
Online portfolio allocation with a very simple algorithm
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
By Yuri Resende
Today we will use an online convex optimization technique to build a very simple algorithm for portfolio allocation. Of course this is just an illustrative post and we are going to make some simplifying assumptions. The objective is to point out an interesting direction to approach the problem of portfolio allocation.
The algorithm used here is the Online Gradient Descendent (OGD) and we are going to compare the performance of the portfolio with the Uniform Constant Rebalanced Portfolio and the Dow Jones Industrial Average index. You can skip directly to Implementation and Example if you already know what an online algorithm is.
For those who don’t know what Online Convex Optimization is…
From now on, we will say that 


![p_t = [0.25, 0.25, 0.5]^\prime](https://s0.wp.com/latex.php?latex=p_t+%3D+%5B0.25%2C+0.25%2C+0.5%5D%5E%5Cprime&bg=ffffff&%23038;fg=333333&%23038;s=0 "p_t = [0.25, 0.25, 0.5]^\prime")


Online Convex Optimization is based on the idea of minimizing the so-called Regret function, which is basically an idea of how far from a good player you are (some kind of optimal player that you want to be). In the set-up of portfolio management, the Regret function is defined as:
-\sum_{i=1}^tlog(p_ir_i)")
The first part on the right hand side is the cumulative log return of the portfolio 


The OGD algorithm is quite simple, we are going to update our position every week based on the gradient of the 
- First play
- For

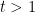

")
 = arg\min_{x \in S_n} (x - q)^\prime(x-q)")
This algorithm is proved to have ")

Implementation and Example
In our set-up the set of possible portfolios will not allow us to borrow money or short selling stocks, so every position should be bigger then zero and the sum of all positions should be one. This set is called simplex and define polytope. Basically it’s a triangle in higher dimension.
library(quantmod)
symbols <- c('MMM', 'AXP', 'AAPL', 'BA', 'CAT', 'CVX', 'CSCO', 'KO', 'DIS', 'DD', 'XOM', 'GE',
'GS', 'HD', 'IBM', 'INTC', 'JNJ', 'JPM', 'MCD', 'MRK', 'MSFT', 'NKE', 'PFE', 'PG',
'TRV', 'UTX', 'UNH', 'VZ', 'V', 'WMT')
for (i in 1:length(symbols)) getSymbols(symbols[i], from = '2007-01-03', to = '2017-06-21')
# Building weekly returns for each of the stocks
data <-sapply(symbols, function(x) Ad(to.weekly(get(x))))
data <- Reduce(cbind, data)
data_returns <- apply(data, 2, function(x) diff(log(x))) #log returns
colnames(data_returns) <- symbols
data_returns[is.na(data_returns)] <- 0 # VISA hasnt negotiations between 2007 and 2008
The OGD algorithm is implemented next. It uses the quadprogXT package to solve the projection onto the viable set. We are going to test two different values for 
library(quadprogXT)
OGD <- function(base, eta) {
# Gradient of Regret Function
gradient = function(b, p, r) b + r/(p%*%r)
# Projection onto viable Set
proj = function(p) {
Dmat = diag(length(p))
Amat = cbind(diag(rep(1, length(p))), -1)
bvec = c(rep(0, length(p)), -1)
fit = solveQPXT(Dmat = Dmat, dvec = p, Amat = Amat, bvec = bvec)
return(fit$solution)
}
T = nrow(base)
N = ncol(base)
r = as.matrix(base) + 1 # this is because the algo doesnt work directly with log returns
p = matrix(0, nrow = N, ncol = T); p[,1] = 1/N # initial portfolio
b = matrix(0, nrow = N, ncol = T); b[,1] = 0
for (i in 2:T) {
b[,i] = gradient(b[,i-1], p[,i-1], r[i-1,]) # calculating gradient
p.aux = p[,i-1] + eta*b[,i] # what we would like to play
p[,i] = proj(p.aux) # projection in the viable set
}
return(list('portfolio' = p,'gradient' = b))
}
# testing two etas
portfolio1 <- OGD(base = data_returns, eta = 1/100)
portfolio2 <- OGD(base = data_returns, eta = 1/1000)
Lets build a small function to calculate the compound return of portfolios taking their log return as input.
compound_return <- function(portfolio, r) {
return_OGD <- c(); return_OGD[1] = portfolio$portfolio[,1]%*%r[1,]
portfolio_value <- c(); portfolio_value[1] = 1 + portfolio$portfolio[,1]%*%r[1,]
for (i in 2:nrow(r)) {
return_OGD[i] = portfolio$portfolio[,i]%*%r[i,]
portfolio_value[i] = portfolio_value[i-1]*(1 + return_OGD[i])
}
return(list('value' = portfolio_value, 'return' = return_OGD))
}
Now let’s check the performance of the OGD algorithm with both 

# Dow Jones
getSymbols('^DJI', src = 'yahoo', from = '2007-01-03', to = '2017-06-21')
## [1] "DJI"
DJIA_returns = as.numeric(cumprod(weeklyReturn(DJI) + 1))
# Individual stocks
stocks_returns = apply(data_returns + 1, 2, cumprod)
# Our portfolios
portfolio_value1 <- compound_return(portfolio1, data_returns)
portfolio_value2 <- compound_return(portfolio2, data_returns)
In the figures below we can see the performance of the strategies that were implemented. Both portfolios had a surprisingly perform, much better than DJIA and UCRP portfolio.


Indeed, if

## <ScaleContinuousPosition> ## Range: ## Limits: 0 -- 1

To finish the comparison between our portfolios and DJIA, lets do a very simple risk analysis with just empirical quantiles using historical results. For a proper risk analysis we should model the conditional volatility of the portfolio, but this will be discussed in another post.
risk_analysis <- function(return) {
report = matrix(0, ncol = 2, nrow = 2)
report[1,] = quantile(return, probs = c(0.01, 0.05))
report[2,] = c(mean(return[which(return <= report[1,1])]), mean(return[which(return <= report[1,2])]))
rownames(report) = c('VaR', 'CVaR')
colnames(report) = c('1%', '5%')
return(round(report, 3))
}
report1 <- risk_analysis(portfolio_value1$return)
report2 <- risk_analysis(portfolio_value2$return)
report_DJIA <- risk_analysis(weeklyReturn(DJI))
| 1% | 5% | |
|---|---|---|
| VaR | -0.091 | -0.047 |
| CVaR | -0.119 | -0.074 |
| 1% | 5% | |
|---|---|---|
| VaR | -0.057 | -0.039 |
| CVaR | -0.085 | -0.055 |
| 1% | 5% | |
|---|---|---|
| VaR | -0.060 | -0.040 |
| CVaR | -0.084 | -0.055 |
It’s quite evident that setting a big
References
Agarwal, Amit, et al. “Algorithms for portfolio management based on the newton method.” Proceedings of the 23rd international conference on Machine learning. ACM, 2006.

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.