
Unit root versus breaking trend: Perron’s criticism
[This article was first published on We think therefore we R, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I came across an ingenious simulation by Perron during my Time-series lecture which I thought was worth sharing. The idea was to put your model to a further test of breaking trend before accepting the null of unit root. Let me try and illustrate this in simple language.
A non-stationary time series is one that has its mean changing with time. In other words, if you randomly choose a bunch of values from the series from the middle, you would end up with different values of mean for different bunches. In short there is a trend in the data which needs to be removed to make it stationary and proceed with our analysis (its far easier to work with stationary timeseries). In order to deal with non-stationary time-series one has to be careful about the kind of non-stationarity that is exhibited by the variable. Two corrections for non-stationarity include fitting
(1) Trend stationary (TS) models, which are suitable for models that have a deterministic trend and fluctuations about that deterministic trend. This can be fit by a simple zt = a + bt + et where et ~ ARMA(p,q)
(2) Difference stationary (DS) models, which are suitable for models having a stochastic trend. The DS models are appropriate for models that have a unit root in the AR polynomial. Unit root in the AR polynomial means that the trend part in the series cannot be represented by a simple linear trend with time (a + bt). And the correct representation is (1 – B)zt = a + et,where et is i.i.d.
The asymptotic properties of the estimates, forecasts and forecast errors vary substantially between the TS and DS models. (For the ones interested in the algebra behind this, lecture notes of Dr. Krishnan are here) Therefore it is important for us be sure that the model belongs to the appropriate class before we fit a TS or DS model. This is the reason why the clash between the two school of thoughts has bred enormous literature and discussions on the methodology to check for unit roots. One could try and endlessly argue about these discussions but I want to illustrate the genius of Perron who criticized the idea of fitting a DS model to series that could have a structural breaks. He said that you ought to take into account the structural break before you check for the unit roots, if you don’t do so, you might end up accepting the null of unit root, even when the true data generating process (DGP) is a trend stationary process. He illustrated this using a simple, but very elegant, simulation exercise. Madhavand I, along with fine-tuning on the codes provided by Utkarsh, replicated this exercise with R.
The steps involved are as follows:
(1) Simulate 1000 series with the DGP as:
zt = u1 + (u2 – u1)DUt + bt + et
where et are i.i.d innovations and t = 1,2,3,…100. For simplicity I have assumed b = 1 and u1 = 0.
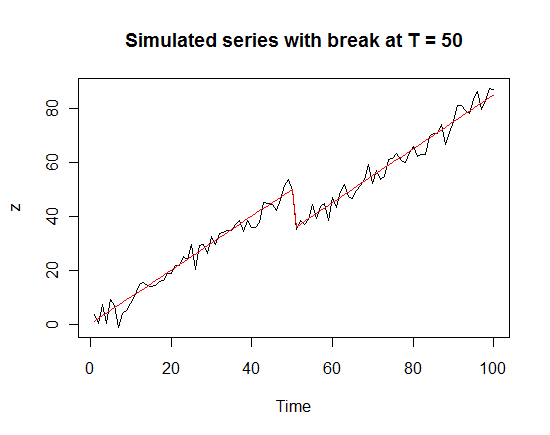
(2) Assume that there is a crash at time Tb= 50 and the entire series comes down by amount u2.
## Simulating a trend stationary model with a crash in the intercept ##
t <- c(1:100) # specifying the time
dummy <- as.numeric(ifelse(t <= 50, 0, 1)) # specifying the dummy for trend break at T = 50
z <- ts(t - 15*dummy + rnorm(100, mean = 0, sd = 3))# This is the trend stationary model with break in trend
x <- ts(t - 15*dummy) # This is just the trend line that we see in “red” in the plot below
plot(z, main = “Simulated series with break at T = 50”)
lines(x, col = “red”) ## Plotting a sample of the model that we have simulated
(3) For these simulations compute the autoregressive coefficient, “rho” in the regression:
zt = u + bt + ‘rho’zt-1 + et
(4) Plot the cumulative distribution function (c.d.f) of “rho” for different values of u2(crash).
## Now we will simulate the sample data above 1000 times and check for unit roots for each of these samples ##
# For simplicity we define a function to generate the “rho’s” for each of the simulated series
sim <- function(crash) ## Function name “sim”
{
d <- ts(t - crash*dummy + rnorm(100, mean = 0, sd = 3))
## saving the simulated series in “d”
trend <- lm(d ~ t) ## remove the trend from the
simulated series
# crash in the above function refers to the value of u2 in equation 1
res <- ar(ts(trend$residuals), order=1, aic= FALSE) ##
Fit an AR(1) model to the residue obtained after
detrending the series
if(length(res$ar) < 1) 0 else res$ar ## Return the ar
coefficient of the fitted AR(1) model above.
}
## Generate “rho’s” for different magnitude of crash by
simply using the sim() function defined above
temp1 <- replicate(n, sim(10))
temp2 <- replicate(n, sim(15))
temp3 <- replicate(n, sim(20))
temp4 <- replicate(n, sim(35))
## Sort the values of “rho”, we do this to plot the CDF
as we will see shortly
temp1.1 <- sort(temp1)
temp2.1 <- sort(temp2)
temp3.1 <- sort(temp3)
temp4.1 <- sort(temp4)
y <- seq(from=0, to=1, length.out=n)## This is how I
define the y-axis of my CDF which are basically the
probabilities.
## Plotting all the CDF of rho for different magnitude in one plot.
plot(c(min(temp1.1), max(temp4.1)), c(0, 1), type=’n’, xlab = “Rho”, ylab= “Probability”, main = “CDF of ‘Rho’ for differnt magniturde of crashes”)
lines(temp1.1, y, type = ‘l’, col = ‘red’)
lines(temp2.1, y, type = ‘l’, col = ‘green’)
lines(temp3.1, y, type = ‘l’, col = ‘blue’)
lines(temp4.1, y, type = ‘l’, col = ‘black’)
b <- c("10 unit crash", "15 unit crash", "20 unit crash", "35 unit crash")
legend(“topleft”, b , cex=0.5, col=c(“red”, “green”, “blue”, “black”), lwd=2, bty=”n”)
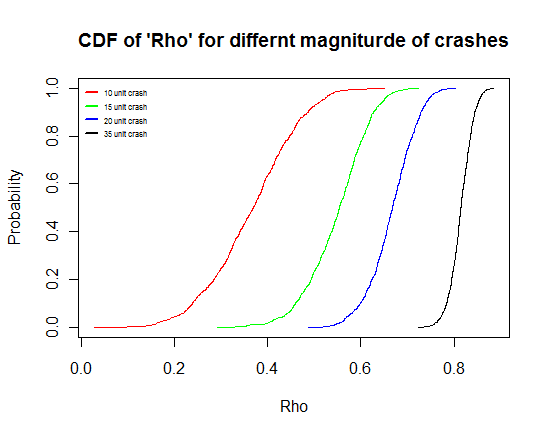
An interesting observation that we make (or rather Perron made) is that the c.d.f of our autoregressive coefficient “rho” tends more towards unity with increase in the magnitude in crash. What this means is that as the magnitude of crash increases the possibility of your accepting the (false) null of unit root increases. Why I say the false null is because I know the true DGP is a trend stationary one.
This idea of Perron was criticised on the ground that he was specifying the break point (Tb) exogenously, that is from outside the DGP. Frankly speaking I do not understand why was this taken as a criticism. I think fixing the break point exogenously was a good way of fixing it with an economic intuition and not making is a purely statistical exercise. Some researchers (I don’t understand why) termed this (simulation) illustration as a “data mining” exercise, and improved it by selecting the break point (Tb) endogenously (by Zivot and Andrews as mentioned in the lecture notes).
I would hate to impose my opinion here but I feel this was a very elegant and logical way of driving home the point that the null of unit root should be accepted for your sample if and only if your model stands the test of extreme rigour and not otherwise, and the rigour could be imposed exogenously with economic intuition too.
P.S. Perron did a similar simulation for breaking trend model, i.e where the slope of the model had a structural break. The codes would be quite similar to the ones given above, in fact it would be a good practice if you could do the similar simulation for a breaking trend. In case you do want to try but face any issues please feel free to post/email your queries.
Criticism and discussions welcome.
To leave a comment for the author, please follow the link and comment on their blog: We think therefore we R.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.