
Integrating R with production systems using an HTTP API
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
by Nick Elprin, Co-Founder of Domino Data Lab
We built a platform that lets analysts deploy R code to an HTTP server with one click, and we describe it in detail below. If you have ever wanted to invoke your R model with a simple HTTP call, without dealing with any infrastructure setup or asking for help from developers — imagine Heroku for your R code — we hope you’ll enjoy this.
Introduction
Across industries, analytical models are powering core business processes and applications as more companies realize that that analytics are key to their competitiveness. R is particularly well suited to developing and expressing such models, but unfortunately, the final step of integrating R code into existing software systems remains difficult. This post describes our solution to this problem: “one-click” publishing of R code to an API server, allowing easy integration between R and other languages, and freeing data scientists to change their models on their own, without help from any developers or engineers.
Today, two problems — one technical, and one organizational — create friction when trying to integrate R code into existing software applications. First, while R is a great language for analytical code, most enterprise software systems are written in more general purpose languages, such as Java, PHP, C#, C++, or even data pipeline tools such as Informatica or Microsoft’s SSIS. Invoking R code from these languages requires some non-trivial technical work, or translation to another language. This leads to the second problem: in most companies, software engineering teams are separate from analytics teams, so when analysts need engineering help, they are forced to compete against other priorities, or they must do their own engineering. Even after an initial deployment of R code, when the model is updated, the deployment process must be repeated, resulting in a painful iteration cycle.
A Solution: Domino and API Endpoints
Domino is a platform for doing data science in the enterprise: it provides turnkey functionality for job distribution, version control, collaboration, and model deployment, so that data science teams can be productive without their own engineers and developers. We built our “API Endpoints” feature to address the use case I describe above, reducing the friction associated with integrating R (or Python) models into production systems. Here’s how it works:
Let’s say we are building a library for arithmetic. We have a file, arithmetic.R, with this code:
add <- function(a, b) {
a + b
}
multiply <- function(a, b) {
a * b
}
Now we’d like to make that code accessible to external applications. You can upload this file to Domino (via our web interface, command-line client, or our R package). Once uploaded, you can define a new “API Endpoint” by specifying this file, and the name of the function to invoke when the API is used.
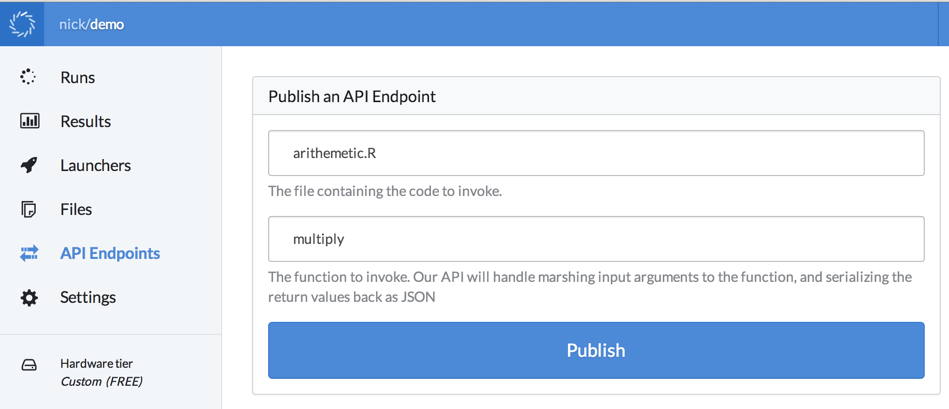
When we hit “publish,” Domino deploys the script to a low-latency server and listens for incoming HTTP requests. If your script performs any one-time initialization (for example, installing custom R packages, or calculating any model parameters), it would run once upon publishing. When a request comes in, Domino passes the request parameters to your specified R function, and returns the results.
It’s that simple. We can test this with a simple curl command (or the equivalent operation in any modern programming language)
curl -v -X POST http://rt.dominoup.com:9000/v1/nick/demo/rt
-H “Content-Type:application/json”
-d '{“parameters”: [10,20] }'
Our two parameters (10, 20) are the inputs to the function. Domino pulls them out of the incoming HTTP request, passes them to the R function, and marshals the “result” value back in the HTTP response, along with some status info:
< HTTP/1.1 200 OK
< Content-Type: text/plain; charset=utf-8
< Content-Length: 70
<
* Connection #0 to host rt.dominoup.com left intact
{“runId”:”53d3c2986fe0206fee536283″,”status”:”Succeeded”,”result”:200}
This technique works for more complex return types, as well, including strings and arrays of multiple values.
Now our R code accessible via an HTTP call, providing a clean interface to any other system or language. Moreover, analysts can deploy updates to the R code on their own, enabling a faster iteration cycle.

Training Steps with Scheduled Runs
A common workflow in machine learning tasks is to create a training task, which might take hours to run, and a classify step, which uses the output of the training step to classify inputs very quickly. Domino let’s you schedule recurring tasks, which can automatically publish their results to an API Endpoint you have defined. In this example, we have a “training_task.R” script that runs a computationally intensive regression and saves the resulting parameters to an RData file.

We can then create a classify function (and API Endpoint) which reads in our parameters and quickly classifies incoming requests. Because our scheduled tasks is set to update the API Endpoint upon completion, the API will get the latest training parameters each night when the training script runs.
Change Management: Production vs Development
Once your R code is consumed by production processes, it’s critical to be careful when changing it. Domino facilitates this by automatically keeping a revisioned history of all your files, and by keeping your API Endpoints “pinned” to specific revisions of your code until you explicitly update it. As an example, this screenshot shows Domino’s view of the history of our API releases. We could edit our R files all we want, but the most recent API release (v8) would remain pointed to the exact version of the code we had when we published it. And if we ever needed to debug a production issue from a past release, we could go back to the exact version of our code associated with earlier releases simply by clicking the “commit” link.

Implementation
Domino actually lets you publish R or Python code as an API Endpoint, but since this is an R blog, I will focus on how we have implemented this for R code. Our API functionality is driven by two powerful tools under the hood:
- Rserve, along with its Java client, lets us programmatically control an in-memory R session.
- Docker lets us isolate users’ code in separate containers, so they cannot interfere with each other or with our host machines.
With these tools, the implementation of our API functionality works roughly like this:
When we “publish” a new endpoint, we get a source_file and a function_name from the user. Then we:
- Create a new Docker container
- Write a conf file telling Rserve to source the source_file script
- In the container, start an Rserve session and tell it to use the conf file we just created
To start Rserve, we invoke R from the command line (e.g., R –no-save –no-environ) and pass it the following STDIN content:
library(Rserve)
Rserve(debug=TRUE,port=$rservePort,'–vanilla –RS-conf $conf_file')
Where $conf_file is the path to a file containing:
remote enable
source $source_file
By deploying the script and running any initialization when the user hits “publish,” we minimize the work necessary each time the API is invoked. In fact, the overhead of an API request to this published endpoint is only about 150ms. This is critical to support production applications with low latency requirements.
When an HTTP request comes in, we can then do the following:
- Lookup the Docker container that corresponds to the requested endpoint
- Build a command_string from the function_name corresponding to the requested endpoint, and the POST parameters from the HTTP request. E.g., “multiply(10, 20)”
- Invoke the Rserve API to execute this command in the process running inside the specific Docker contain. In Scala, this is how that looks:
import org.rosuda.REngine.REXP
import org.rosuda.REngine.Rserve.RConnection
val c = new RConnection(null, 9999) // second parameter is the port
try {
new RResult(c.eval(command_string))
} finally {
c.close()
}
RConnection.eval() returns an REXP object. Our helper class, RResult, knows how to translate this object into appropriate JSON, so that we can return it in our HTTP response:
class RResult(val rexp: REXP) {
def toJson = {
if (rexp.isString) {
Json.toJson(rexp.asString)
} else if (rexp.isVector && rexp.length > 1) {
Json.toJson(rexp.asDoubles())
} else if (rexp.isList) {
val list = rexp.asList
if (list.isNamed) {
JsObject(
for {
key <- list.keys
} yield {
key -> Json.toJson(new RResult(list.at(key)))
}
)
} else {
JsArray(
for {
i <- 0 to list.capacity
} yield {
Json.toJson(new RResult(list.at(i)))
}
)
}
} else if (rexp.isNumeric) {
JsNumber(rexp.asDouble)
} else {
JsString(rexp.asNativeJavaObject.toString)
}
}
}
Conclusion
We are excited to see more organizations making analytical models a central part of their business processes, and we hope that Domino can empower data scientists to accelerate this trend. We are always eager for feedback, so please check our free trial, including API Endpoints, and let us know what you think at [email protected] or on Twitter at @dominodatalab.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.