
Announcing pqR: A faster version of R
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
pqR — a “pretty quick” version of R — is now available to be downloaded, built, and installed on Linux/Unix systems. This version of R is based on R-2.15.0, but with many performance improvements, as well as some bug fixes and new features. Notable improvements in pqR include:
- Multiple processor cores can automatically be used to perform some numerical computations in parallel with other numerical computations, and with the thread performing interpretive operations. No changes to R code are required to take advantage of such computation in “helper threads”.
- pqR makes a better attempt at avoiding unnecessary copying of objects, by maintaining a real count of “name” references, that can decrease when the object bound to a name changes. Further improvements in this scheme are expected in future versions of pqR.
- Some operations are avoided completely in pqR — for example, in pqR, the statement
for (i in 1:10000000) ...does not actually create a vector of 10000000 integers, but simply setsito each of these integers in turn.
There are also many detailed improvements in pqR that decrease general interpretive overhead or speed up particular operations.
I will be posting more soon about many of these improvements, and about the gain in performance obtained using pqR. For the moment, a quick idea of how much improvement pqR gives on simple operations can be obtained from the graph below (click to enlarge):
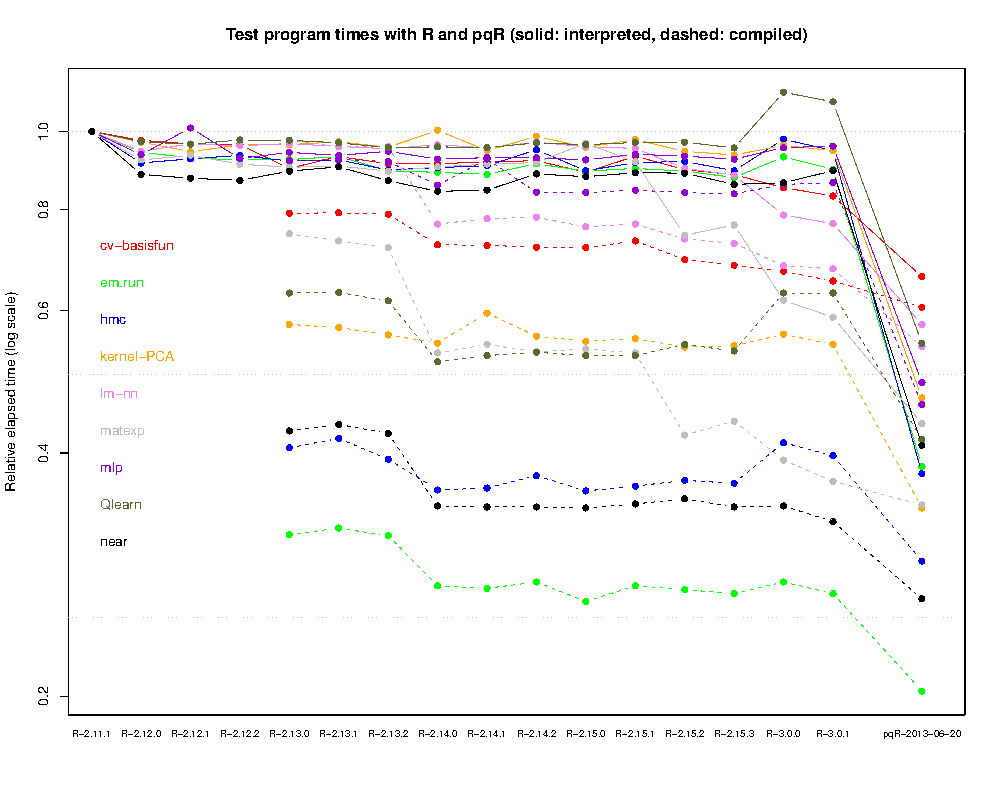
This shows the relative run times (on an Intel X5680 processor) of nine simple test programs (from the 2013-06-18 version of my R speed tests), using pqR, and using all releases of R by the R Core Team from 2.11.1 to 3.0.1. These programs mostly operate on small objects, doing simple operations, so this is a test of general interpretive overhead. A single thread was used for pqR (there is not much scope in these programs for parallelizing numeric computations).
As one can see, there has been little change in speed of interpreted programs since R-2.12.0, when some modifications that I proposed were incorporated into the R Core versions (and the R Core Team declined to incorporate many other modifications I suggested), though the speed of compiled programs has improved a bit since the compiler was introduced in R-2.13.0. The gain for interpreted programs from using pqR is almost as large as the gain from compilation. pqR also improves the speed of compiled programs, though the gain is less than for interpreted programs, with the result that the advantage of compilation has decreased in pqR. As I’ll discuss in future posts, for some operations, pqR is substantially faster when the compiler is not used. In particular, parallel computation in helper threads does not occur for operations started from compiled R code.
For some operations, the speed-up from using pqR is much larger than seen in the graph above. For example, vector-matrix multiplies are over ten times faster in pqR than in R-2.15.0 or R-3.0.1 (see here for the main reason why, though pqR solves the problem differently than suggested there).
The speed improvement from using pqR will therefore vary considerably from one R program to another. I encourage readers who are comfortable installing R from source on a Unix/Linux system to try it out, and let me know what performance improvements (and of course bugs) you find for your programs. You can leave a comment on this post, or mail me at [email protected].
You can get pqR here, where you can also find links to the source repository, a place to report bugs and other issues, and a wiki that lists systems where pqR has been tested, plus a few packages known to have problems with pqR. As of now, pqR has not been tested on Windows and Mac systems, and compiled versions for those systems are not available, but I hope they will be fairly soon.
UPDATE: You can read more about pqR in my post on Parallel computation with helper threads in pqR.

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.