
The infamous apply function
[This article was first published on R for Public Health, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
For R beginners, the apply() function seems like a secret doorway into programming bliss. It seems so powerful, and yet, beyond reach. For those just starting out, examples of how to use apply() can really help with the intuition of how to harness its power. Here are some great ways to use apply() that can really help make R programming enjoyable and useful. Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
First, the general structure of apply() is like so:
apply(x, MARGIN, FUN)
- The first argument, “x”, is whatever dataset or columns of a dataset you want to do something to.
- The second argument, “MARGIN”, is how you want to apply function. The choices are either over the rows (MARGIN=1) or the columns (MARGIN=2).
- The third argument (FUN) is the function you apply.
So for an easy example, if you want to just sum the entries of all the columns in your dataset called “mydata”, you can do it this way:
apply(mydata, 2, sum)
But this is not always very useful. We have other columns in our datasets, and we probably don’t want to just sum all the time. What else can we do? Here are two nice ways to use apply():
1. Counting how many columns meet a certain condition
I have 13 child outcomes in a dataset named “births” and I want to count up how many live births there were. My “births” data looks like this:

How can I add up the live births, especially with those pesky NA’s in there? Here’s a one line way to do it:
births$childcount<-apply(births[,1:5], MARGIN=1, function(x) {sum(x=="live birth", na.rm=TRUE)})
This code is saying, for the first 5 columns of my dataset births, for each row (MARGIN=1), apply the following function. The function takes x as the input (x is just the births[,1:5] dataset), and sums up for each column of this dataset the number of times it sees “live birth”. The na.rm option removes any NA’s from consideration. If you had other conditions, you could say function(x) {sum(x>2010, na.rm=TRUE)}) for example, if you wanted to count up how many years were after 2010.
2. Changing coded missing values to NA for multiple columns at a time
Often datasets code their missing values as 99 or -99 instead of just leaving them blank. We might want to change these to actual missing so we can work with the data better. For one variable at at time, I can do it with with ifelse() statement:
originaldata$variable1<-ifelse(originaldata$variable1==99 | originaldata$variable1==-99, NA, originalvariable1)
This is equivalent to the cond() command in stata, where the first argument evaluates the condition, the second argument is what is done if the condition is true, and the third argument is what is done if the condition is false.
But what if I have 3 or 30 columns that I want to do this to? I don’t have to write ifelse() statements for them all individually. Instead, I use apply.
Here we have a dataset called “originaldata” and we have 4 variables that we want to change from the original missing values to NA values. These variables are in column numbers 2, 4, 5, and 6, as below:
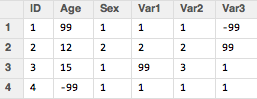
I take the columns of original dataset, and for each of those columns, I use an ifelse statement to check the value of the entry: if it’s 99 or -99 I change it to NA, and if it’s not then I leave it the way it is. This creates a new dataset called “new data” with just those columns that I choose.
newdata<-apply(originaldata[,c(2,4:6)], MARGIN=2, function(x) {ifelse(x==99 | x==-99, NA,x)})
We print out newdata:

Now if we want the original dataset together with the changed variables, we can just cbind (column bind) them together like so:
alldata<-cbind(originaldata[, c(-2,-4:-6)], newdata)

If you want to be extra fancy, you can just combine the cbind() statement with the apply() in one statement, like this:
newdata<-cbind(originaldata[,c(-2,-4,-6)], apply(originaldata[,c(2,4:6)], MARGIN=2, function(x) {ifelse(x==99 | x==-99, NA,x)}))
To leave a comment for the author, please follow the link and comment on their blog: R for Public Health.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.