
The Relative Importance of Predictors – Let the Games Begin!
[This article was first published on Engaging Market Research, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
What’s the one thing we need to do?Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Marketing researchers are asked this question frequently whenever they analyze customer satisfaction data. A company wishing to increase sales or limit churn wants to focus only on the most important determinants of those outcomes. Given the limitations imposed by the available customer survey data, this strategic question is transformed quickly into a methodological one concerning how to assess the relative importance of predictors in a regression equation. The problem is that the predictors are all highly intercorrelated, making the “one thing” hard to identify. But search the net for “customer satisfaction multicollinearity,” and you will find a number of sites claiming to have found the solution. Let’s take a closer look.
The Gold Standard = Rating-Based Conjoint Analysis
The concept of relative importance comes from experimental design where we are able to piece together components any way we want. Consider the typical product design study. Products are bundles of attributes, and attributes are collections of levels. For example, a credit card company may be thinking of how best to configure attributes like interest rate, grace period, fees, customer support, and reward programs. They might want to test several levels of interest rate, different time limits for the grace period, a bunch of different fees, and so on. By systematically varying these attribute levels according to an experimental design, they can generate descriptions of hypothetical products that are presented one at a time to respondents who provide ratings of their preferences for all the product configurations.
Each of these attributes is a building block, an independent component that can be manipulated in the design of a credit card, both in the study and in the marketplace. This is an essential point to understand when we look at multiple regression with observational data, where the variables are not independent and not directly manipulated.
In a conjoint study relative importance is defined as percentage contribution. Changing the interest rates will impact the preference rating, so will varying the grace period, the fee structure, customer-support options, and the reward program. We sum the effects of all the attributes to get total variation, and then we divide the effect of each attribute by the total variation to get percent contribution. The attribute with the largest percent contribution is where we have the most leverage.
If you are familiar with ANOVA, you will recognize the above as the partitioning of the total sum-of-squares into components associated with each factor and a residual within-group. Because the factors are independent, the partitioning is unique. If you are familiar with unbalanced designs where the factors are no longer orthogonal, you will know that there is no longer a unique partitioning of the total sum-of-squares. Percent contribution now depends on the order of entry, which makes interpretation much more difficult.
Warning #1: Percent contribution is dependent on the variation across the attribute levels. Thus, I can make any attribute more important by increasing the range (e.g., going from a 2% spread between the highest and lowest interest rates to a 5% spread will make interest rate appear more important). I need to be careful about generalizing from specific attribute levels to the attribute in general. That is, we like to make summary statements about the effect of variables in general when we are actually speaking only of the impact of specific values of the variable.
Warning #2: Relative contribution makes sense in a rating-based conjoint analysis where the effects are assumed to be linear or where the attribute levels can be transformed so that the effects are made linear. Choice-based conjoint is not linear, and thus relative contribution is not constant but varies with values of all the predictors.
Warning #3: Finally, we must remember that all our data come from an experimental survey. Behavioral intentions are not marketplace behaviors. Moreover, no matter how hard we try, we cannot mimic the purchase context exactly so that generalization from our survey to the real world might be limited. For example, repeated measures on the same respondent always cause us trouble. Daniel Kahneman warned about this in his Nobel Prize lecture (pp. 473-474). The danger is that we create the effects through obtrusive measurement procedures.
Still, after all those warnings, one can see the advantage of an experimental design that decomposes a product into its building blocks and assesses the impact of varying independently each attribute level. Unfortunately, this is not the case with observational studies, as we shall see next.
Relative Importance of Predictors from Observational Studies
R has a package for calculating relative importance. Ulrike Grömping, who maintains the CRAN Task View for Design of Experiments, has written an R package called relaimpo. More importantly, she has a website with references to everything you need to know about relative importance. Dr. Grömping clearly understands the limitations imposed when one uses observational data. She supplies the software along with all the necessary caveats. You should read her description of the package in the Journal of Statistical Software. But also take a look at her article and comment in The American Statistician. Finally, there is a reference for those of you interested in comparing how linear regression and random forest measure variable importance.
Although this package is full of features, the basics are very easy to run. Let’s use the data set from an earlier post called Network Visualization of Key Driver Analysis. I will not repeat the analysis from that previous post, but I do want to remind the reader than this was an airline satisfaction study. Respondents were asked to rate their satisfaction with 12 components of their last flight, including ticketing, the aircraft, and customer service. Respondents also indicated their overall satisfaction, their likelihood to recommend, and their willingness to fly again with the airline.
As one might expect, these ratings are highly correlated. We can see this clearly below in a correlation plot from the R package psych. The function is cor.plot(), and an example is given on page 15 of the previous link. There appears to be three factors (service, aircraft, and ticketing) as indicated by the by the 12×12 squares embedded in a 3×3 block pattern. The consistent shades of blue throughout the correlation plot suggests the presence of a strong first principal component, which in this data set accounts for almost 62% of total variation.
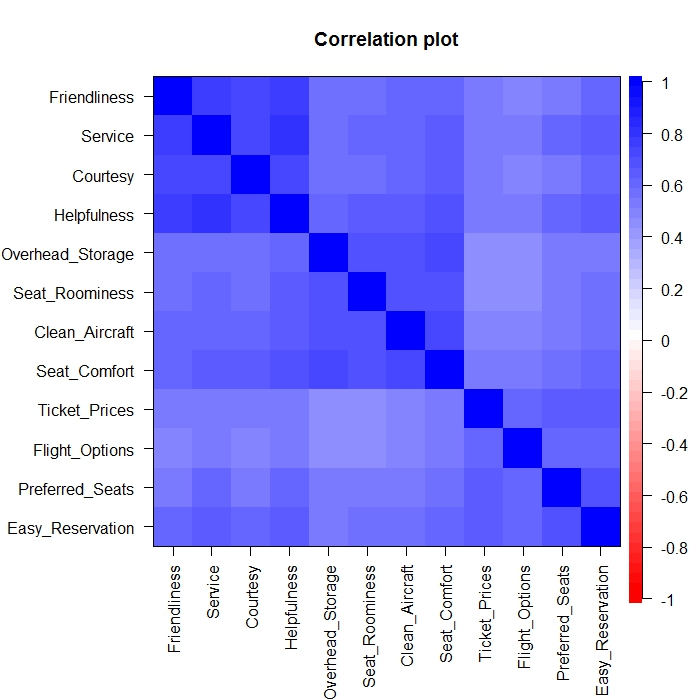
Most data analysts would assume that the last three ratings were outcomes that would serve as the dependent variables in regression analyses with the 12 more specific ratings as predictors. And this was the analysis that was previously run. Let’s review just one of these dependent variables, say overall satisfaction, in more detail.
The multiple regression is easy to run using the linear model function in R. First, we standardize the rating scores so that the regression coefficients will be standardized weights.
scaled_ratings<-data.frame(scale(ratings))
ols.sat<-lm(Satisfaction~
Easy_Reservation + Preferred_Seats + Flight_Options + Ticket_Prices +
Seat_Comfort + Seat_Roominess + Overhead_Storage + Clean_Aircraft +
Courtesy + Friendliness + Helpfulness + Service, data=scaled_ratings)
summary(ols.sat) What is the one thing that we ought to do? That is, what is the most important determinant of customer satisfaction? Here are the multiple regression coefficients. The multiple R-squared is 0.59.
Estimate | Std. Error | t value | Pr(>|t|) | ||
(Intercept) | 0.00 | 0.02 | 0.00 | 1.00 | |
Easy_Reservation | 0.05 | 0.03 | 1.61 | 0.11 | |
Preferred_Seats | 0.04 | 0.03 | 1.22 | 0.22 | |
Flight_Options | 0.05 | 0.03 | 1.98 | 0.05 | * |
Ticket_Prices | 0.04 | 0.03 | 1.47 | 0.14 | |
Seat_Comfort | 0.09 | 0.03 | 2.71 | 0.01 | ** |
Seat_Roominess | 0.07 | 0.03 | 2.22 | 0.03 | * |
Overhead_Storage | 0.02 | 0.03 | 0.77 | 0.44 | |
Clean_Aircraft | 0.10 | 0.03 | 2.97 | 0.00 | ** |
Courtesy | 0.06 | 0.03 | 1.91 | 0.06 | . |
Friendliness | 0.15 | 0.04 | 4.13 | 0.00 | *** |
Helpfulness | 0.13 | 0.04 | 3.46 | 0.00 | *** |
Service | 0.14 | 0.04 | 3.75 | 0.00 | *** |
Friendliness has the highest coefficient, but Service and Helpfulness have coefficients almost as high and clearly overlap given the sizes of the standard errors. This is actually a convenient result because it would be difficult for the airline to increase customer perceptions of Friendliness without appearing to be Helpful at the same time. Although tongue-in-cheek, this last comment points to the problem of using observational data to make policy recommendations. We cannot directly change customer perceptions of friendliness, and whatever we do to become more friendly will have effects on more than just friendliness. Friendliness is not an independent component that can manipulated like interest rates on a credit card.
It helps when interpreting regression coefficients to remember what effect is being measured. It is not the relationship between Friendliness and Satisfaction. That comes from a simple regression of Satisfaction on Friendliness. In this equation the regression coefficient indicates the effect of Friendliness controlling for the other predictors, as if Friendliness were entered last. What is the effect of Friendliness after controlling for Courtesy, Helpfulness, and Service? If all four ratings are reflective indicators of the same underlying latent variable, then we have a serious misspecification.
And what about relative importance? Can relative importance help us identify the one thing that we should do? We can calculate percent contribution when we have an experimental design with independent attributes. Can we calculate something similar when the data are observational and the predictors are correlated?
The R package, relaimpo, implements several reasonable procedures from the statistical literature to assign something that looks like a percent contribution to each correlated predictor. We will look at just one of these, an averaging of the sequential sum-of-squares obtained from all possible orderings of the predictors. Grömping calls this "lmg" after the authors Lindeman, Merenda, and Gold. Marketing researchers are more familiar with another version of this same metric called Shapley Value Regression.
Since we already have the output from our multiple regression above stored in ols.sat, we only need two lines of code.
library(relaimpo)
calc.relimp(ols.sat, type = c("lmg"), rela = TRUE) Here are our relative importance or contribution percentages from all possible orderings of the predictors.
Easy_Reservation | 7.3% |
Preferred_Seats | 5.9% |
Flight_Options | 5.1% |
Ticket_Prices | 5.3% |
Seat_Comfort | 9.2% |
Seat_Roominess | 7.5% |
Overhead_Storage | 6.3% |
Clean_Aircraft | 8.4% |
Courtesy | 9.2% |
Friendliness | 11.6% |
Helpfulness | 12.1% |
Service | 12.1% |
Do we now know what is the one thing we need to do? Fortunately, relaimpo automatically prints out some diagnostic information (shown below).
Average coefficients for different model sizes | ||||||||||||
1X | 2Xs | 3Xs | 4Xs | 5Xs | 6Xs | 7Xs | 8Xs | 9Xs | 10Xs | 11Xs | 12Xs | |
Easy_Reservation | 0.59 | 0.36 | 0.25 | 0.19 | 0.15 | 0.12 | 0.10 | 0.09 | 0.07 | 0.07 | 0.06 | 0.05 |
Preferred_Seats | 0.54 | 0.30 | 0.20 | 0.15 | 0.11 | 0.09 | 0.08 | 0.06 | 0.06 | 0.05 | 0.04 | 0.04 |
Flight_Options | 0.50 | 0.26 | 0.18 | 0.13 | 0.11 | 0.09 | 0.08 | 0.07 | 0.07 | 0.06 | 0.06 | 0.05 |
Ticket_Prices | 0.52 | 0.28 | 0.18 | 0.13 | 0.11 | 0.09 | 0.07 | 0.06 | 0.06 | 0.05 | 0.05 | 0.04 |
Seat_Comfort | 0.63 | 0.42 | 0.31 | 0.25 | 0.20 | 0.17 | 0.15 | 0.13 | 0.12 | 0.11 | 0.10 | 0.09 |
Seat_Roominess | 0.59 | 0.36 | 0.25 | 0.19 | 0.16 | 0.13 | 0.11 | 0.10 | 0.09 | 0.08 | 0.08 | 0.07 |
Overhead_Storage | 0.56 | 0.32 | 0.21 | 0.15 | 0.12 | 0.09 | 0.07 | 0.06 | 0.05 | 0.04 | 0.03 | 0.02 |
Clean_Aircraft | 0.60 | 0.38 | 0.28 | 0.22 | 0.18 | 0.16 | 0.14 | 0.13 | 0.12 | 0.11 | 0.10 | 0.10 |
Courtesy | 0.63 | 0.41 | 0.30 | 0.24 | 0.19 | 0.16 | 0.13 | 0.11 | 0.10 | 0.08 | 0.07 | 0.06 |
Friendliness | 0.66 | 0.46 | 0.36 | 0.30 | 0.26 | 0.23 | 0.21 | 0.19 | 0.18 | 0.17 | 0.16 | 0.15 |
Helpfulness | 0.68 | 0.50 | 0.40 | 0.33 | 0.28 | 0.25 | 0.22 | 0.19 | 0.17 | 0.16 | 0.14 | 0.13 |
Service | 0.68 | 0.49 | 0.39 | 0.33 | 0.28 | 0.25 | 0.22 | 0.20 | 0.18 | 0.17 | 0.15 | 0.14 |
We have already calculated the standardized regression coefficients when all 12 predictors are entered into the equation. These coefficients are the last column in the above table (12Xs). Had we entered only one variable at a time? That information is in the first column (1X). Since the standardized regression coefficient for a simple regression with only one predictor is the correlation coefficient, the first column gives us the correlations of each rating with Overall Satisfaction. Moreover, the table provides a complete history of what happens as we add more predictors to the regression equation.
What have we learned? Obviously, the coefficients vary as more predictors enter the equation, but the rankings stay relatively constant. All the ratings are correlated with satisfaction, but some more than others. The last three rows are always ranked as first, second, or third, although they trade positions as more variables are added to the equation. The first few rows with the ratings for ticketing are always toward the bottom of the rankings. We find sizable correlations with satisfaction across all the ratings. Some might call this a halo effect (measurement bias), and others would call it brand equity (positive/negative affect toward the airline). Regardless of what you call it, the ratings may be too intertwined to pick a single winner. Relative importance is no solution to multicollinearity.
This is what we learned from the previous post. The network visualization (reproduced below) uses a different metaphor, but reaches the similar conclusions.

This picture shows Satisfaction on the far left with edges to the ratings with the highest relative importance. The nodes do not represent separate components that can be manipulated independently. "Press" on Friendliness (implement service changes that increase customers perceptions of friendliness), and you will change the ratings of satisfaction and all the other ratings connected to Friendliness. This assumes, of course, that we have a causal relationship.
Ultimately, this last point is an issue that every driver analysis needs to address. Seeing is not doing, as Judea Pearl would remind us. Our data are observations, but our goal is intervention. Companies are looking for ways to improve those outcome measures. In fact, they are looking for the one thing that they need to do. Yet, we did not collect the relevant data. We could have asked about specific events under the control of the airlines that would have required respondents to recall what did and did not occur. Instead, we asked for broader summary judgments that can be made by accessing a generalized impression of the flight. No wonder we see such strong correlations among all the ratings and find it so difficult to separate the effects of our predictors.
To leave a comment for the author, please follow the link and comment on their blog: Engaging Market Research.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.