
maximal spacing around order statistics
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
 The riddle from the Riddler for the coming weeks is extremely simple to express in mathematical terms, as it summarises into characterising the distribution of
The riddle from the Riddler for the coming weeks is extremely simple to express in mathematical terms, as it summarises into characterising the distribution of

when the n-sample is made of iid Normal variates. I however had a hard time finding a result connected with this quantity since most available characterisations are for either Uniform or Exponential variates. I eventually found a 2017 arXival by Nagaraya et al. covering the issue. Since the Normal distribution belongs to the Gumbel domain of attraction, the extreme spacings, that is the spacings between the most extreme orders statistics [rescaled by nφ(Φ⁻¹{1-n⁻¹})] are asymptotically independent and asymptotically distributed as (Theorem 5, p.15, after correcting a typo):
")
where the ξ’s are Exp(1) variates. A crude approximation is thus to consider that the above Δ is distributed as the maximum of two standard and independent exponential distributions, modulo the rescaling by nφ(Φ⁻¹{1-n⁻¹})… But a more adequate result was pointed out to me by Gérard Biau, namely a 1986 Annals of Probability paper by Paul Deheuvels, my former head at ISUP, Université Pierre and Marie Curie. In this paper, Paul Deheuvels establishes that the largest spacing in a normal sample, M¹, satisfies
 \to \prod_{i=1}^{\infty} (1-e^{-ix})^2")
from which a conservative upper bound on the value of n required for a given bound x⁰ can be derived. The simulation below compares the limiting cdf (in red) with the empirical cdf of the above Δ based on 10⁴ samples of size n=10³.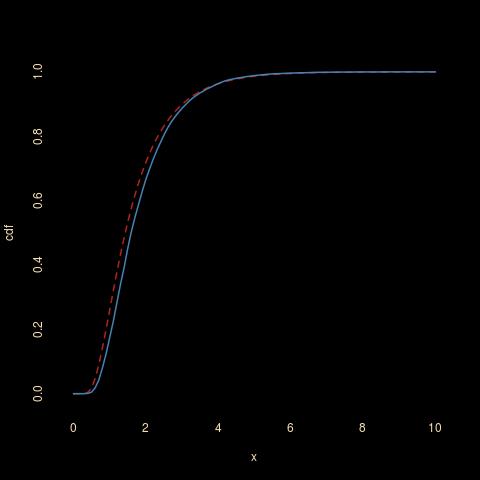 The limiting cdf is the cdf of the maximum of an infinite sequence of independent exponentials with scales 1,½,…. Which connects with the above result, in fine. For a practical application, the 99% quantile of this distribution is 4.71. To achieve a maximum spacing of, say 0.1, with probability 0.99, one would need 2 log(n) > 5.29²/0.1², i.e., log(n)>1402, which is a pretty large number…
The limiting cdf is the cdf of the maximum of an infinite sequence of independent exponentials with scales 1,½,…. Which connects with the above result, in fine. For a practical application, the 99% quantile of this distribution is 4.71. To achieve a maximum spacing of, say 0.1, with probability 0.99, one would need 2 log(n) > 5.29²/0.1², i.e., log(n)>1402, which is a pretty large number…
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.