
How much can we learn from an empirical result? A Bayesian approach to power analysis and the implications for pre-registration.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Just like a lot of political science departments, here at Rice a group of faculty and students meet each week to discuss new research in political methodology. This week, we read a new symposium in Political Analysis about the pre-registration of studies in political science. To briefly summarize, several researchers argued that political scientists should be required, or at least encouraged, to publicly announce their data collection and analysis plans in advance. The idea is that allowing researchers to adjust their analysis plans after collecting the data allows for some degree of opportunism in the analysis, potentially allowing researchers to find statistically significant relationships even if none exist. As usual, we don’t have any original ideas in political science: this is something that medical researchers started doing after evidence suggested that false positives were rather common in the medical literature.
To me, the discussion of study registration raises a more fundamental question: what can we hope to learn from a single data analysis? It’s a question whose answer ultimately depends on even deeper epistemological questions about how we know things in science, and how new discoveries are made. And there’s no way I can answer such a question in a short blog post. Suffice it to say that I am skeptical that we can arrive at any conclusion on the basis of a single study, even if it is pre-registered and perfectly conducted.
But there is a closely related question that I think can be answered in a short blog post. Nathan Danneman and I have recently written a paper arguing that combining assessment of the substantive robustness of a result along with its statistical significance reduces the false positive rate. In short, we find that when a relationship doesn’t really exist, it’s quite unlikely that a sample data set will show results that are both substantively robust and statistically significant. (Substantive robustness is technically defined in our paper, but for the present it suffices to note that the substantive robustness of a result is related to its size and certainty.)
There is one thing that we don’t ask: how much can we learn from a statistically significant result, given its size and its statistical significance? I’ll consider the case of a basic linear regression, 

")
Now in some ways, this is an unsatisfying statement of the problem: the probability that any point estimate is true is 


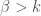
Bayes’ rule tells us that:
=")
\Pr\left(\beta=0\right)}{\Pr\left(\hat{\beta}\mbox{ is stat. sig.}|\beta=0\right)\Pr\left(\beta=0\right)+\Pr\left(\hat{\beta}\mbox{ is stat. sig.}|\beta\neq0\right)\left(1-\Pr\left(\beta=0\right)\right)}")
Here, ")
Suppose we have a data set with 100 observations, run an analysis, and get an estimate 
")
")



")
The results are depicted in the graph below.

Now, take a look at this. Our maximum likelihood, squared-error-minimizing guess about 
And that’s with a rather liberal prior! If, like most political scientists, you start out being much more skeptical—a 90% chance that the null is true—even finding a 
So, what can we conclude? First, a small magnitude but statistically significant result contains virtually no important information. I think lots of political scientists sort-of intuitively recognize this fact, but seeing it in black and white really underscores that these sorts of results aren’t (by themselves) all that scientifically meaningful. Second, even a large magnitude, statistically significant result is not especially convincing on its own. To be blunt, even though such a result moves our posterior probabilities a lot, if we’re starting from a basis of skepticism no single result is going to be adequate to convince us otherwise.
And this brings me back to my first point: study pre-registration. I hope that my little demonstration has helped to convince you that no single study can be much evidence of anything, even under comparatively ideal conditions. And so putting restrictions on the practice of science to guarantee the statistical purity of individual studies seems a little misguided to me, if those restrictions are likely to constrain scientists’ freedom to create and explore. Pre-registration by its very nature is going to incentivize people to create tests of existing theories and inhibit them from searching their data sets for new and interesting relationships. Perhaps we’d be more open to their doing that if we knew that the marginal contribution of any study to “conclusiveness” is very small, and so it’s more important to ensure that these studies are creative than to ensure that they are sound implementations of Popperian falsification. Bayesian learning about scientific conclusions is going to take place in a literature, not in a paper.

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.