
The Complexities of Customer Segmentation: Removing Response Intensity to Reveal Response Pattern
[This article was first published on Engaging Market Research, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
At the end of the last post, the reader was left assuming respondent homogeneity without any means for discovering if all of our customers adopted the same feature prioritization. To review, nine features were presented one at a time, and each time respondents reported the likely impact of adding the feature to the current product. Respondents indicated feature impact using a set of ordered behaviorally-anchored categories in order to ground the measurement in a realistic market context. This grounding is essential because feature preference is not retrieved from a table with thousands of decontextualized feature value entries stored in memory. Instead, feature preference is constructed as needed during the purchase process using whatever information is available and whatever memories come to mind at the time. Thus, we want to mimic that purchase process when a potential customer learns about a new feature for the first time. Of course, consumers will still respond if asked about features in the abstract without a purchase context. We are all capable of chitchat, the seemingly endless lists of likes and dislikes that are detached from the real world and intended more for socializing than accurate description.Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Moreover, the behaviorally-anchored categories insure both feature and respondent differentiation since a more extreme behavior can always be added if too many respondents select the highest category. That is, if a high proportion of the sample tell us that they would pay for all the features, we simply increase the severity of the highest category (e.g., would pay considerably more for) or we could add it as an additional category. One can think of this as a feature stress test. We keep increasing the stress until the feature fails to perform. In the end, we are able to achieve the desired differentiation among the features for only the very best performing features will make it into the highest category. At the same time we are enhancing our ability to differentiation among respondents because only those with the highest demand levels will be selecting the top-box categories.
Customers Wanting Different Features
Now, what if we have customer segments wanting different features? While we are not likely to see complete reversals of feature impact, we often find customers focusing on different features. As a result, many of the features will be rated similarly, but a few features that some customers report as having the greatest influence will be seen as having a lesser impact by others. For instance, some customers attend more to performance, while others customers place some value on performance but are even more responsive to discounts or rewards. However, everyone agrees that the little “extras” have limited worth.
Specifically, in the last post the nine features were arranged in ascending sets of three with difficulty values of {1.50, 1.25, 1.00}, {0.25, 0, -0.25} and {-1.00, -1.25, -1.50}. You might recall that difficulty refers to how hard it is for the feature to have an impact. Higher difficulty is associated with the feature failing the stress test. Therefore, the first feature with a difficulty of 1.50 finds it challenging to boost interest in the product. On the other hand, the difficulty scores for impactful features, such as the last feature, will be negative and large. One interprets the difficulty scale as if it were a z-score because respondents are located on the same scale and their distribution tends toward normal.
Measurement follows from a model of the underlying processes that generate the item responses, which is why it is call item response theory. Features possess “impactability” that is measured on a difficulty scale. Customers vary in “persuadability” that we measure on the same scale. When the average respondent (with latent trait theta = 0) confronts an average feature (with difficulty d=0), the result is an average observed score for that feature.
I do not know feature impact or customer interest before I collect the rating data. But afterwards, assuming that the features have the same difficulty for everyone, I can use the item scores aggregated across all the respondents to give me an estimate of each feature’s impact. Those features with the largest observed impact are the least difficult (large negative values), and those with little effect are the most difficult (large positive values). Then, I can use those difficulty estimates to determine where each respondent is located. Respondents who are impacted by only the most popular features have less interest than respondents responding to the least popular features. How do I know where you fall along the latent persuadability dimension? The features are ordered by their difficulty, as if they were mileposts along the same latent scale that differentiates among respondents. Therefore, your responses to the features tell me your location.
A Simulation to Make the Discussion Concrete
Estimation becomes more complicated when different subgroups want different features. In the item response theory literature, one refers to such an interaction as differential item functioning (DIF). We will avoid this terminology and concentrate on customer segmentation using feature impact as our basis. A simulation will clarify these points by making the discussion more concrete.
A simple example that combines the responses from two segments with the following feature impact weights will be sufficient for our purposes.
F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | |
Segment 1 | 1.50 | 1.25 | 1.00 | 0.25 | 0.00 | -0.25 | -1.00 | -1.25 | -1.50 |
Segment 2 | 1.50 | 1.25 | 1.00 | -1.50 | -1.25 | -1.00 | 0.25 | 0.00 | -0.25 |
Segment 1 shows the same pattern as in the last post with the features in ascending impact and gaps separating the nine into three sets of three features as described above. Segment 2 looks similar to Segment 1, except that the middle three features are the most impactful. This is a fairly common finding that low scoring features, such as Features 1 through 3, tend to lack impact or importance across the entire sample. On the other hand, when there are feature sets with substantial impact on some segment, those features tend to have some value to everyone. Thus, price is somewhat important to everyone, and really important to a specific segment (which we call the price sensitive). At least, this was my rationale for defining these two segments. Whether you accept my argument or not, I have formed two overlapping segment with some degree of similarity because they share the same weights for the first three features.
Cluster Analyses With and Without Response Intensity
As I show in the R code in the appendix, when you run k-means, you do not recover these two segments. Instead, as shown below with the average ratings across the nine features for each cluster profile, k-means separates the respondents into a “want it all” cluster with higher means across all the features and a “naysayer” cluster with lower means across all the features. What has happened?
Cluster means from a kmeans of the 200 respondents | ||||||||||
F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | N | |
Cluster 1 | 2.27 | 2.24 | 2.59 | 3.33 | 3.39 | 3.47 | 3.18 | 3.53 | 3.60 | 121 |
Cluster 2 | 1.16 | 1.41 | 1.29 | 2.01 | 1.94 | 1.86 | 1.96 | 2.03 | 2.05 | 79 |
We have failed to separate the response pattern from the response intensity. We have forgotten that our ratings are a combination of feature impact and respondent persuadability. The difficulties or feature impact scores specify only the response pattern. Although this is not a deterministic model, in general, we expect to see F1
A quick solution is to remove the intensity score, which is the latent variable theta. We can use the person mean score across all the features as an estimate of theta and cluster using deviation from the person mean. In the R code I have named this transformed data matrix “ipsative” in order to emphasize that the nine features scores have lost a degree of freedom in the calculation of the row mean and that we have added some negative correlation among the features because they now must sum to zero. This time, when we run the k-means on the row centered ratings data, we recover our segment response patterns with 84% of the respondents placed in the correct segment. Obviously, the numbering has been reversed so that Cluster #1 is Segment #2 and Cluster #2 is Segment #1.
Cluster means from a kmeans of the person-centered data matrix | ||||||||||
F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | N | |
Cluster 1 | -0.78 | -0.77 | -0.54 | 0.89 | 0.74 | 0.44 | -0.24 | 0.15 | 0.12 | 86 |
Cluster 2 | -0.65 | -0.53 | -0.42 | -0.21 | -0.08 | 0.18 | 0.45 | 0.58 | 0.68 | 114 |
Clustering using person-centered data may look similar to other methods that correct for halo effects. But that is not what we are doing here. We are not removing measurement bias or controlling for response styles. Although all ratings contain error, it is more likely that the consistent and substantial correlations observed among such ratings are the manifestation of an underlying trait. When the average ratings co-vary with other measures of product involvement, our conclusion is that we are tapping a latent trait that can be used for targeting and not a response style that needs to be controlled. It would be more accurate to say that we are trying to separate two sources of latent variation, the response pattern (a categorical latent variable) and response intensity (a continuous latent variable).
Why do I claim that response pattern is categorical and not continuous? Even with only a few features, there are many possible combinations and thus more than enough feature prioritization configurations to form a continuum. Yet, customers seem to narrow their selection down to only a few feature configurations that are marketed by providers and disseminated in the media. This is why response pattern can be treated as a categorical variable. The consumer adopts one of the feature prioritization patterns and commits to it with some level of intensity. Of course, they are free to construct their own personalized feature prioritization, but consumers tend not to do so. Given the commonalities in usage and situational constraints, along with limited variation in product offerings, consumers can simplify and restrict their feature prioritization to only a few possible configurations. In the above example, one selects an orientation, Features 4, 5 and 6 or Features 7, 8, and 9. How much one wants either set is a manner of degree.
Maps from Multiple Correspondence Analysis (MCA)
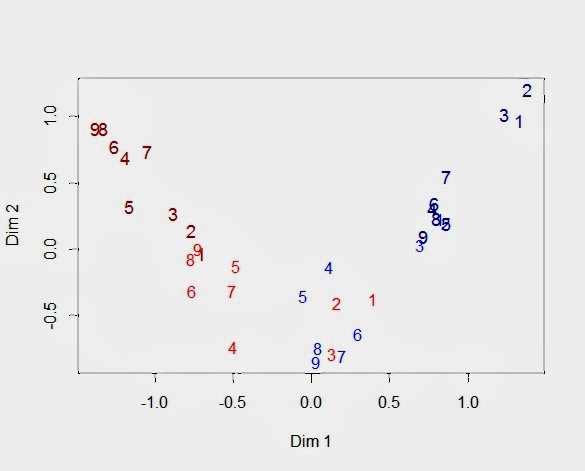
It is instructive to examine the multiple correspondence map that we would have produced had we not run the person-centered cluster analysis, that is, had we mistakenly treated the 200 respondents as belonging to the same population. In the MCA plot for the 36 feature categories displayed below, we continue to see separation between the categories so that every feature shows the same movement from left to right along the arc as one moves from the lowest dark red to the highest dark blue (i.e., from 1 to 4 on the 4-point ordinal scale). However, the features no longer are arrayed in order from Feature 9 through Feature 1, as one would expect given that only 100 of the 200 respondents preferred the features in the original rank ordering from 1 through 9. The first three features remain in order because there is agreement across the two segments, but there is greater overlap among the top six features than that which we observed in the prior post where everyone belong to Segment 1. Lastly, we see the arc from the previous post that begins in the upper left corner and extends with a bend in the middle until it reaches the upper right corner. We obtain a quadratic curve because the second dimension is a quadratic function of the first dimension.
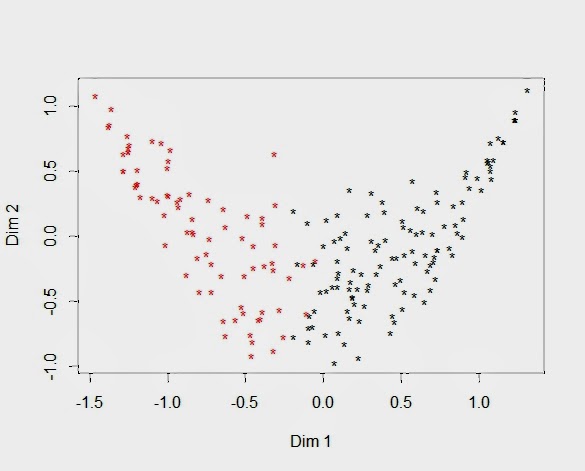
Finally, I wanted to use the MCA map to display the locations of the respondents and show the differences between the two cluster analyses with and without row centering. First, without row centering the two clusters are separated along the first dimension representing response intensity or the average rating across all nine features. Our first cluster analysis treated the original ratings as numeric and identified two groupings of respondents, the naysayer (red stars) and those wanting it all (black stars). This plot confirms that response intensity dominates when the ratings are not transformed.
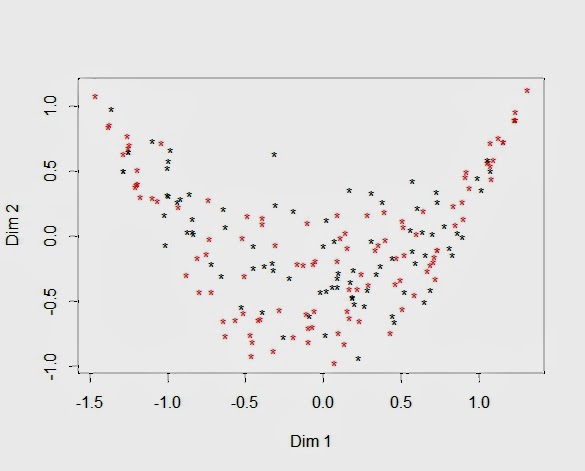
Next, we centered our rows by calculating each respondent’s deviation score about their mean rating and reran the cluster analysis with these transformed ratings. We were able to recover the two response generation processes that were used to simulate the data. However, we do not see those segments as clusters in the MCA map. In the map below, the red and black stars from the person-centered cluster analysis form overlapping arcs of respondents spread out along the first dimension. MCA does not remove intensity. In fact, response intensity is the latent trait responsible for the arc.
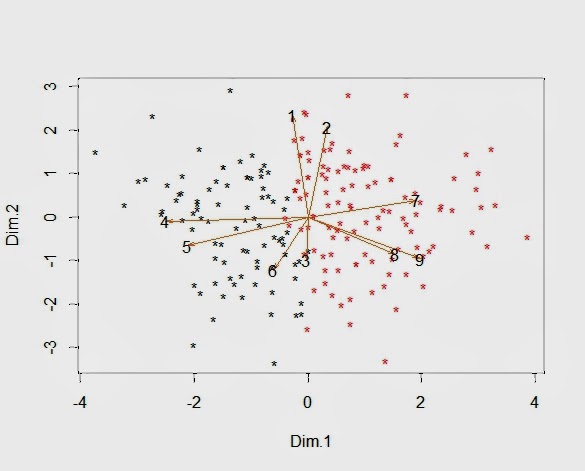
The final plot presents the results from the principal component analysis for the person-centered data. The dimensions are the first two principal components and the arrows represent the projections of the features onto the map. Respondents in the second cluster with higher scores on the last three features are shown in red, and the black stars indicate respondents from the first cluster with preferences for the middle three features. This plot from the principal component analysis on the person-centered ratings demonstrates how deviation scores remove intensity and reveal segment differences in response pattern.
Appendix with R code needed to run the above analyses.
For a description of the code, please see my previous post.
library(psych)
d1<-c(1.50,1.25,1.00,.25,0,-.25,
-1.00,-1.25,-1.50)
d2<-c(1.50,1.25,1.00,-1.50,-1.25,-1.00,
.25,0,-.25)
set.seed(12413)
bar1<-sim.poly.npl(nvar = 9, n = 100,
low=-1, high=1, a=NULL,
c=0, z=1, d=d1,
mu=0, sd=1.5, cat=4)
bar2<-sim.poly.npl(nvar = 9, n = 100,
low=-1, high=1, a=NULL,
c=0, z=1, d=d2,
mu=0, sd=1.5, cat=4)
rating1<-data.frame(bar1$items+1)
rating2<-data.frame(bar2$items+1)
apply(rating1,2,table)
apply(rating2,2,table)
ratings<-rbind(rating1,rating2)
kcl<-kmeans(ratings, 2, nstart=25)
kcl
rowmean<-apply(ratings, 1, mean)
ipsative<-sweep(ratings, 1, rowmean, "-")
round(apply(ipsative,1,sum),8)
kcl_rc<-kmeans(ipsative, 2, nstart=25)
kcl_rc
table(c(rep(1,100),rep(2,100)),
kcl_rc$cluster)
F.ratings<-data.frame(ratings)
F.ratings[]<-lapply(F.ratings, factor)
library(FactoMineR)
mca<-MCA(F.ratings)
categories<-mca$var$coord[,1:2]
categories[,1]<--categories[,1]
categories
feature_label<-c(rep(1,4),rep(2,4),rep(3,4),
rep(4,4),rep(5,4),rep(6,4),
rep(7,4),rep(8,4),rep(9,4))
category_color<-rep(c("darkred","red",
"blue","darkblue"),9)
category_size<-rep(c(1.1,1,1,1.1),9)
plot(categories, type="n")
text(categories, labels=feature_label,
col=category_color, cex=category_size)
mca2<-mca
mca2$var$coord[,1]<--mca$var$coord[,1]
mca2$ind$coord[,1]<--mca$ind$coord[,1]
plot(mca2$ind$coord[,1:2], col=kcl$cluster, pch="*")
plot(mca2$ind$coord[,1:2], col=kcl_rc$cluster, pch="*")
pca<-PCA(ipsative)
plot(pca$ind$coord[,1:2], col=kcl_rc$cluster, pch="*")
arrows(0, 0, 3.2*pca$var$coord[,1],
3.2*pca$var$coord[,2], col = "chocolate",
angle = 15, length = 0.1)
text(3.2*pca$var$coord[,1], 3.2*pca$var$coord[,2],
labels=1:9)
To leave a comment for the author, please follow the link and comment on their blog: Engaging Market Research.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.