
Nonnegative Matrix Factorization and Recommendor Systems
[This article was first published on Econometric Sense, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Albert Au Yeung provides a very nice tutorial on non-negative matrix factorization and an implementation in python. This is based very loosely on his approach. Suppose we have the following matrix of users and ratings on movies:

If we use the information above to form a matrix R it can be decomposed into two matrices W and H such that R~ WH'
where R is an n x p matrix of users and ratings
W = n x r user feature matrix
H = r x p movie feature matrix
Similar to principle components analysis, the columns in W can be interpreted to represent latent user features while the columns in H’ can be interpreted as latent movie features. This factorization allows us to classify or cluster user types and movie types based on these latent factors.
For example, using the nmf function in R, we can decompose the matrix R above and obtain the following column vectors from H.
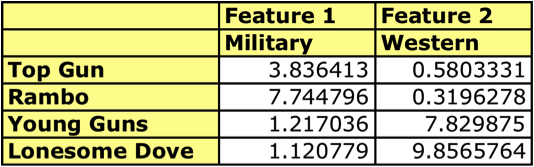
We can see that the first column vector ‘loads’ heavily on ‘military’ movies while the second feature more heavily ‘loads’ onto the ‘western’ themed movies. These vectors form a ‘feature space’ for movie types. Each movie can be visualized in this space as being a member of a cluster associated with its respective latent feature.

If a new user gives a high recommendation to a movie belonging to one of the clusters created by the matrix factorization, other movies belonging to the same cluster can be recommended.
References:
Yehuda Koren, Yahoo Research Robert Bell and Chris Volinsky, AT&T Labs—Research
IEEE Computer Society 2009
Matrix Factorisation: A Simple Tutorial and Implementation in Python
Albert Au Yeung http://www.albertauyeung.com/mf.php
R Code:
# ------------------------------------------------------------------
# | PROGRAM NAME: R nmf example
# | DATE: 10/20/12
# | CREATED BY: MATT BOGARD
# | PROJECT FILE: /Users/wkuuser/Desktop/Briefcase/R Programs
# |----------------------------------------------------------------
# | PURPOSE: very basic example of a recommendor system based on
# | non-negative matrix factorization
# |
# |
# |------------------------------------------------------------------
library(NMF)
# X ~ WH'
# X is an n x p matrix
# W = n x r user feature matrix
# H = r x p movie feature matrix
# get ratings for 5 users on 4 movies
x1 <- c(5,4,1,1)
x2 <- c(4,5,1,1)
x3 <- c(1,1,5,5)
x4 <- c(1,1,4,5)
x5 <- c(1,1,5,4)
R <- as.matrix(rbind(x1,x2,x3,x4,x5)) # n = 5 rows p = 4 columns
set.seed(12345)
res <- nmf(R, 4,"lee") # lee & seung method
V.hat <- fitted(res)
print(V.hat) # estimated target matrix
w <- basis(res) # W user feature matrix matrix
dim(w) # n x r (n= 5 r = 4)
print(w)
h <- coef(res) # H movie feature matrix
dim(h) # r x p (r = 4 p = 4)
print(h)
# recommendor system via clustering based on vectors in H
movies <- data.frame(t(h))
features <- cbind(movies$X1,movies$X2)
plot(features)
title("Movie Feature Plot")
To leave a comment for the author, please follow the link and comment on their blog: Econometric Sense.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.