
R: Explore ARIMA(2, 2, 2) subclass family on Shiny
[This article was first published on Analysis with Programming, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I’ve been thinking that it might be better to explore the Box-Jenkins ARIMA (Autoregressive Integrated Moving-Average) three-iterative modelling on Shiny. So here is what I got, this app is intended for ARIMA(2, 2, 2) subclass family only.

The app has six tabs, and these are:
 The next tab is Identification, this is the first stage of Box-Jenkins iterative modelling. Here, the model is identified using the correlograms, Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF).
The next tab is Identification, this is the first stage of Box-Jenkins iterative modelling. Here, the model is identified using the correlograms, Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF).

Inside this tab are three subtabs: ACF, PACF, and Differenced Series. The third subtab (Differenced Series) shows nothing unless you apply differencing (by checking Apply Differencing? check box). Now after identifying the model, we then proceed to the second stage of modelling which is the Estimation.

The side panel here is changed, the range for both Autoregressive and Moving-Average sliders is now from 0 to 5. I extend this, so that we can play with the different fitted values from different combinations of model’s orders. And of course, the order of differencing remains the same. If you prefer to include constant (intercept) in the model, you can check the box. Note that, the intercept is ignored if there is differencing in the model (from arima R Documentation).
After obtaining the estimates, let’s diagnose the model, by cheking for randomness of the residuals. So here is the main panel of Diagnostic tab,
 As you notice, I made a simple hypothesis testing which is dynamic. The values in COMPUTATION section updates automatically if we change the order of the identified model. The same case for the last two sections (DECISION and CONCLUSION). You will see how it works especially when we deviate the order of the model from the identified one, say if we simulate ARIMA(1, 1, 0), and we assign the identified order as ARIMA(0, 0, 1), then we will have something like this,
As you notice, I made a simple hypothesis testing which is dynamic. The values in COMPUTATION section updates automatically if we change the order of the identified model. The same case for the last two sections (DECISION and CONCLUSION). You will see how it works especially when we deviate the order of the model from the identified one, say if we simulate ARIMA(1, 1, 0), and we assign the identified order as ARIMA(0, 0, 1), then we will have something like this,

The p-value is less than 0.05, thus the decision is to reject the null hypothesis, which concludes that the residuals are not independently distributed. And if we look at the time plot of the residuals, we see a pattern on it which isn’t random, hence agrees with the conclusion. On this tab, you will find a new option for histogram, an idea from the basic Shiny’s example.

Finally, we compute the predicted values and plot this along with the original data.

And as mentioned, the sixth tab is the data.

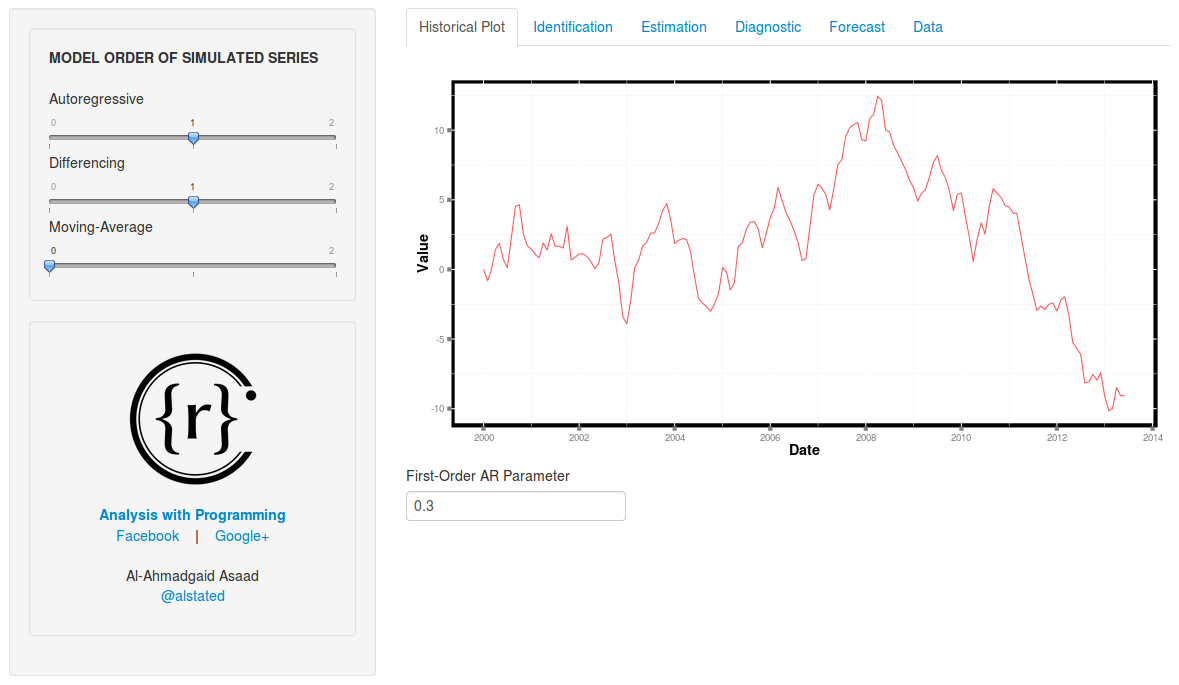
The app has six tabs, and these are:
- Historical Plot;
- Identification;
- Estimation;
- Diagnostic;
- Forecast; and
- Data

Inside this tab are three subtabs: ACF, PACF, and Differenced Series. The third subtab (Differenced Series) shows nothing unless you apply differencing (by checking Apply Differencing? check box). Now after identifying the model, we then proceed to the second stage of modelling which is the Estimation.

The side panel here is changed, the range for both Autoregressive and Moving-Average sliders is now from 0 to 5. I extend this, so that we can play with the different fitted values from different combinations of model’s orders. And of course, the order of differencing remains the same. If you prefer to include constant (intercept) in the model, you can check the box. Note that, the intercept is ignored if there is differencing in the model (from arima R Documentation).
After obtaining the estimates, let’s diagnose the model, by cheking for randomness of the residuals. So here is the main panel of Diagnostic tab,

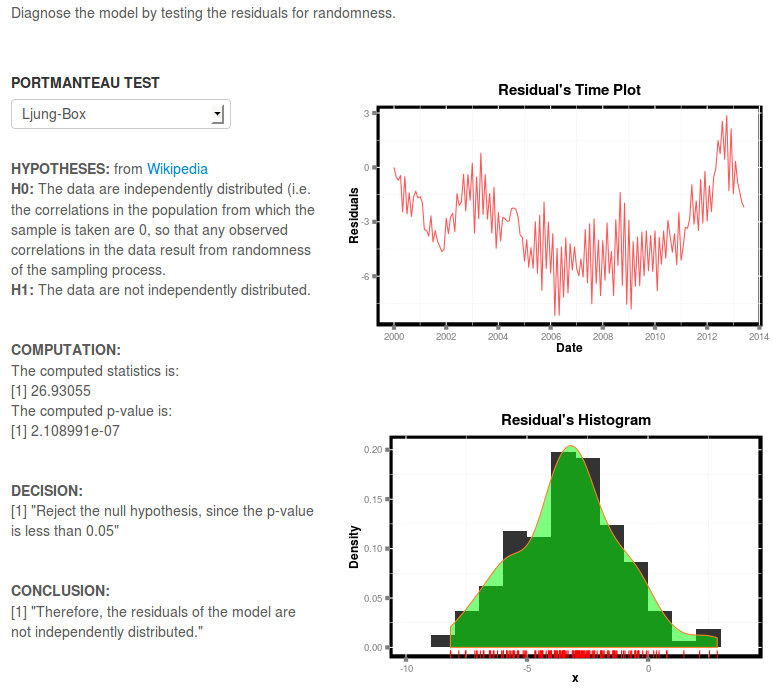
The p-value is less than 0.05, thus the decision is to reject the null hypothesis, which concludes that the residuals are not independently distributed. And if we look at the time plot of the residuals, we see a pattern on it which isn’t random, hence agrees with the conclusion. On this tab, you will find a new option for histogram, an idea from the basic Shiny’s example.
Finally, we compute the predicted values and plot this along with the original data.

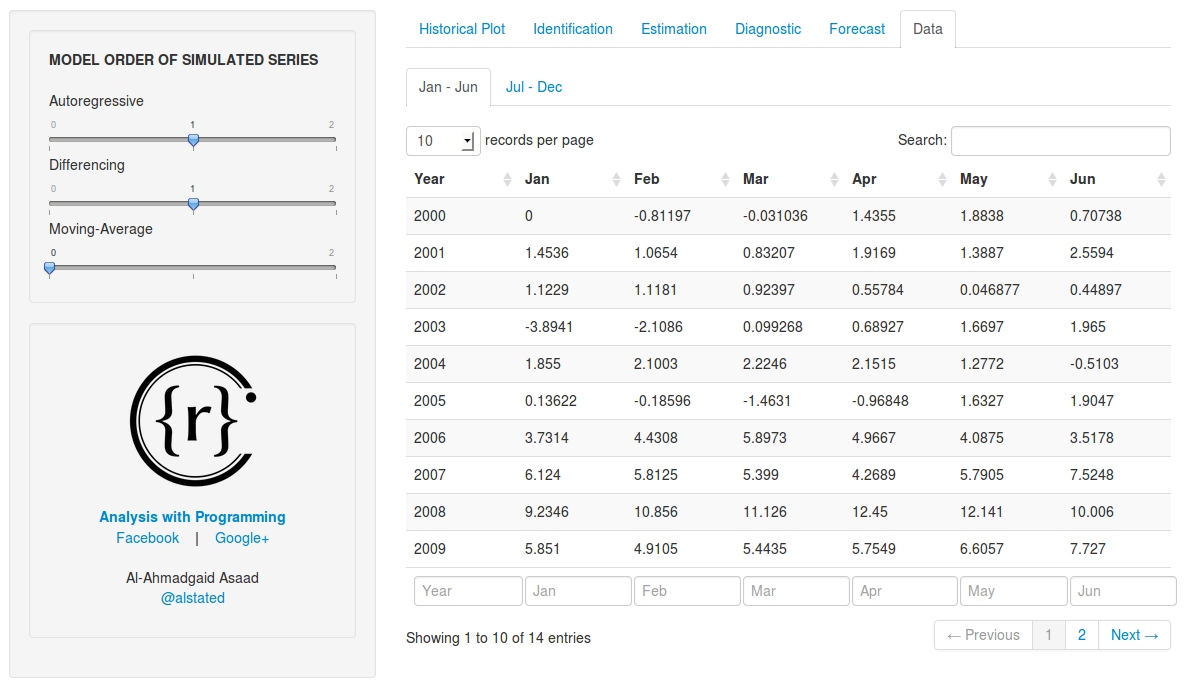
And as mentioned, the sixth tab is the data.
To leave a comment for the author, please follow the link and comment on their blog: Analysis with Programming.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.