
Non gaussian time-series, let’s handle it with score driven models!
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
By Henrique Helfer
Motivation
Until very recently, only a very limited classes of feasible non Gaussian time series models were available. For example, one could use extensions of state space models to non Gaussian environments (see, for example, Durbin and Koopman (2012)), but extensive Monte Carlo simulation is required to numerically evaluate the conditional densities that define the estimation process of such models.
The high technicalities involved in implementing these algorithms and its accompanying computational cost have not helped its widespread use by practitioners. On the other hand, different attempts to extend ARMA type models with conditional non Gaussian distributions have been more successful. For example, the use of GARCH type models to deal with heavy tailed distributions in finance (Engle and Bollerslev (1986)), the Autoregressive Conditional Duration (ACD) model of Engle and Russell (1998) to tackle asymmetric distributions in time duration and the Poisson count models of Davis et al (2003) for the modelling of discrete events in time. But, so far, these extensions have lacked an unifying framework that would allow the specification, estimation and forecasting of a model based on an arbitrary non Gaussian distribution. The recently proposed Generalized Autoregressive Scores (GAS) models by Creal et al (2008, 2013), or dynamic conditional score (DCS) from Harvey (2013), offer an unifying framework to derive and estimate time series model with any conditional non-Gaussian distribution, either discrete or continuous, univariate or multivariate. More specifically, in GAS models, conditional on past observations, a proper probability model, possibly non Gaussian, is chosen for the response variable at time 
Of course, in this post I will briefly explain the estimation framework of such models for our community, however I deeply encourage you our fellow “insighteR” to pay a visit to gasmodel.com, where you can find a whole section devoted to GAS models papers and see for yourself the diversity of applications.
Score driven models
First of all, one should choose an specific distribution which support accommodates the range of values assumed by the time series of interest 
")
where 



Next, to fully specify a GAS model, one has to choose which parameters of the distribution will evolve in time and those that will be fixed. The time varying parameters will then follow a GAS(p,q) updating mechanism given by:

where  \in \theta")
To complete the description of the the updating mechanism of GAS models it is necessary to define the score 

}{\partial f_{t}}")
![\displaystyle\mathcal{I}_{t|t-1} = E_{t|t-1}[\nabla_{t}^T\nabla_{t}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cmathcal%7BI%7D_%7Bt%7Ct-1%7D+%3D+E_%7Bt%7Ct-1%7D%5B%5Cnabla_%7Bt%7D%5ET%5Cnabla_%7Bt%7D%5D+&bg=ffffff&%23038;fg=333333&%23038;s=0 "\displaystyle\mathcal{I}_{t|t-1} = E_{t|t-1}[\nabla_{t}^T\nabla_{t}]")
where ")





Parametrization
If we assume for instance the intensity of a poisson density,
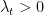

^{-1}\nabla_{t}")
Application
To elucidate a potential application, in this section we will generate and model a cont time series using GAS framework. More specifically, we will adopt a poisson density with its intensity parameter ")
 \times \lambda_t")
First of all, let’s create a function which simulates a cont time series from a poisson model with its intensity parameter 
##################################
#### GENERATING DGP
##################################
A = 0.101
B = -0.395
w = 0.183
GAS_POISSON_GENERATE = function (w,A,B,size){
y = f = s = NULL
###############################################
# Initial conditions for the recursion:
###############################################
t=1
f[1] = 1
y[1] = rpois(1,f[1])
###############################################
# GAS mechanism:
###############################################
for (t in 1:size){
s[t] = (y[t]-exp(f[t]))*(exp(f[t]))
f[t+1] = w + A * s[t] + B * f[t]
y[t+1] = rpois(1,exp(f[t+1]))
}
return(list("y"=y,"f"=f))
}
In the sequel, one can simulate the values of a cont time-series using the previous function. For instance, let us simulate a time series of size 1000 with 


set.seed(201930) serie.sim = GAS_POISSON_GENERATE(w,A,B,1000) par(mfrow=c(2,1)) ts.plot(serie.sim$y,ylab = "y") ts.plot(exp(serie.sim$f),ylab = "lambda")

To estimate the values of
##################################
#### ESTIMATING ML
##################################
GAS_POISSON = function (q, y=y){
A = q[1]
B = q[2]
w = q[3]
#####
n = length(y)
s = NULL
f = NULL
#####
f[1] = 0
for (t in 1 : n){
s[t] = (y[t]-exp(f[t]))*(exp(f[t]))
f[t+1] = w + A * s[t] + B * f[t]
}
# Here we have the loglikelihood.
sum = 0
for (t in 2:length(y)){
sum = sum + dpois(y[t], lambda = exp(f[t]), log = TRUE)
}
return(sum/n)
}
With the Maximum likelihood function in hands, we can do the parameter optimization, using as initial condition for the parameters in
f = NULL; s= NULL y = serie.sim$y set.seed(8456) result = optim(runif(3,0,0.1), y=y,GAS_POISSON , method="BFGS", hessian=TRUE, control=list(fnscale=-1)) param = result$par
The standard errors can be calculated using the Hessian inverse evaluated at the optimum point, i.e., under some mild conditions, the maximum likelihood estimator 
 \overset{d}{\to} N(0,H^{-1})")
hessian = -solve(as.matrix((length(y))*result$hessian))
inv.hessian = hessian
stderrors = array(0,length(param))
for (t in 1:length(param)){stderrors[t] = sqrt(hessian[t,t])}
estim = cbind(param,stderrors)
estim
## param stderrors
## [1,] 0.07543154 0.01999293
## [2,] -0.56880833 0.11422324
## [3,] 0.20280978 0.05132407
Regarding the forecasting, similar to GARH models, the 

")


GAS_POISSON_CALCULATE = function (par,y){
A = par[1] ; B = par[2] ; w=par[3]
f = s = NULL
f[1] = 0
n = length(y)
#####
for (t in 1 : n){
s[t] = (y[t]-exp(f[t]))*(exp(f[t]))
f[t+1] = w + A * s[t] + B * f[t]
}
#####
return(list("y"=y,"f"=f))
}
# Here we save the time varying parameter series
model.values = GAS_POISSON_CALCULATE(result$par,y)
Now we can use the last point of 
GAS_POISSON_FORECATING = function(f.mod,steps.ahead,par){
f = f.mod[length(f.mod)]
##################################################
n.sim=2000 # Number of Monte Carlo Simulations
dens.pred = matrix(NA,steps.ahead,n.sim) # Matrix of simulated values with dimension steps ahead x MC simulations
f.prev = NULL # simulated series of time-varying parameter f for each MC
s.prev = NULL # simulated series of score s
# Estimated parameters from theta
A = par[1] ; B = par[2] ; w=par[3]
##################################################
for(j in 1:n.sim){
#f.prev[1] = f[length(y)+1]
f.prev[1] = f
for (t in 1:steps.ahead){
dens.pred[t,j] = rpois(1, lambda = exp(f.prev[t])) # generate a random poisson value with intensity parameter modeled by GAS
s.prev[t] = (dens.pred[t,j]-exp(f.prev[t]))*(exp(f.prev[t])) # calculate the score
f.prev[t+1] = w + A*s.prev[t] + B*f.prev[t] # update lambda
}
f.prev = NULL
s.prev = NULL
}
##################################################
# Here we calculate the expected value of the predictive density and calculate the confidence intervals
forecasting = NULL
CI.sup = NULL
CI.inf = NULL
for(i in 1:steps.ahead){
forecasting[i]=mean(dens.pred[i,])
CI.sup[i] = quantile(dens.pred[i,],probs=0.975)
CI.inf[i] = quantile(dens.pred[i,],probs=0.025)
}
return(list("forecasting"=forecasting,"CI.sup" = CI.sup, "CI.inf" = CI.inf))
}
With the forecasting function already defined, one should only use as input the last value of the series
forecast = GAS_POISSON_FORECATING(model.values$f,5,result$par)
final.pred = cbind(forecast$forecasting,forecast$CI.sup,forecast$CI.inf)
colnames(final.pred) = c("Mean", "UB", "LB")
print(final.pred)
## Mean UB LB
## [1,] 1.0320 3 0
## [2,] 1.2320 4 0
## [3,] 1.1270 4 0
## [4,] 1.1615 4 0
## [5,] 1.1125 3 0
References
Creal, D., Koopman, S. J., & Lucas, A. (2008). A general framework for observation driven time-varying parameter models, Tinbergen Institute,Tech. Rep.
Creal, D., Koopman, S. J., & Lucas, A. (2013). Generalized autoregressive score models with applications. Journal of Applied Econometrics, 28(5), 777-795.
Davis, R. A., Dunsmuir, W. T., & Streett, S. B. (2003). Observation-driven models for Poisson counts. Biometrika, 777-790.
Durbin, J., & Koopman, S. J. (2012). Time series analysis by state space methods (Vol. 38). OUP Oxford.
Engle, R. F., & Bollerslev, T. (1986). Modelling the persistence of conditional variances. Econometric reviews, 5(1), 1-50.
Engle, R. F., & Russell, J. R. (1998). Autoregressive conditional duration: a new model for irregularly spaced transaction data. Econometrica, 1127-1162.
Harvey, A. C. (2013). Dynamic models for volatility and heavy tails: with applications to financial and economic time series (Vol. 52). Cambridge University Press.

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.