- fitCopula(t.cop,m,method='ml') coef(fit) rho.1 df 0.43563 3.84453
It is nice to see that the parameters of the fitted copula are the same as those suggested by the BiCopSelect() function. Let’s take a look at the density of the copula we have just estimated
rho <- coef(fit)[1] df <- coef(fit)[2] persp(tCopula(dim=2,rho,df=df),dCopula)

Now we only need to build the copula and sample from it 3965 random samples.
u <- rCopula(3965,tCopula(dim=2,rho,df=df))
plot(u[,1],u[,2],pch='.',col='blue')
cor(u,method='spearman')
[,1] [,2]
[1,] 1.0000000 0.3972454
[2,] 0.3972454 1.0000000
This is the plot of the samples contained in the vector u:
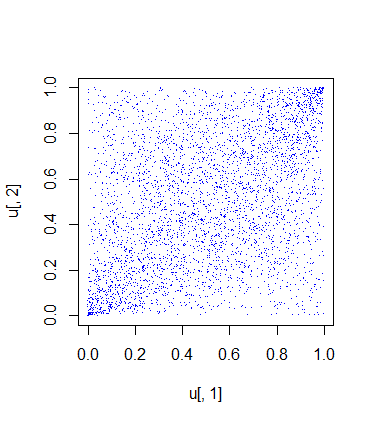
The random samples from the copula look a little bit close to the independence case, but that is fine since the correlation between the returns is low. Note that the generated samples have the same correlation as the data.
The t-copula emphasizes extreme results: it is usually good for modelling phenomena where there is high correlation in the extreme values (the tails of the distribution).
Note also that it is symmetrical, this might be an issue for our application, however we are going to neglect this.
Now we are facing the hard bit: modelling the marginals. We are going to assume normally distributed returns for simplicity even though it is well known to be a far from sound assumption. We therefore estimate the parameters of the marginals
cree_mu <- mean(cree) cree_sd <- sd(cree) yahoo_mu <- mean(yahoo) yahoo_sd <- sd(yahoo)
Let’s plot the fittings against the histogram in order to gather a visual take on what we are doing:
hist(cree,breaks=80,main='Cree returns',freq=F,density=30,col='cyan',ylim=c(0,20),xlim=c(-0.2,0.3))
lines(seq(-0.5,0.5,0.01),dnorm(seq(-0.5,0.5,0.01),cree_mu,cree_sd),col='red',lwd=2)
legend('topright',c('Fitted normal'),col=c('red'),lwd=2)
hist(yahoo,breaks=80,main='Yahoo returns',density=30,col='cyan',freq=F,ylim=c(0,20),xlim=c(-0.2,0.2))
lines(seq(-0.5,0.5,0.01),dnorm(seq(-0.5,0.5,0.01),yahoo_mu,yahoo_sd),col='red',lwd=2)
legend('topright',c('Fitted normal'),col=c('red'),lwd=2)
The two histograms are displayed below


Do not let the nice graphs fool you, under the assumptions for the distributions of the returns we are neglecting some extreme returns located in the tails of the distribution, but in this example we are interested in the joint behaviour, so that is what we are going to analyse soon.
Now we apply the copula in the mvdc() function and then use rmvdc() to get our simulated observations from the generated multivariate distribution. Finally, we compare the simulated results with the original data.
copula_dist <- mvdc(copula=tCopula(rho,dim=2,df=df), margins=c("norm","norm"),
paramMargins=list(list(mean=cree_mu, sd=cree_sd),
list(mean=yahoo_mu, sd=yahoo_sd)))
sim <- rmvdc(copula_dist, 3965)
Good, now we have simulated data, let’s make a visual comparison
plot(cree,yahoo,main='Returns')
points(sim[,1],sim[,2],col='red')
legend('bottomright',c('Observed','Simulated'),col=c('black','red'),pch=21)
This is the final scatterplot of the data under the assumption of normal marginals and t-copula for the dependence structure:

As you can see, the t-copula leads to results close to the real observations, although there are fewer extreme returns than in the real data and we missed some of the most extreme result. If we were interested in modelling the risk associated with these stocks then this would be a major red flag to be addressed with further model calibration.
Since the purpose of this example is simply to show how to fit a copula and generate random observations using real data, we are going to stop here.
Just as a curiosity let me show you how the simulated values from the copula would have changed by tweaking the df parameter in the t-copula.
Let’s try df=1 and df=8
set.seed(4258)
copula_dist <- mvdc(copula=tCopula(rho,dim=2,df=1), margins=c("norm","norm"),
paramMargins=list(list(mean=cree_mu, sd=cree_sd),
list(mean=yahoo_mu, sd=yahoo_sd)))
sim <- rmvdc(copula_dist, 3965)
plot(cree,yahoo,main='Returns')
points(sim[,1],sim[,2],col='red')
legend('bottomright',c('Observed','Simulated df=1'),col=c('black','red'),pch=21)
cor(sim[,1],sim[,2],method='spearman')
copula_dist <- mvdc(copula=tCopula(rho,dim=2,df=8), margins=c("norm","norm"),
paramMargins=list(list(mean=cree_mu, sd=cree_sd),
list(mean=yahoo_mu, sd=yahoo_sd)))
sim <- rmvdc(copula_dist, 3965)
plot(cree,yahoo,main='Returns')
points(sim[,1],sim[,2],col='red')
legend('bottomright',c('Observed','Simulated df=8'),col=c('black','red'),pch=21)
cor(sim[,1],sim[,2],method='spearman')
[1] 0.3929509
[1] 0.3911127
Note how different are the dependence structures that we have obtained although Spearman’s Rho is similar.
Clearly the parameter df is very important in determining the shape of the distribution. As df increases, the t-copula tends to a gaussian copula.


A final word of caution
As you might have guess at this point, copulas are extremely useful tools when it comes to model the joint behaviour of random variables, however it is also extremely easy to mess with them and neglect important aspects of the phenomenon you are trying to model. In this example we are using just two random variables and some lack of fit is noticeable when plotting simulated data against the real one, but as you add some more variables the results are no longer available to be plotted and you are left with correlation coefficients and pairplots that may lead you to think that the simulated values are very close to the real one when in fact you may be missing out a lot of action. Yet the true power of copulas is to generalize joint behaviour modelling with many random variables in an easy way with the divide et impera approach for the marginals and the dependence structure.
Another factor that is often neglected is that the dependence structure may not be fixed, but rather vary with time. This issue, of course, is not included the copula and should be taken into account when running simulations.
A gist with the full code for this post can be found here.
Thank you for reading this post, leave a comment below if you have any question.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.