
Think academic journals look the same ? Well, some do…
[This article was first published on Freakonometrics - Tag - R-english, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
We have seen yesterday that finding an optimal strategy to publish is
not that simple. And actually, it can be even more difficult in the
case the journal rejects the paper (not because it is not correct, but
because “it
does not fit” with the standards, the quality of the journal, the
audience, the editor’s mood, or whatever). The author has basically two
choices,Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
- forget about the article and move to something else (e.g. start a blog where he/she will be the author and the editor)
- pretend that the article is worth publishing and then try to find another journal with similar interests

But this last choice is not that easy, since sometimes the author think that this journal was indeed the one that should publish it (e.g. all the articles on the subject have been published in that journal).
So I was wondering if there were clusters of journals, i.e. journals that publish almost the same kind of articles (so that next time one of my paper is rejected by the editor, I just go to for some journal in the same cluster).
So what I did is extremely simple: I looked at articles titles and looked for correlations between words frequency (I could have done that in key words, but I am not a big fan of those key words). I looked at 35 journals (that are somehow related to my areas of interest) and looked at titles of all articles published over the last 20 years. Then I kept the top 1000 of words, and I removed standard short words (“a“, “the“, “is“, etc). Actually, my top words looks like
"models" "model" "data" "estimation" "analysis" "time" "processes" "risk" "random" "stochastic" "regression" "market" "approach" "optimal" "based" "information" "evidence" "linear" "games" "bayesian" "theory" "effects" "distribution" "multivariate" "tests" "markets" "markov" "equilibrium" "dynamic" "process" "distributions" "application" "stock" "likelihood"
library("FactoMineR")
res.pca = PCA(MATRICE, scale.unit=TRUE, ncp=5,
graph=FALSE)
plot.PCA(res.pca, axes=c(1, 2), choix="ind")

Note that the projection is rather robust: if I consider my first 200 words, the graph is the same


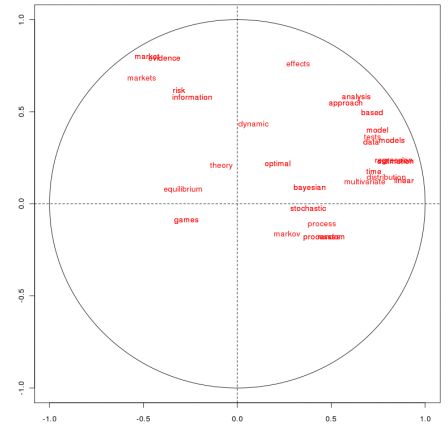
But the goal was to find cluster, i.e. classes of journals that publish papers with similar titles.
DISTANCE = dist(MATRICE) cah = hclust(DISTANCE) plot(cah)Here we have

Again, it might be possible to spend hours on the graphs, but if I want – someday – to submit something to one of those journals, I guess I have to stop here, and move to something else…
To leave a comment for the author, please follow the link and comment on their blog: Freakonometrics - Tag - R-english.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.