
Expected Points by Position Rank in Fantasy Football
[This article was first published on Fantasy Football Analytics in R, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
In this post, I calculate the expected fantasy points scored by players based on their position and position rank. This post is modeled after a post by Chase Stuart (see here), where he calculated players’ expected fantasy points as a function of historical performance for each position and position rank. For my fantasy football auction draft optimizer tool in Shiny, see here.Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
How the Expected Points were Calculated
I downloaded historical projected position ranks and actual fantasy points scored from 1999 to 2012. The historical data for average draft position (used for projected position rank) came from myfantasyleague.com. The historical data for actual fantasy points came from Pro-Football-Reference and FantasyPlaymakers. I calculated fantasy points based on standard fantasy football scoring settings from FantasyPros. Then I computed robust averages of actual fantasy points for each position rank by averaging the actual fantasy points scored for each position rank across years using the Hodges-Lehmann estimator, which is the median of all pairwise means, and is robust to outliers.R Scripts
The R script for downloading the historical ADP data is located here (note that the data were first exported to .xml by going here):https://github.com/dadrivr/FantasyFootballAnalyticsR/blob/master/R%20Scripts/Historical%20ADP.R
The R script for downloading the historical fantasy points scored is located here:
https://github.com/dadrivr/FantasyFootballAnalyticsR/blob/master/R%20Scripts/Historical%20Actual.R
The R script for calculating the best fitting line for each position and creating the plots is located here:
https://github.com/dadrivr/FantasyFootballAnalyticsR/blob/master/R%20Scripts/eVORP.R
Plots
The plots below show the expected fantasy points for each position and position rank with the best-fitting line overlaid.

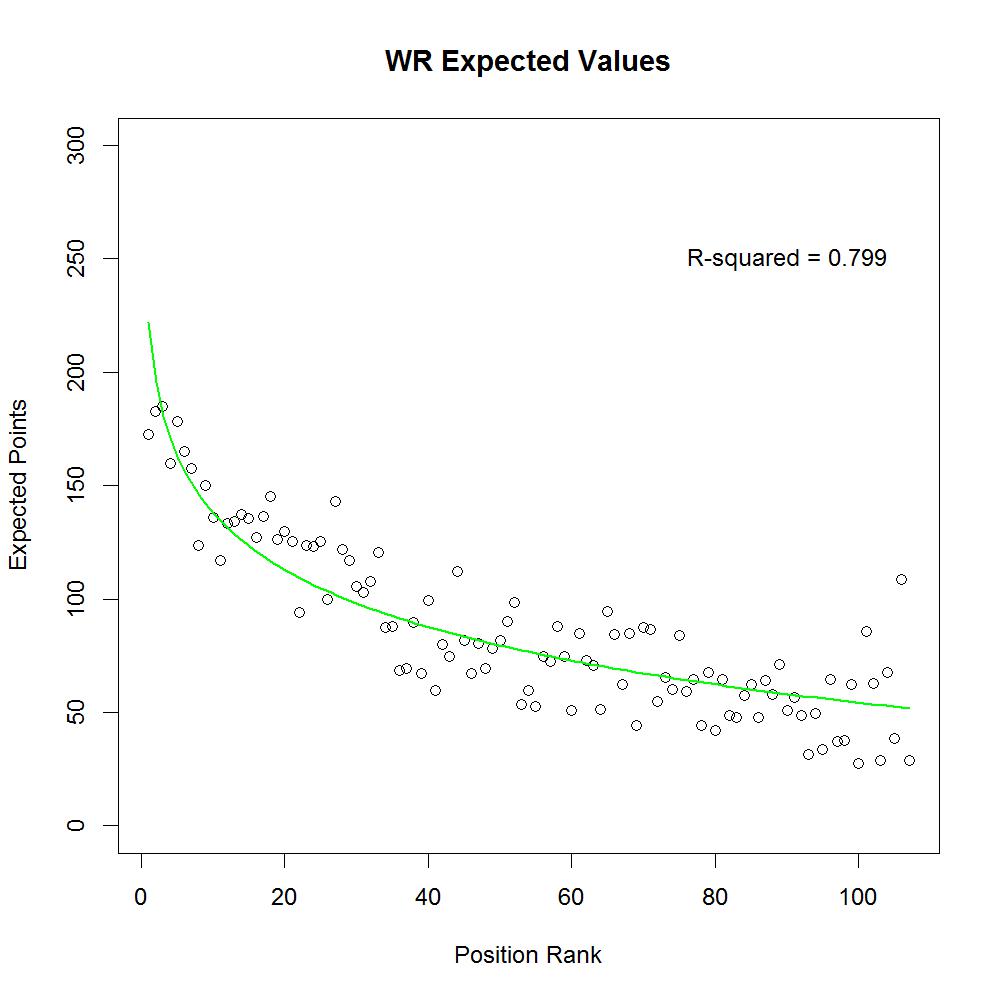



Running backs, wide receivers and tight ends have the greatest loss in value after the early picks. Also, quarterbacks, running backs, wide receivers and tight ends were much more predictable (R-squared values around .80) than kickers and defenses (R-squared values around .50).

This plot of expected fantasy points by position and position rank shows several patterns. First, some positions show dramatic decreases in expected value after just a few picks, including running backs, wide receivers, and tight ends. Because of their steep early decreases in expected value and high predictability, I recommend drafting RBs, WRs, and TEs with your earliest picks. Quarterbacks, on the other hand, show relatively stable (linear) decreases with a fairly steep slope. Because the dropoff is consistent, you are generally safer to wait to draft QBs after the earliest RBs, WRs, and TEs are off the board. Other positions, such as kickers and defense, show relatively flat levels of expected value. Because kickers and defenses are also highly unpredictable, you would generally be better off drafting them last.
Conclusion
In conclusion, based on historical data from 1999 to 2012:
- QBs, RBs, WRs, and TEs are fairly predictable in terms of fantasy points
- Kickers and Defenses are fairly unpredictable in terms of fantasy points
- RBs, WRs, and TEs show steep early decreases in expected value after the first picks
- QBs show stable decreases in expected value
- Kickers and Defenses show flat levels of expected value
Here are my suggestions based on these findings:
- Spend your first picks on RBs, WRs, and TEs (they are fairly predictable, and their values decrease exponentially after the best ones are off the board).
- After drafting RBs, WRs, and TEs, draft a QB. QBs are fairly predictable, and their values don’t decrease as fast RBs, WRs, and TEs, so you can still get a fairly solid QB after the top QBs are off the board.
- Wait until drafting RBs, WRs, TEs, and QBs before drafting Kickers and Defenses because they are unpredictable and lower ranked Ks and Ds only show small decreases in expected value.
To leave a comment for the author, please follow the link and comment on their blog: Fantasy Football Analytics in R.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.