
A new Sudoku Solver in R. Part 1
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Of course, I am not the first one who treated this issue. In the Internet, there is a huge variety of solutions with multiple languages. In R, there is even a package, dedicated exclusively to Sudokus.
In this first part, the solution presented just solves the puzzles that have always at least one empty cell with just one possible value. However, there are some puzzles where this is not enough, i.e., there is a certain point where no empty cell has just one possible value, which redunds in the need of the implementation of other strategies (which will be treated in future posts).
This first part covers just the cases where there is at least one empty cell with a unique possible value that can be filled. In my case, I tried to do it as most “human-like” as possible. Consequently, the following approach has NO “brute force like” code.
Therefore, I evaluated the ways in which I solve the puzzles without a computer and came up to four different general ways of identifying “sure” values:
1) A cell has just one possible value

As you can see, the circled cell can only be a 2 as 4 and 7 are already in the same sector, 3 and 5 are present in the same row and 1,6,8 and 9 appear in the same column
2) A specific value is only valid in one cell of a certain row
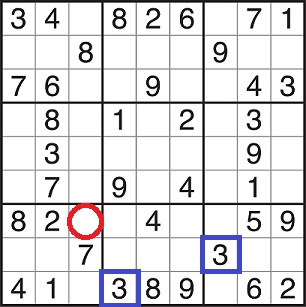
The red circled cell is the only one in its row that can be a 3, because the other three empty cells in the row belong to a sector where there is already a 3.
3) A specific value is only valid in one cell of a certain column

The red circled cell is the only one in its column that can be a 9, as, from the other three empty cells, the first one from above has a 9 in the same sector and the last two ones have a 9 in the same row.
4) A specific value is only valid in one cell of a certain sector
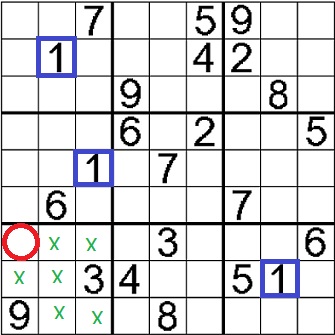
The red circled cell is the only one in that sector that can be a 1, as there are the blue squared ones above prevent all the empty cells from that column that also belong to the sector in question from being a 1. Additionally the other squared 1 in the bottom right sector, does not allow the left center empty cell of the bottom left sector to be a 1.
Below, you will find the code with its step by step explanation, which basically implements iteratively a series of functions that respond to the four above mentioned situations.
1) Matrix generation
|
#data entry option 1: Create a 9×9 matrix and enter numbers manually data <- matrix(nrow=9, ncol=9) data.entry (data) #data entry option 2: Fetch a Sudoku from sudoku.org.uk with the Sudoku package data <- fetchSudokuUK(date) #data entry option 3: Generate a Sudoku with the Sudoku package, where n is the amount of blank cells data <- generateSudoku(n) #matrix set-up datavalue <- array(dim=c(9,9,10)) data[data==0]<-NA datavalue [,,1] <- data datavalue [,,2:10] <- 1 |
As you can see, the puzzle (no matter how it was generated) is put into an array of 9x9x(9+1). As you can deduce from the code, the puzzle lays on the 1st z index and from 2 to 10, the number 1 is placed. The 2:10 z indexed slices will store the “status” of a specific number (z-1) in a specific cell, where 1 indicates that the cell can be z-1, 0 that it cannot and 2 that it is z-1.
For instance, if data[2,3,4] is 1, it means that the cell [2,3] in the puzzle can be a 3. If it is 2, it means that the cell [2,3] is definetly a 3.
The NA transformation is only necessary if your original input data (i.e., the puzzle) has any 0.
2) Update of the cube (z indexes 2 to 10)
|
#update cube updatearray <- function (x){ if (!is.na(x[i,j,1])){ } return (x) if (!is.na(x[i,j,1])){ } if (!is.na(x[i,j,1])){ |
These 3 functions update the underlying cube accodring to the values in the z=1 layer according to the aforementioned references (0 = [x,y,z] means that [x,y] is NOT z-1, 1= [x,y,z] can be z-1, 2=[x,y,z] IS z-1).
They are executed at the beginning with the initial puzzle configuration and re-executed whenever an update is done to the z=1 layer
3) Looking for the missing values
a) A cell has just one possible value
|
uniqueoption <- function (x){ if (is.na(x[i,j,1]) && sum(x[i,j,2:10]) == 1){ } return (x) |
b) A specific value is only valid in one cell of a certain row
|
uniqueinrow <- function (x){ |
c) A specific value is only valid in one cell of a certain column
|
uniqueincol <- function (x){ |
d) A specific value is only valid in one cell of a certain sector
|
getCoord <- function(x){ |
As you can see, the functions to deduce the missing numbers respond exactly to the four different “human-like” techniques explained before.
The first three are really easy to understand.
Regarding the fourth criterion, I must firstly say that the solution implemented is not as optimal as it could be. However, it is good enough to perform its purpose. I might improve it for Part 2.
It consists basically of 9 functions (one for each sector) that look for cells with just one possible value.
Additionally, there is an extra function (getCoord(x)), which transforms the grepping index into a primary coordinate reference, which is then converted in each sector function according its position.
4) Loop
|
#process datavalue <- updatearray(datavalue) while (flag == 1) flag <-0 datavalue <- uniqueoption(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinrow(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueincol(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinsector1(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinsector2(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinsector3(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinsector4(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinsector5(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinsector6(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinsector7(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinsector8(datavalue) datavalue <- updatearray(datavalue) datavalue <- uniqueinsector9(datavalue) datavalue <- updatearray(datavalue) } |
Once the functions are declared, it is only necessary to insert them in a loop; as you could see before, whenever a value is updated the flag is set to 1, enabling the program to loop once more if anything was modified and stopping if there have been no changes. Please note that the value of the flag is not assigned in an usual way (with “<-" or "=") but inside the assign() function, which is the way in which you can declare/modify a public variable in R.
As it was stated at the introduction of this post, this script does not solve any unique-solution puzzle. In the next post dedicated to Sudokus, new functions will be presented to cover the situations where this script is not enough, basically, when there is no cell with just one possible value
I hope you enjoyed this post. Any comments,critics,corrections are welcome!

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.