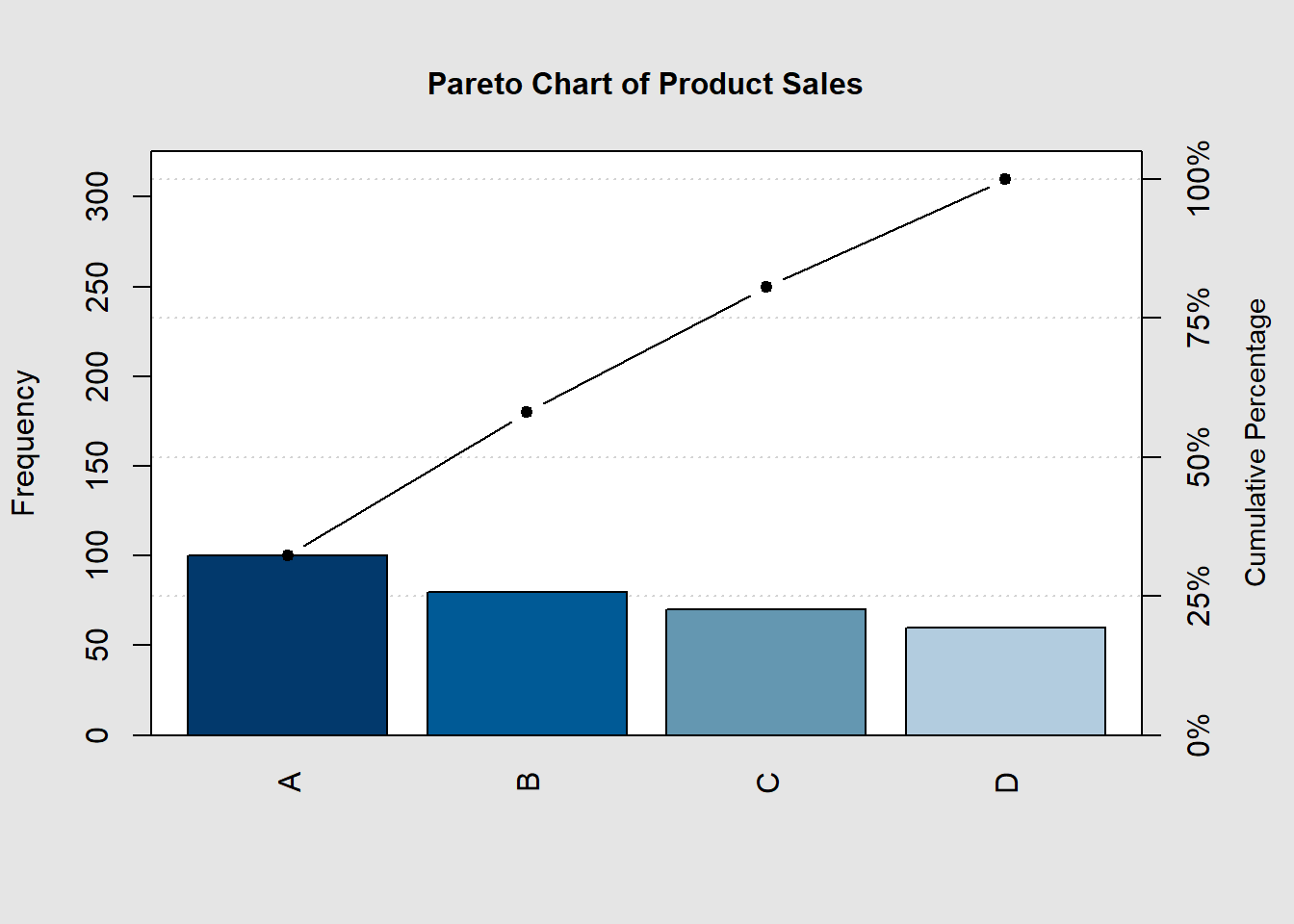
Creating a Scree Plot in Base R
Introduction
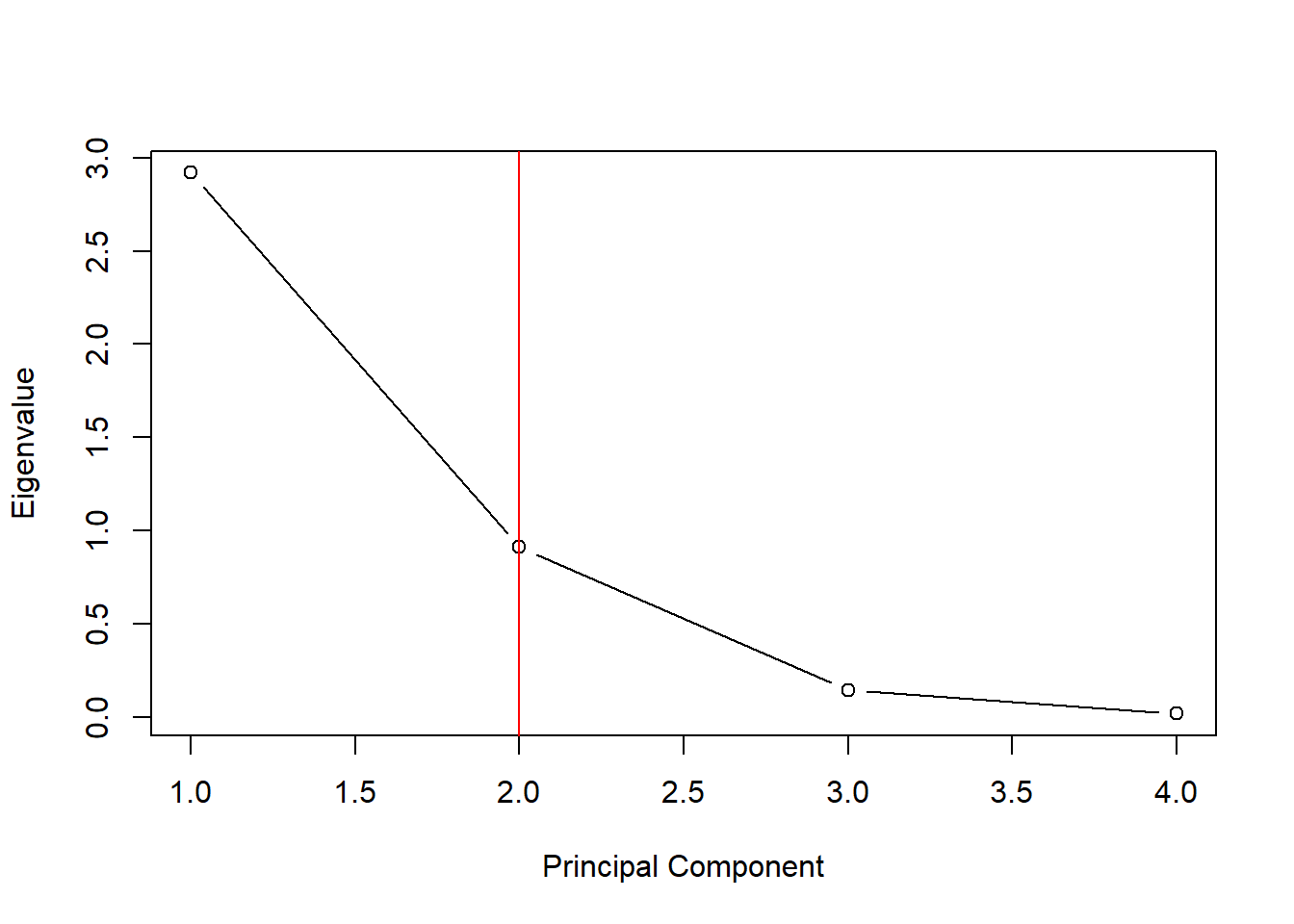
A scree plot is a line plot that shows the eigenvalues or variance explained by each principal component (PC) in a Principal Component Analysis (PCA). It is a useful tool for determining the number of PCs to retain in a PCA model.
I...